Configuring Anchore
Configuring Anchore Enterprise starts with configuring each of the core services. Anchore Enterprise deployments using docker compose for trials or Helm for production are designed to run by default with no modifications necessary to get started. Although, many options are available to tune your production deployment to fit your needs.
About Configuring Anchore Enterprise
All system services (except the UI, which has its own configuration) require a single configuration which is read from /config/config.yaml when each service starts up. Settings in this file are mostly related to static settings that are fundamental to the deployment of system services. They are most often updated when the system is being initially tuned for a deployment. They may, infrequently, need to be updated after they have been set as appropriate for any given deployment.
Sections of the UI configuration settings can now be found from within the UI itself! Navigate to the ‘System’ heading in the sidebar and then select ‘Configuration’. Here you will see some of the exposed configuration options:
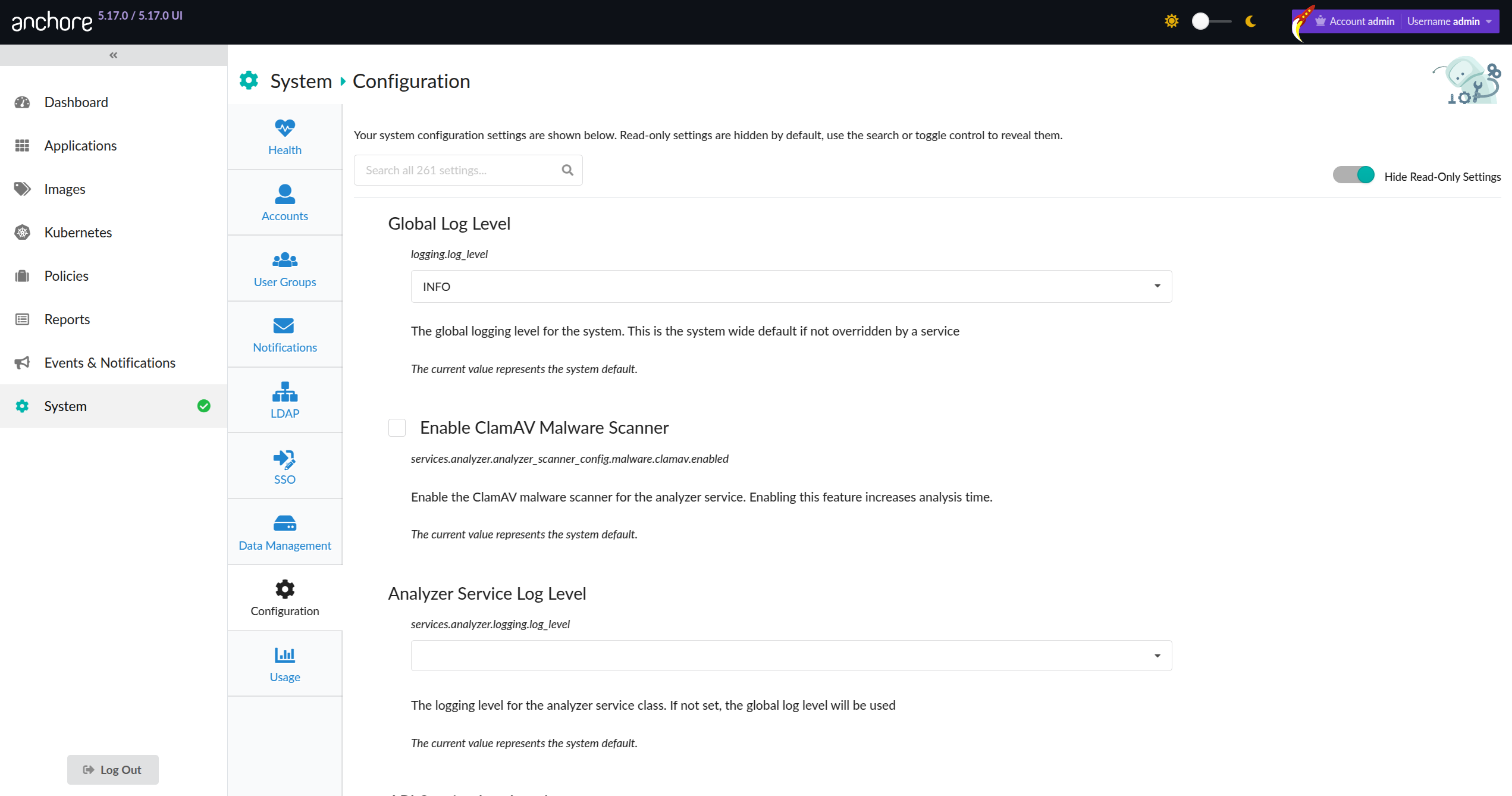
By default, Anchore Enterprise includes a config.yaml that is functional out-of-the-box, with some parameters set to an environment variable for common site-specific settings. These settings are then set either in docker-compose.yaml, by the Helm chart, or as appropriate for other orchestration/deployment tools.
When deploying Anchore Enterprise using the Helm chart, you can configure it by modifying the anchoreConfig section in your values file. This section corresponds to the default config.yaml file included in the Anchore Enterprise container image. The values file serves to override the default configurations and should be modified to suit your deployment.
1 - General Configuration
Initial Configuration
A single configuration file config.yaml is required to run Anchore - by default, this file is embedded in the Enterprise container image, located in /config/config.yaml. The default configuration file is provided as a way to get started, which is functional out of the box, without modification, when combined with either the Helm method or docker compose method of installing Enterprise. The default configuration is set up to use environment variable substitutions so that configuration values can be controlled by setting the corresponding environment variables at deployment time (see Using Environment Variables in Anchore.
Each environment variable (starting with ANCHORE_) in the default config.yaml is set (either the baseline as set in the Dockerfile, or an override in docker compose or Helm or through a system default) to ensure that the system comes up with a fully populated configuration.
Some examples of useful initial settings follow.
- Default admin credentials: A default admin email and password is required to be defined in the catalog service for the initial bootstrap of enterprise to succeed, which are both set through the default config file using the ANCHORE_ADMIN_PASSWORD and ANCHORE_ADMIN_EMAIL environment variables respectively. The system defines a default email admin@myanchore, but does not define a default password. If using the default config file, the user must set a value for ANCHORE_ADMIN_PASSWORD in order to succeed the initial bootstrap of the system. To set the default password or to override the default email, simply add overrides for ANCHORE_ADMIN_PASSWORD and ANCHORE_ADMIN_EMAIL environment variables, set to your preferred values prior to deploying Anchore Enterprise. After the initial bootstrap, this can be removed if desired.
default_admin_password: '${ANCHORE_ADMIN_PASSWORD}'
default_admin_email: '${ANCHORE_ADMIN_EMAIL}'
- Log level: Anchore Enterprise is configured to run at the INFO log level by default. The full set of options are CRITICAL, ERROR, WARNING, INFO, and DEBUG (in ascending order of log output verbosity). Admin accounts can set the system log level through the dashboard, the dashboard allows differing per-service log levels. Changes through the dashboard do not require a system restart. The log level can also be set globally (across all services) with an override for ANCHORE_LOG_LEVEL prior to deploying Anchore Enterprise, this approach requires a system restart to take effect.
log_level: '${ANCHORE_LOG_LEVEL}'
- Postgres Database: Anchore Enterprise requires access to a PostgreSQL database to operate. The database can be run as a container with a persistent volume or outside of your container environment (which is set up automatically if the example docker-compose.yaml is used). If you wish to use an external Postgres Database, the elements of the connection string in the config.yaml can be specified as environment variable overrides. The default configuration is set up to connect to a postgres DB that is deployed alongside Anchore Enterprise Services when using docker-compose or Helm, to the internal host anchore-db on port 5432 using username postgres with password mysecretpassword and db postgres. If an external database service is being used then you will need to provide the use, password, host, port and DB name environment variables, as shown below.
db_connect: 'postgresql://${ANCHORE_DB_USER}:${ANCHORE_DB_PASSWORD}@${ANCHORE_DB_HOST}:${ANCHORE_DB_PORT}/${ANCHORE_DB_NAME}'
Manual Configuration File Override
While Anchore Enterprise is set up to run out of the box without modifications, and many useful values can be overriden using environment variables as described above, one can always opt to have full control over the configuration by providing a config.yaml file explicitly, typically by generating the file and making it available from an external mount/configmap/etc. at deployment time. A good method to start if you wish to provide your own config.yaml is to extract the default config.yaml from the Anchore Enterprise container image, modify it, and then override the embedded /config/config.yaml at deployment time. For example:
- Extract the default config file from the anchore/enterprise container image:
docker pull docker.io/anchore/enterprise:v5.X.X
docker create --name ae docker.io/anchore/enterprise:v5.X.X
docker cp ae:/config/config.yaml ./my_config.yaml
docker rm ae
Modify the configuration file to your liking.
Set up your deployment to override the embedded /config/config.yaml at run time (below example shows how to achieve this with docker compose). Edit the docker-compose.yaml to include a volume mount that mounts your my_config.yaml over the embedded /config/config.yaml, resulting in a volume section for each Anchore Enterprise service definition.
...
api:
...
volumes:
- /path/to/my_config.yaml:/config/config.yaml:z
...
catalog:
...
volumes:
- /path/to/my_config.yaml:/config/config.yaml:z
...
simpleq:
...
volumes:
- /path/to/my_config.yaml:/config/config.yaml:z
...
policy-engine:
...
volumes:
- /path/to/my_config.yaml:/config/config.yaml:z
...
analyzer:
...
volumes:
- /path/to/my_config.yaml:/config/config.yaml:z
...
Now, each service will come up with your external my_config.yaml mounted over the embedded /config/config.yaml.
1.1 - API Accessible Configuration
Anchore Enterprise provides the ability to view the majority of system configurations via the API.
A select number of configurations can also be modified through the API, or through the System Configuration tab from the UI.
This enables control of system behaviours and characteristics in a programmatic way without needing to restart your deployment.
Note
⚠️ At this time, only a few configurations are modifiable through this new API-backed mechanism yet. Full configuration continues to be achievable through the existing config file mechanism.Configuration Provenance
Configuration values are established by a priority system which derives the final running value based on the location from
which the value was read. This provenance priority mechanism enables backwards compatibility and increased security
for customers wishing tighter control of their systems runtime.
1. Config File Source
Any configuration variable which is declared within an on-disk configuration file will be honored first (ie. via a Helm values.yaml).
These configuration variables will be read-only through the API and UI. Any configuration that is currently set for your deployment
will be preserved.
Note
⚠️ The use of environment variables for configuration values are treated with the same provenance as config file.2. API Config Source
When a configuration variable is not declared in a config file and is one of the select few that are allowed to be modified via the API,
its value will be stored in the system database. These configuration variables can be modified via the API and the changes will be reflected
within the deployment within a short time without having to restart your deployment.
The following configuration variables are modifiable through the API:
services.analyzer.analyzer_scanner_config.malware.clamav.enabledlogging.log_levelservices.apiext.logging.log_levelservices.analyzer.logging.log_levelservices.catalog.logging.log_levelservices.policy_engine.logging.log_levelservices.policy_engine.vulnerabilities.extended_support.rhel.enabledservices.policy_engine.vulnerabilities.extended_support.rhel.versionsservices.simplequeue.logging.log_levelservices.notifications.logging.log_levelservices.data_syncer.logging.log_levelservices.reports.logging.log_levelservices.reports_worker.logging.log_level
3. Anchore Enterprise Defaults
If a configuration variable has not been declared by any other source it inherits the default system value. These are values chosen by Anchore
as safe and functional defaults.
For the majority of deployments we recommend you simply use the default settings for most values as they have been calibrated to
offer the best experience out of the box.
⚠️ Note: These values may change from release to release. Notable changes will be communicated through Release Notes. Significant
system behaviour changes will not be performed between minor releases. If you wish to ensure a default is not changed, “pin” the
value either by providing it explicitly in the config file or setting it directly via the API (when available).
Blocked by Config File
Attempts to set a configurations through the API may return a blocked_by_config_file error.
This error is raised when a configuration variable is not API editable as it is set in a config file.
Locations to inspect for a pinned config value are:
- the Helm attached
values.yaml file (continue reading for further instructions) - the compose attached config.yaml file
- the environment variables being passed into the container
Disabling Helm Chart Configs
For Helm users, to make a value configurable through the API, set the value in the attached values.yaml to "<ALLOW_API_CONFIGURATION>"
As an example:
services:
analyzer:
malware:
clamav:
enabled: "<ALLOW_API_CONFIGURATION>"
API Configurations Refresh
Each running container will refresh its internal configuration state approximately every 30 seconds. After making a change please allow
a minute to elapse for the changes to flush out to all running nodes.
Config File Configurations Refresh
Changes made to a mounted config file will be detected and will cause a system configuration refresh.
If a configuration variable that is changed requires a system restart a log message will be printed to that effect.
If a system is pending restart, none of the changes will take effect until
this is performed. This config file watcher includes a mounted .env file if in use.
Config Validation
In a future major release of Anchore Enterprise, we will be enabling a strict mode type and data validation for the configuration.
This will result in any non-compliant Enterprise deployments failing to boot. For now this is not enforced.
For awareness, validation of your configuration variables and values will occur during system boot.
If any configuration fails this validation, a log message mentioning lenient mode will be published.
This will be accompanied by details on which entries have failed.
To avoid system downtime in a future major release, consider resolving these issues today.
Secret Values
Secret values cannot be read through the API, they will return as the string <redacted> it is however possible to update them.
It is not possible to set any secret value to the string <redacted>.
Security Permissions
Config file permissions have not changed, they are editable by the system deployer.
API requests to make changes to configuration will only be accepted if coming from an Anchore User with system-admin permissions.
1.2 - Content Hints
For an overview of the content hints and overrides features, see the feature overview
Enabling Content Hints
This feature is disabled by default to ensure that images may not exercise this feature without the admin’s explicit approval. This page will explain how to enable content hints for both Docker Compose and Kubernetes (Helm) deployments. Additionally, if you are performing distributed analysis of images and require hints detection you will ALSO need to modify your AnchoreCTL configuration.
Hints cannot be used to modify the findings of Anchore Enterprise’s analyzer beyond adding new packages to the report. If a user specifies a package in the content hints file that is found by Anchore Enterprise’s image analyzers, the hint is ignored and a warning message is logged to notify the user of the conflict
🐳 Docker Compose
To configure your Docker Compose deployment and enable content hints you have two options.
If you supply a config.yaml to the analyzer(s) in your Docker Compose file, then set the enable_hints: true setting in the analyzer service section of config.yaml file.
If you don’t supply a config.yaml, you can add an environment variable ANCHORE_HINTS_ENABLED=true on the analyzer service.
This will also enable content hints detection during centralized analysis.
☸️ Kubernetes (Helm)
To configure your Kubernetes (Helm) deployment and enable content hints, you can update your values file and set anchoreConfig.analyzer.enable_hints: true. This will also enable content hints detection during centralized analysis.
anchoreConfig:
analyzer:
enable_hints: true
AnchoreCTL Distributed
In addition to enabling content hints in your deployment, you may also need to enable content hints detection for distributed analysis.
This can be achieved by editing your AnchoreCTL configuration, for example ~/anchorectl.yaml as shown below. This enables the file cataloger which will add some computational overhead.
---
file-contents:
cataloger:
enabled: true
scope: squashed
skip-files-above-size: 1048576
globs: ['/anchore_hints.json']
1.3 - Environment Variables
Environment variable references may be used in the Anchore config.yaml file to set values that need to be configurable during deployment.
Using this mechanism a common configuration file can be used with multiple Anchore instances with key values being passed using environment variables.
The config.yaml configuration file is read by Anchore and any references to variables prefixed with ANCHORE will be replaced by the value of the matching environment variable.
For example in the sample configuration file the host_id parameter is set be appending the ANCHORE_HOST_ID variable to the string dockerhostid
host_id: 'dockerhostid-${ANCHORE_HOST_ID}'
Notes:
- Only variables prefixed with ANCHORE will be replaced
- If an environment variable is referenced in the configuration file but not set in the environment then a warning will be logged
- It is recommend to use curly braces, for example ${ANCHORE_PARAM} to avoid potentially ambiguous cases
Passing Environment Variables as a File
Environment Variables may also be passed as a file contained key value pairs.
ANCHORE_HOST_ID=myservice1
ANCHORE_LOG_LEVEL=DEBUG
The system will check for an environment variable named ANCHORE_ENV_FILE if this variable is set then Anchore will attempt to read a file at the location specified in this variable.
The Anchore environment file is read before any other Anchore environment variables so any ANCHORE variables passed in the environment will override the values set in the environment file.
2 - Enterprise UI Configuration
The Enterprise UI service has some static configuration options that are read
from /config/config-ui.yaml inside the UI container image when the system
starts up.
The configuration is designed to not require any modification when using the
quickstart (docker compose) or production (Helm) methods of deploying Anchore
Enterprise. If modifications are desired, the options, their meanings, and
environment overrides are listed below for reference:
The (required) license_path key specifies the location of the local system
folder containing the license.yaml license file required by the Anchore
Enterprise UI web service for product activation. This value can be overridden
by using the ANCHORE_LICENSE_PATH environment variable.
The (required) enterprise_uri key specifies the address of the Anchore
Enterprise service. The value must be a string containing a properly-formed
‘http’ or ‘https’ URI. This value can be overridden by using the
ANCHORE_ENTERPRISE_URI environment variable.
enterprise_uri: 'http://api:8228/v2'
The (required) redis_uri key specifies the address of the Redis service. The
value must be a string containing a properly-formed redis URI such as
redis://ui-redis. If encryption in transit is in use with an external Redis the
connection string should be rediss:// instead of redis://. Note that the
default configuration uses the Redis Serialization Protocol (RESP). This
value can be overridden by using the ANCHORE_REDIS_URI environment variable.
redis_uri: 'redis://ui-redis:6379'
The (required) appdb_uri key specifies the location and credentials for the
postgres DB endpoint used by the UI. The value must contain the host, port, DB
user, DB password, and DB name. This value can be overridden by using the
ANCHORE_APPDB_URI environment variable.
appdb_uri: 'postgres://<db-user>:<db-pass>@<db-host>:<db-port>/<db-name>'
The (required) reports_uri key specifies the address of the Reports service.
The value must be a string containing a properly-formed ‘http’ or ‘https’ URI
and can be overridden by using the ANCHORE_REPORTS_URI environment variable.
Note that the presence of an uncommented reports_uri key in this file (even
if unset, or set with an invalid value) instructs the Anchore Enterprise UI
web service that the Reports feature must be enabled.
reports_uri: 'http://reports:8228/v2'
The (optional) enable_ssl key specifies if SSL operations should be enabled
within in the web app runtime. When this value is set to True, secure
cookies will be used with a SameSite value of None. The value must be a
Boolean, and defaults to False if unset.
Note: Only enable this property if your UI deployment configured to run
within an SSL-enabled environment (for example, behind a reverse proxy, in the
presence of signed certs etc.)
This value can be overridden by using the ANCHORE_ENABLE_SSL environment
variable.
The (optional) enable_proxy key specifies whether to trust a reverse proxy
when setting secure cookies (via the X-Forwarded-Proto header). The value
must be a Boolean, and defaults to False if unset. In addition, SSL must be
enabled for this to work. This value can be overridden by using the
ANCHORE_ENABLE_PROXY environment variable.
The (optional) allow_shared_login key specifies if a single set of user
credentials can be used to start multiple Anchore Enterprise UI sessions; for
example, by multiple users across different systems, or by a single user on a
single system across multiple browsers.
When set to False, only one session per credential is permitted at a time,
and logging in will invalidate any other sessions that are using the same set
of credentials. If this property is unset, or is set to anything other than a
Boolean, the web service will default to True.
Note that setting this property to False does not prevent a single session
from being viewed within multiple tabs inside the same browser. This value
can be overridden by using the ANCHORE_ALLOW_SHARED_LOGIN environment
variable.
The (optional) redis_flushdb key specifies if the Redis datastore containing
user session keys and data is emptied on application startup. If the datastore
is flushed, any users with active sessions will be required to
re-authenticate.
If this property is unset, or is set to anything other than a Boolean, the web
service will default to True. This value can be overridden by using the
ANCHORE_REDIS_FLUSHDB environment variable.
The (optional) custom_links key allows a list of up to 10 external links to
be provided (additional items will be excluded). The top-level title key
provided the label for the menu (if present, otherwise the string “Custom
External Links” will be used instead).
Each link entry must have a title of greater than 0-length and a valid URI. If
either item is invalid, the entry will be excluded.
custom_links:
title: Custom External Links
links:
- title: Example Link 1
uri: https://example.com
- title: Example Link 2
uri: https://example.com
- title: Example Link 3
uri: https://example.com
- title: Example Link 4
uri: https://example.com
- title: Example Link 5
uri: https://example.com
- title: Example Link 6
uri: https://example.com
- title: Example Link 7
uri: https://example.com
- title: Example Link 8
uri: https://example.com
- title: Example Link 9
uri: https://example.com
- title: Example Link 10
uri: https://example.com
The (optional) force_websocket key specifies if the WebSocket protocol must
be used for socket message communications. By default, long-polling is
initially used to establish the handshake between client and web service,
followed by a switch to WS if the WebSocket protocol is supported.
If this value is unset, or is set to anything other than a Boolean, the web
service will default to False.
This value can be overridden by using the ANCHORE_FORCE_WEBSOCKET
environment variable.
The (optional) authentication_lock keys specify if a user should be
temporarily prevented from logging in to an account after one or more failed
authentication attempts. For this feature to be enabled, both values must be
whole numbers greater than 0. They can be overridden by using the
ANCHORE_AUTHENTICATION_LOCK_COUNT and ANCHORE_AUTHENTICATION_LOCK_EXPIRES
environment variables.
The count value represents the number of failed authentication attempts
allowed to take place before a temporary lock is applied to the username. The
expires value represents, in seconds, how long the lock will be applied for.
Note that, for security reasons, when this feature is enabled it will be
applied to any submitted username, regardless of whether the user exists.
authentication_lock:
count: 5
expires: 300
The (optional) enable_add_repositories key specifies if repositories can be
added via the application interface by either administrative users or standard
users. In the absence of this key, the default is True. When enabled, this
property also suppresses the availability of the Watch Repository toggle
associated with any repository entries displayed in the Artifact Analysis
view.
Note that in the absence of one or all of the properties, the default is also
True. Thus, this key, and a child key corresponding to an account type (that
is itself explicitly set to False) must be set for the feature to be
disabled for that account.
enable_add_repositories:
admin: True
standard: True
The (optional) ldap_timeout and ldap_connect_timeout keys respectively
specify the time (in milliseconds) the LDAP client should let operations stay
alive before timing out, and the time (in milliseconds) the LDAP client should
wait before timing out on TCP connections. Each value must be a whole number
greater than 0.
When these values are unset (or set incorrectly) the app will fall back to
using a default value of 6000 milliseconds. The same default is used when
the keys are not enabled.
These value can be overridden by using the ANCHORE_LDAP_AUTH_TIMEOUT and
ANCHORE_LDAP_AUTH_CONNECT_TIMEOUT environment variables.
ldap_timeout: 6000
ldap_connect_timeout: 6000
The (optional) custom_message key allows you to provide a message that will
be displayed on the application login page below the Username and
Password fields. The key value must be an object that contains:
- A
title key, whose string value provides a title for the message—which can
be up to 100 characters - A
message key, whose string value is the message itself—which can be up to
500 characters
custom_message:
title:
"Title goes here..."
message:
"Message goes here..."
Note: Both title and message values must be present and contain at
least 1 character for the message box to be displayed. If either value
exceeds the character limit, the string will be truncated with an ellipsis.
The (optional) log_level key allows you to set the descriptive detail of the
application log output. The key value must be a string selected from the
following priority-ordered list:
Once set, each level will automatically include the output for any levels
above it—for example, info will include the log output for details at the
warn and error details, whereas error will only show error output.
This value can be overridden by using the ANCHORE_LOG_LEVEL environment
variable. When no level is set, either within this configuration file or by
the environment variable, a default level of http is used.
The (optional) enrich_inventory_view key allows you to set whether the
Kubernetes feature should aggregate and include compliance and
vulnerability data from the reports service. Setting this key to be False
can increase performance on high-volume systems.
This value can be overridden by using the ANCHORE_ENRICH_INVENTORY_VIEW
environment variable. When no flag is set, either within this configuration
file or by the environment variable, a default setting of True is used.
enrich_inventory_view: True
The (optional) enable_prometheus_metrics key enables exporting monitoring
metrics to Prometheus. The metrics are made available on the /metrics
endpoint.
This value can be overridden by using the ANCHORE_ENABLE_METRICS environment
variable. When no flag is set, either within this configuration file or by the
environment variable, a default setting of False is used.
enable_prometheus_metrics: False
The (optional) banners key allows you to provide messages that
will be displayed as a banner at the top and/or bottom of the application
or only the login page. You can set either or both banners. Each banner
is defined by a key that contains an object with the following properties:
text (string): The message to be displayed in the banner. This can be
up to 2000 characters long.text_color (string): The color of the text in the banner.background_color (string): The background color of the banner.display (string): The display condition for the banner. This can be set
to always or login-only. If not specified, the default is
always. The login-only option will only display the banner on the
login page.
banners:
top:
text: "Custom message for the top banner..."
text_color: ""
background_color: ""
display: "always"
bottom:
text: "Custom message for the bottom banner..."
text_color: ""
background_color: ""
display: "login-only"
Note:
- The
text and value must be present and contain at
least 1 character for the message box to be displayed. If the value
exceeds the character limit, the string will be truncated with an ellipsis
with the full text available to view on hover. - The
text_color and background_color values can be any
valid CSS color format, including hex codes (e.g., #FF5733),
RGB (e.g., rgb(255, 87, 51)), or color names (e.g., red).
Sections of the UI configuration settings can now be found from within the UI itself! Navigate to the ‘System’ heading in the sidebar and then select ‘Configuration’. Here you will see some of the exposed configuration options:

NOTE: The latest default UI configuration file can always be extracted from
the Enterprise UI container to review the latest options, environment overrides
and descriptions of each option using the following process:
docker login
docker pull docker.io/anchore/enterprise-ui:latest
docker create --name aui docker.io/anchore/enterprise-ui:latest
docker cp aui:/config/config-ui.yaml /tmp/my-config-ui.yaml
docker rm aui
cat /tmp/my-config-ui.yaml
...
...
2.1 - Using Dashboard
Overview
The Dashboard is your configurable landing page where insights into the collective status of your container image environment can be displayed through various widgets. Utilizing the Enterprise Reporting Service, the widgets are hydrated with metrics which are generated and updated on a cycle, the duration of which is determined by application configuration.
Note: Because the reporting data cycle is configurable, the results shown in this view may not precisely reflect actual analysis output at any given time.
For more information on how to modify this cycle or the Reporting Service in general, please refer to the Reporting Service.
The following sections in this document describe how to add widgets to the dashboard and how to customize the dashboard layout to your preference.


To add a new widget, click the Add New Widget button present in the Dashboard view. Or, if no widgets are defined, click the Let’s add one! button shown.

Upon doing so, a modal will appear with several properties described below:
| Property | Description |
|---|
| Name | The name shown within the Widget’s header. |
| Mode | ‘Compact’ a widget to keep data easily digestable at a glance. ‘Expand’ to view how your data has evolved over a configurable time period. |
| Collection | The collection of tags you’re interested in. Toggle to view metrics for all tags - including historical ones. |
| Time Series Settings | The time period you wish to view metrics for within the expanded mode. |
| Type | The category of information such as ‘Vulnerabilities’ or ‘Policy Evaluations’ which denotes what metrics are capable of being shown. |
| Metrics | The list of metrics available based on Type. |
Once you enter the required properties and click OK, the widget will be created and any metrics needed to hydrate your Dashboard will be fetched and updated.
Note: All fields except Type are editable by clicking the button shown on the top right of the header when hovering over a widget.
Viewing Results
The Reporting Service at its core aggregates data on resources across accounts and generates metrics. These metrics, in turn, fuel the Dashboard’s mission to provide actionable items straight to the user - that’s you!
Leverage these results to dive into the exact reason for a failed policy evaluation or the cause and fix of a critical vulnerability.
Vulnerabilities
Vulnerabilities are grouped and colored by severity. Critical, High, and Medium vulnerabilities are included by default but you can toggle which ones are relevant to your interests by clicking the button.
Clicking one of these metrics navigates you to a view (shown below) where you can browse the filtered set of vulnerabilities matching that severity.

For more info on a particular vulnerability, click on its corresponding button visible in the Links column. To view the exact tags affected, drill down to a specific repository by expanding the arrows.
View that tag’s in-depth analysis by clicking on the value within its Image Digest column.
Policy Evaluations
Policy Evaluations are grouped by their evaluation outcome such as Pass or Fail and can be further filtered by the reason for that result. All reasons are included by default but as with other widget properties, they can be edited by clicking the button.
Clicking one of these results navigates you to a view (shown below) where you can browse the affected and filtered set of tags.

Dig down to a specific tag by expanding the arrow shown on the left side of the row.
Navigate using the Image Digest value to view even more info such as the specific policy being triggered and what exactly is triggering it. If you’re interested in viewing the contents of your policy, click on the Policy ID value.
Dashboard Configuration
After populating your Dashboard with various widgets, you can easily modify the layout by using some methods explained below:
Click this icon shown in the top right or the header of a widget to Drag and Drop it into a new location.
Shown in the bottom right of a widget, click and hold this icon to Resize it.
Click this icon shown in the top right of a widget to Expand it and include a graphical representation of how your data has evolved over a time period of your choice.
Click this icon shown in the top right of a widget to Compact it into an easily digestable view of the metrics you’re interested in.
lick this icon shown in the top right of a widget to Delete it from the dashboard.
3 - Configuring AnchoreCTL
The anchorectl command can be configured with command-line arguments, environment variables, and/or a configuration file. Typically, a configuration file should be created to set any static configuration parameters (your Anchore Enterprise’s URL, logging behavior, cataloger configurations, etc), so that invocations of the tool only require you to provide command-specific parameters as environment/cli options. However, to fully support stateless scripting, a configuration file is not strictly required (settings can be put in environment/cli options).
Important AnchoreCTL is version-aligned with Anchore Enterprise for major/minor. Please refer to the Enterprise Release Notes for the supported version of AnchoreCTL.
The anchorectl tool will search for an available configuration file using the following search order, until it finds a match:
- .anchorectl.yaml
- anchorectl.yaml
- .anchorectl/config.yaml
- ~/.anchorectl.yaml
- ~/anchorectl.yaml
- $XDG_CONFIG_HOME/anchorectl/config.yaml
Note The anchorectl can also utilize inline Environment Variables which override any configuration file settings.
Note The ANCHORECTL_CONFIG environment variable can be used to specify a custom location for the AnchoreCTL YAML file.
For the most basic functional invocation of anchorectl, the only required parameters are listed below:
url: "" # the URL to the Anchore Enterprise API (env var: "ANCHORECTL_URL")
username: "" # the Anchore Enterprise username (env var: "ANCHORECTL_USERNAME")
password: "" # the Anchore Enterprise user's login password (env var: "ANCHORECTL_PASSWORD")
For example, with our Docker Compose quickstart deployment of Anchore Enterprise running on your local system, your ~/.anchorectl.yaml would look like the following
url: "http://localhost:8228"
username: "admin"
password: "yourstrongpassword"
A good way to quickly test that your anchorectl client is ready to use against a deployed and running Anchore Enterprise endpoint is to exercise the system status call, which will display status information fetched from your Enterprise deployment. With ~/.anchorectl.yaml installed and populated correctly, no environment or parameters are required:
anchorectl system status
✔ Status system
┌─────────────────┬────────────────────┬─────────────────────────────┬──────┬────────────────┬────────────┬──────────────┐
│ SERVICE │ HOST ID │ URL │ UP │ STATUS MESSAGE │ DB VERSION │ CODE VERSION │
├─────────────────┼────────────────────┼─────────────────────────────┼──────┼────────────────┼────────────┼──────────────┤
│ analyzer │ anchore-quickstart │ http://analyzer:8228 │ true │ available │ 5230 │ 5.23.0 │
│ policy_engine │ anchore-quickstart │ http://policy-engine:8228 │ true │ available │ 5230 │ 5.23.0 │
│ apiext │ anchore-quickstart │ http://api:8228 │ true │ available │ 5230 │ 5.23.0 │
│ reports │ anchore-quickstart │ http://reports:8228 │ true │ available │ 5230 │ 5.23.0 │
│ reports_worker │ anchore-quickstart │ http://reports-worker:8228 │ true │ available │ 5230 │ 5.23.0 │
│ data_syncer │ anchore-quickstart │ http://data-syncer:8228 │ true │ available | 5230 │ 5.23.0 │
│ simplequeue │ anchore-quickstart │ http://queue:8228 │ true │ available │ 5230 │ 5.23.0 │
│ notifications │ anchore-quickstart │ http://notifications:8228 │ true │ available │ 5230 │ 5.23.0 │
│ catalog │ anchore-quickstart │ http://catalog:8228 │ true │ available │ 5230 │ 5.23.0 │
└─────────────────┴────────────────────┴─────────────────────────────┴──────┴────────────────┴────────────┴──────────────┘
Congratulations you should now have a working AnchoreCTL.
Using Environment Variables
For some use cases being able to supply inline environment variables can be useful, see the following system status call as an example.
ANCHORECTL_URL="http://localhost:8228" ANCHORECTL_USERNAME="admin" ANCHORECTL_PASSWORD="foobar" anchorectl system status
✔ Status system
┌─────────────────┬────────────────────┬─────────────────────────────┬──────┬────────────────┬────────────┬──────────────┐
│ SERVICE │ HOST ID │ URL │ UP │ STATUS MESSAGE │ DB VERSION │ CODE VERSION │
├─────────────────┼────────────────────┼─────────────────────────────┼──────┼────────────────┼────────────┼──────────────┤
│ reports │ anchore-quickstart │ http://reports:8228 │ true │ available │ 5230 │ 5.23.0 │
│ analyzer │ anchore-quickstart │ http://analyzer:8228 │ true │ available │ 5230 │ 5.23.0 │
│ notifications │ anchore-quickstart │ http://notifications:8228 │ true │ available │ 5230 │ 5.23.0 │
│ apiext │ anchore-quickstart │ http://api:8228 │ true │ available │ 5230 │ 5.23.0 │
│ policy_engine │ anchore-quickstart │ http://policy-engine:8228 │ true │ available │ 5230 │ 5.23.0 │
│ reports_worker │ anchore-quickstart │ http://reports-worker:8228 │ true │ available │ 5230 │ 5.23.0 │
│ simplequeue │ anchore-quickstart │ http://queue:8228 │ true │ available │ 5230 │ 5.23.0 │
│ catalog │ anchore-quickstart │ http://catalog:8228 │ true │ available │ 5230 │ 5.23.0 │
└─────────────────┴────────────────────┴─────────────────────────────┴──────┴────────────────┴────────────┴──────────────┘
All the environment variable options can be seen by using anchorectl --help
Using API Keys
If you do not want to expose your private credentials in the configuration file, you can generate an API Key that allows most of the functionality of anchorectl.
Please see Generating API Keys
Once you generate the API Key, the UI will give you a key value. You can use this key with the anchorectl configuration:
url: "http://localhost:8228"
username: "_api_key"
password: <API Key Value>
NOTE: API Keys authenticate using HTTP basic auth. The username for API keys has to be _api_key.
Without setting up ~/.anchorectl.yaml or any configuration file, you can interact using environment variables:
Using Distributed Analysis Mode
If you intend to use anchorectl in Distributed Analysis mode, then you’ll need to enable two additional catalogers (secret-search, and file-contents) to mirror the behavior of Anchore Enterprise defaults, when performing an image analysis in Centralized Analysis mode. Below are the ~/.anchorectl.yaml settings to mirror the Anchore Enterprise defaults.
secret-search:
additional-patterns:
cataloger:
enabled: true
scope: Squashed
additional-patterns: {}
exclude-pattern-names: []
reveal-values: false
skip-files-above-size: 10000
content-search:
cataloger:
enabled: false
scope: Squashed
patterns: {}
reveal-values: false
skip-files-above-size: 10000
file-contents:
cataloger:
enabled: true
scope: Squashed
skip-files-above-size: 1048576
globs: ['/etc/passwd']
Note
anchorectl, when used in distributed analysis mode, already contains built-in regex patterns for AWS access keys, private keys and secret keys. You need to make sure you have the cataloger.enabled value set to true so that the cataloger is enabled.You can set further Regex searches up if you would like to do any additional searches by using the secret-search.additional-patterns value. Under the additional patterns header, you can use Go’s standard regular expression formatting to specify patterns. You can use this link as a reference to assist with writing these searches: https://github.com/google/re2/wiki/Syntax.
For more information on using anchorectl in Distributed Analysis mode, see Concepts: Image Analysis and AnchoreCTL Usage: Images.
Using Container Registry Authentication
When using distributed analysis with –from registry if the registry/repository requires authentication it can be supplied as follows:
ANCHORECTL_REGISTRY_AUTH_AUTHORITY=docker.io ANCHORECTL_REGISTRY_AUTH_USERNAME=dhusername ANCHORECTL_REGISTRY_AUTH_PASSWORD=XXXXXXXXXXX anchorectl image add --from registry docker.io/anchore/enterprise:v5
Using Help & Debug Modes
The anchorectl tool has extensive built-in help information for each command and operation, with many of the parameters allowing for environment overrides. To start with anchorectl, you can run the command with --help to see all the operation sections available:
A convenient way to see your changes taking effect is to instruct anchorectl to output DEBUG level logs to the screen using the -vv flag, which will display the full configuration that the tool is using (including the options you set, plus all the defaults and additional configuration file options available).
NOTE: if you would like to capture the full default configuration as displayed when running with -vv, you can paste that output as the contents of your .anchorectl.yaml, and then work with the settings for full control.
If you need any more help, please learn about Verifying Service Health
Using a Forward-Proxy
AnchoreCTL can be configured to use a forward-proxy as follows.
Windows
set http_proxy=server:port
set https_proxy=server:port
Please note that if your proxy uses an untrusted certificate you may also need the following:
set ANCHORECTL_HTTP_TLS_INSECURE=true
Mac/Linux
export http_proxy=http://yourproxy.com:port
export https_proxy=http://yourproxy.com:port
# or
export https_proxy=https://yourproxy.com:port
Please note that if your proxy uses an untrusted certificate you may also need the following:
export ANCHORECTL_HTTP_TLS_INSECURE=true
4 - Using the Analysis Archive
As mentioned in concepts, there are two locations for image analysis to be stored:
- The working set: the standard state after analysis completes. In this location, the image is fully loaded and available for policy evaluation, content, and vulnerability queries.
- The archive set: a location to keep image analysis data that cannot be used for policy evaluation or queries but can use cheaper storage and less db space and can be reloaded into the working set as needed.
Working with the Analysis Archive
List archived images:
anchorectl archive image list
✔ Fetched archive-images
┌─────────────────────────────────────────────────────────────────────────┬────────────────────────┬──────────┬──────────────┬──────────────────────┐
│ IMAGE DIGEST │ TAGS │ STATUS │ ARCHIVE SIZE │ ANALYZED AT │
├─────────────────────────────────────────────────────────────────────────┼────────────────────────┼──────────┼──────────────┼──────────────────────┤
│ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ docker.io/nginx:latest │ archived │ 1.4 MB │ 2022-08-23T21:08:29Z │
└─────────────────────────────────────────────────────────────────────────┴────────────────────────┴──────────┴──────────────┴──────────────────────┘
To add an image to the archive, use the digest. All analysis, policy evaluations, and tags will be added to the archive.
NOTE: this does not remove it from the working set. To fully move it you must first archive and then delete image in the working set using AnchoreCTL or the API directly.
Archiving Images
Archiving an image analysis creates a snapshot of the image’s analysis data, policy evaluation history, and tags and stores in a different storage location and
different record location than working set images.
anchorectl image list
✔ Fetched images
┌───────────────────────────────────────────────────────┬─────────────────────────────────────────────────────────────────────────┬──────────┬────────┐
│ TAG │ DIGEST │ ANALYSIS │ STATUS │
├───────────────────────────────────────────────────────┼─────────────────────────────────────────────────────────────────────────┼──────────┼────────┤
│ docker.io/ubuntu:latest │ sha256:33bca6883412038cc4cbd3ca11406076cf809c1dd1462a144ed2e38a7e79378a │ analyzed │ active │
│ docker.io/ubuntu:latest │ sha256:42ba2dfce475de1113d55602d40af18415897167d47c2045ec7b6d9746ff148f │ analyzed │ active │
│ docker.io/localimage:latest │ sha256:74c6eb3bbeb683eec0b8859bd844620d0b429a58d700ea14122c1892ae1f2885 │ analyzed │ active │
│ docker.io/nginx:latest │ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ analyzed │ active │
└───────────────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────┴──────────┴────────┘
# anchorectl archive image add sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc
✔ Added image to archive
┌─────────────────────────────────────────────────────────────────────────┬──────────┬────────────────────────┐
│ DIGEST │ STATUS │ DETAIL │
├─────────────────────────────────────────────────────────────────────────┼──────────┼────────────────────────┤
│ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ archived │ Completed successfully │
└─────────────────────────────────────────────────────────────────────────┴──────────┴────────────────────────┘
Then to delete it in the working set (optionally):
NOTE: You may need to use –force if the image is the newest of its tags and has active subscriptions_
anchorectl image delete sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc --force
┌─────────────────────────────────────────────────────────────────────────┬──────────┐
│ DIGEST │ STATUS │
├─────────────────────────────────────────────────────────────────────────┼──────────┤
│ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ deleting │
└─────────────────────────────────────────────────────────────────────────┴──────────┘
At this point the image in the archive only.
Restoring images from the archive into the working set
This will not delete the archive entry, only add it back to the working set. Restore and image to working set from archive:
anchorectl archive image restore sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc
✔ Restore image
┌────────────────────────┬─────────────────────────────────────────────────────────────────────────┬──────────┬────────┐
│ TAG │ DIGEST │ ANALYSIS │ STATUS │
├────────────────────────┼─────────────────────────────────────────────────────────────────────────┼──────────┼────────┤
│ docker.io/nginx:latest │ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ analyzed │ active │
└────────────────────────┴─────────────────────────────────────────────────────────────────────────┴──────────┴────────┘
To view the restored image:
anchorectl image get sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc
Tag: docker.io/nginx:latest
Digest: sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc
ID: 2b7d6430f78d432f89109b29d88d4c36c868cdbf15dc31d2132ceaa02b993763
Analysis: analyzed
Status: active
Working with Archive rules
As with all AnchoreCTL commands, the --help option will show the arguments, options and descriptions of valid values.
List existing rules:
anchorectl archive rule list
✔ Fetched rules
┌──────────────────────────────────┬────────────┬──────────────┬────────────────────┬────────────┬─────────┬───────┬──────────────────┬──────────────┬─────────────┬──────────────────┬────────┬──────────────────────┐
│ ID │ TRANSITION │ ANALYSIS AGE │ TAG VERSIONS NEWER │ REGISTRY │ REPO │ TAG │ REGISTRY EXCLUDE │ REPO EXCLUDE │ TAG EXCLUDE │ EXCLUDE EXP DAYS │ GLOBAL │ LAST UPDATED │
├──────────────────────────────────┼────────────┼──────────────┼────────────────────┼────────────┼─────────┼───────┼──────────────────┼──────────────┼─────────────┼──────────────────┼────────┼──────────────────────┤
│ 2ca9284202814f6aa41916fd8d21ddf2 │ archive │ 90d │ 90 │ * │ * │ * │ │ │ │ -1 │ false │ 2022-08-19T17:58:38Z │
│ 6cb4011b102a4ba1a86a5f3695871004 │ archive │ 90d │ 90 │ foobar.com │ myimage │ mytag │ barfoo.com │ * │ * │ -1 │ false │ 2022-08-22T18:47:32Z │
└──────────────────────────────────┴────────────┴──────────────┴────────────────────┴────────────┴─────────┴───────┴──────────────────┴──────────────┴─────────────┴──────────────────┴────────┴──────────────────────┘
Add a rule:
anchorectl archive rule add --transition archive --analysis-age-days 90 --tag-versions-newer 1 --selector-registry 'docker.io' --selector-repository 'library/*' --selector-tag 'latest'
✔ Added rule
ID: 0031546b9ce94cf0ae0e60c0f35b9ea3
Transition: archive
Analysis Age: 90d
Tag Versions Newer: 1
Selector:
Registry: docker.io
Repo: library/*
Tag: latest
Exclude:
Selector:
Registry Exclude:
Repo Exclude:
Tag Exclude:
Exclude Exp Days: -1
Global: false
Last Updated: 2022-08-24T22:57:51Z
The required parameters are: minimum age of analysis in days, number of tag versions newer, and the transition to use.
There is also an optional --system-global flag available for admin account users that makes the rule apply to all accounts
in the system.
As a non-admin user you can see global rules but you cannot update/delete them (will get a 404):
#ANCHORECTL_USERNAME=test1user ANCHORECTL_PASSWORD=password ANCHORECTL_ACCOUNT=test1acct anchorectl archive rule list
✔ Fetched rules
┌──────────────────────────────────┬────────────┬──────────────┬────────────────────┬───────────┬───────────┬────────┬──────────────────┬──────────────┬─────────────┬──────────────────┬────────┬──────────────────────┐
│ ID │ TRANSITION │ ANALYSIS AGE │ TAG VERSIONS NEWER │ REGISTRY │ REPO │ TAG │ REGISTRY EXCLUDE │ REPO EXCLUDE │ TAG EXCLUDE │ EXCLUDE EXP DAYS │ GLOBAL │ LAST UPDATED │
├──────────────────────────────────┼────────────┼──────────────┼────────────────────┼───────────┼───────────┼────────┼──────────────────┼──────────────┼─────────────┼──────────────────┼────────┼──────────────────────┤
│ 16dc38cef54e4ce5ac87d00e90b4a4f2 │ archive │ 90d │ 1 │ docker.io │ library/* │ latest │ │ │ │ -1 │ true │ 2022-08-24T23:01:05Z │
└──────────────────────────────────┴────────────┴──────────────┴────────────────────┴───────────┴───────────┴────────┴──────────────────┴──────────────┴─────────────┴──────────────────┴────────┴──────────────────────┘
# ANCHORECTL_USERNAME=test1user ANCHORECTL_PASSWORD=password ANCHORECTL_ACCOUNT=test1acct anchorectl archive rule delete 16dc38cef54e4ce5ac87d00e90b4a4f2
⠙ Deleting rule
error: 1 error occurred:
* unable to delete rule:
{
"detail": {
"error_codes": []
},
"httpcode": 404,
"message": "Rule not found"
}
# ANCHORECTL_USERNAME=test1user ANCHORECTL_PASSWORD=password ANCHORECTL_ACCOUNT=test1acct anchorectl archive rule get 16dc38cef54e4ce5ac87d00e90b4a4f2
✔ Fetched rule
ID: 16dc38cef54e4ce5ac87d00e90b4a4f2
Transition: archive
Analysis Age: 90d
Tag Versions Newer: 1
Selector:
Registry: docker.io
Repo: library/*
Tag: latest
Exclude:
Selector:
Registry Exclude:
Repo Exclude:
Tag Exclude:
Exclude Exp Days: -1
Global: true
Last Updated: 2022-08-24T23:01:05Z
Delete a rule:
anchorectl archive rule delete 16dc38cef54e4ce5ac87d00e90b4a4f2
✔ Deleted rule
No results
5 - Artifact Lifecycle Policies
Artifact Lifecycle Policies are instruction sets which perform lifecycle events on certain types of artifacts.
Each policy can perform an action on a given artifact_type based on configured policy_conditions (rules/selectors).
As an example, a system administrator may create an Artifact Lifecycle Policy that will automatically delete any image that has an analysis date older than 180
days.
WARNING ⚠️
- ⚠️ These policies have the ability to delete data without archive/backup. Proceed with caution!
- ⚠️ These policies are GLOBAL they will impact every account on the system.
- ⚠️ These policies can only be created and managed by a system administrator.
Policy Components
Artifact Lifecycle Policies are global policies that will execute on a schedule defined by a cycle_timer within the
catalog service. services.catalog.cycle_timers.artifact_lifecycle_policy_tasks has a default time of every 12 hours.
The policy is constructed with the following parameters:
Artifacts Types - The type of artifacts the policy will consider. The current supported type is image.
Inclusion Rules - The set of criteria which will be used to determine the set of artifacts to work on.
All criteria must be satisfied for the policy to enact on an artifact.
- days_since_analyzed
- Selects artifacts whose
analyzed_at date is n days old. - If this value is set to less than zero, this rule is disabled.
- An artifact that has not been analyzed, either because it failed analysis or the analysis is pending, will not be included.
- even_if_exists_in_runtime_inventory
- When
true, an artifact will be included even if it exists in the Runtime Inventory. - When
false, an artifact will not be included if it exists in the Runtime Inventory. Essentially protecting artifacts found in your runtime inventory. Please review the Inventory Time-To-Live for information on how to prune the Runtime Inventory.
- include_base_images
- When
true, images that have ancestral children will be included. - When
false, images that have ancestral children will not be included. - Note: These are evaluated per run. As children are deleted, a previously excluded parent image may too become eligible for deletion.
- include_failed_analysis
- When
true, images that are in a failed analysis state will be included.- Note: When the image does not contain an
analyzed_at date, the created_at date will be used.
- When
false, images that are in a failed analysis state will not be included. This is the default behavior.
Policy Actions - After the policy determines a set of artifacts that satisfy the Inclusion Rules, this
is the action which will be performed on them. The current supported action is delete.
Actioned artifacts will have a matching system Event created for audit and notification purposes.
Policy Interaction
If more than one policy is enabled, each policy will work independently, using its set of rules to determine if any
artifacts satisfy its criteria. Each policy will apply its action on the set of artifacts.
Creating a new Artifact Lifecycle Policy
Due to the potentially destructive nature of these policies every parameter must be explicitly declared when creating a
new policy. This means all policy rules must be explicitly configured or explicitly disabled.
anchorectl system artifact-lifecycle-policy add --action=delete --artifact-type=image --name="example policy" --description=example --enabled=false --days-since-analyzed=30 --even-if-exists-in-runtime=true --include-base-images=false
✔ Added artifact-lifecycle-policy
Name: example lifecycle policy
Policy Conditions:
- artifactType: image
daysSinceAnalyzed: 30
evenIfExistsInRuntimeInventory: true
includeBaseImages: false
version: 1
Uuid: 999ad42e-e467-4251-b80c-6681b79ad4f6
Action: delete
Deleted At:
Enabled: false
Updated At: 2025-08-19T06:35:39Z
Created At: 2025-08-19T06:35:39Z
Description: example
Updating an existing Artifact Lifecycle Policy
anchorectl system artifact-lifecycle-policy update 5620b641-a25f-4b1f-966c-929281a41e16 --action=delete --name=example --artifact-type=image --days-since-analyzed=60 --even-if-exists-in-runtime=false --include-base-images=false
✔ Update artifact-lifecycle-policy
Name: example
Policy Conditions:
- artifactType: image
daysSinceAnalyzed: 60
evenIfExistsInRuntimeInventory: false
includeBaseImages: false
version: 2
Uuid: 5620b641-a25f-4b1f-966c-929281a41e16
Action: delete
Deleted At:
Enabled: false
Updated At: 2023-11-22T13:58:04Z
Created At: 2023-11-22T13:02:24Z
Description: test description
Enabling the Artifact Lifecycle Policy
anchorectl system artifact-lifecycle-policy update 5620b641-a25f-4b1f-966c-929281a41e16 --action=delete --name=example --artifact-type=image --days-since-analyzed=60 --even-if-exists-in-runtime=false --enabled=true --include-base-images=false
✔ Update artifact-lifecycle-policy
Name: example
Policy Conditions:
- artifactType: image
daysSinceAnalyzed: 60
evenIfExistsInRuntimeInventory: false
includeBaseImages: false
version: 2
Uuid: 5620b641-a25f-4b1f-966c-929281a41e16
Action: delete
Deleted At:
Enabled: true
Updated At: 2023-11-22T13:58:04Z
Created At: 2023-11-22T13:02:24Z
Description: test description
List Artifact Lifecycle Policies
anchorectl system artifact-lifecycle-policy list
✔ Fetched artifact-lifecycle-policies
Items:
- action: delete
createdAt: "2023-11-22T13:02:24Z"
description: example description
enabled: true
name: "example policy"
policyConditions:
- artifactType: image
daysSinceAnalyzed: 1
evenIfExistsInRuntimeInventory: true
includeBaseImages: false
version: 2
updatedAt: "2023-11-22T13:02:24Z"
uuid: 5620b641-a25f-4b1f-966c-929281a41e16
Get specific Artifact Lifecycle Policy
Note: it is possible to request “deleted” policies through this API for audit reasons. The deleted_at field will be null, and enabled will be true if the policy is active.
anchorectl system artifact-lifecycle-policy get 5620b641-a25f-4b1f-966c-929281a41e16
✔ Fetched artifact-lifecycle-policy
Name: 2023-11-22T13:02:24.621Z
Policy Conditions:
- artifactType: image
daysSinceAnalyzed: 1
evenIfExistsInRuntimeInventory: true
includeBaseImages: false
version: 1
Uuid: 5620b641-a25f-4b1f-966c-929281a41e16
Action: delete
Deleted At:
Enabled: true
Updated At: 2023-11-22T13:02:24Z
Created At: 2023-11-22T13:02:24Z
Description: test description
Delete a policy
Note: for the purposes of audit the policy will still remain in the system. It will be disabled and marked deleted. This will effectively make it hidden unless explicitly requested by its UUID through the API.
anchorectl system artifact-lifecycle-policy delete 73226831-9140-4d27-a922-4a61e43dbb0d
✔ Deleted artifact-lifecycle-policy
No results
6 - Data Synchronization
Introduction
In this section, you’ll learn how Anchore Enterprise ingests the data used for analysis and vulnerability management.
Your Anchore Enterprise deployment uses five datasets that are managed by the Anchore Data Service.
These datasets are automatically synced to your Anchore Enterprise deployment by the Data Syncer Service.
The datasets are:
- Vulnerability Database (vulnerability_db)
- Vulnerability Match Exclusions Database (vulnerability_match_exclusions_db)
- ClamAV Malware Database (clamav_db)
- STIG Profiles (stig_profile_db)
If your deployment is air-gapped, please review the Air-gapped Deployment
documentation for instructions on how to manually sync these datasets.
Please review the Anchore Data Service status page for
information on how to check the status of the datasets.
Requirements
Network Ingress
The following FQDN will need to be allowlisted in your network to allow the Data Syncer Service to communicate with the Anchore Data Service:
https://data.anchore-enterprise.com
Ideally the endpoint can be whitelisted via a layer 7/proxy.
If you are filtering based on IP, please raise a support ticket with Anchore so that we can provide you with the IP addresses.
6.1 - Data Syncer Configuration
Dataset Synchronization Interval
The Data Syncer Service will check every hour if there is new data available from the Anchore Data Service.
If it finds a new dataset then it will sync it down immediately.
It will also trigger the Policy Engine Service to reprocess the data to make it available for policy evaluations. The analyzer checks the
data syncer for a new ClamAV Malware signature database before every malware scan (if enabled).
Controlling Which Feeds and Groups are Synced
During initial data sync, you can always query the progress and status of the feed sync using anchorectl.
anchorectl feed list
✔ List feed
┌────────────────────────────────────────────┬────────────────────┬─────────┬──────────────────────┬──────────────┐
│ FEED │ GROUP │ ENABLED │ LAST UPDATED │ RECORD COUNT │
├────────────────────────────────────────────┼────────────────────┼─────────┼──────────────────────┼──────────────┤
│ ClamAV Malware Database │ clamav_db │ true │ 2024-09-26T13:13:50Z │ 1 │
│ Vulnerabilities │ github:composer │ true │ 2024-09-26T12:14:50Z │ 4036 │
│ Vulnerabilities │ github:dart │ true │ 2024-09-26T12:14:50Z │ 8 │
│ Vulnerabilities │ github:gem │ true │ 2024-09-26T12:14:50Z │ 817 │
│ Vulnerabilities │ github:go │ true │ 2024-09-26T12:14:50Z │ 1875 │
│ Vulnerabilities │ github:java │ true │ 2024-09-26T12:14:50Z │ 5058 │
│ Vulnerabilities │ github:npm │ true │ 2024-09-26T12:14:50Z │ 15586 │
│ Vulnerabilities │ github:nuget │ true │ 2024-09-26T12:14:50Z │ 624 │
│ Vulnerabilities │ github:python │ true │ 2024-09-26T12:14:50Z │ 3226 │
.
.
.
│ CISA KEV (Known Exploited Vulnerabilities) │ kev_db │ true │ 2024-09-26T13:13:47Z │ 1181 │
| Exploit Prediction Scoring System Database │ epss_db │ true │ 2024-11-18T18:04:12Z │ 266565 │
└────────────────────────────────────────────┴────────────────────┴─────────┴──────────────────────┴──────────────┘
Using the Config File to Include/Exclude Feeds and Package Types when scanning for vulnerabilities
With the feed service removed, Enterprise no longer supports excluding certain providers and package types from the vulnerability feed.
To ensure the same experience when using the product, you can now exclude certain providers and package types from matching vulnerabilities.
Using Helm
In your values.yaml file set the following:
policy_engine:
vulnerabilities:
matching:
exclude:
providers: ["rhel","debian"]
package_types: ["rpm"]
Using Docker Compose
In your config.yaml file set the following:
services:
policy_engine:
vulnerabilities:
matching:
exclude:
providers: ["rhel","debian"]
package_types: ["rpm"]
Further information can be found in Vulnerability Management.
6.2 - Data Synchronization
When Anchore Enterprise runs, the Data Syncer Service will begin to synchronize security feed data from the Anchore Data Service.
CVE data for Linux distributions such as Alpine, CentOS, Debian, Oracle, Red Hat and Ubuntu will be downloaded.
The initial sync typically take anywhere from 1-5 minutes depending on your environment and network speed. After that the Data Syncer Service will check every hour if there is new data available from the Anchore Data Service. If it finds a new dataset then it will sync it down immediately.
For air-gapped environments, please see the Air-Gapped documentation.
Checking Feed Status
Feed information can be retrieved through the API and AnchoreCTL.
anchorectl feed list
✔ List feed
┌────────────────────────────────────────────┬────────────────────┬─────────┬──────────────────────┬──────────────┐
│ FEED │ GROUP │ ENABLED │ LAST UPDATED │ RECORD COUNT │
├────────────────────────────────────────────┼────────────────────┼─────────┼──────────────────────┼──────────────┤
│ ClamAV Malware Database │ clamav_db │ true │ 2024-09-26T13:13:50Z │ 1 │
│ Vulnerabilities │ github:composer │ true │ 2024-09-26T12:14:50Z │ 4036 │
│ Vulnerabilities │ github:dart │ true │ 2024-09-26T12:14:50Z │ 8 │
│ Vulnerabilities │ github:gem │ true │ 2024-09-26T12:14:50Z │ 817 │
│ Vulnerabilities │ github:go │ true │ 2024-09-26T12:14:50Z │ 1875 │
│ Vulnerabilities │ github:java │ true │ 2024-09-26T12:14:50Z │ 5058 │
│ Vulnerabilities │ github:npm │ true │ 2024-09-26T12:14:50Z │ 15586 │
│ Vulnerabilities │ github:nuget │ true │ 2024-09-26T12:14:50Z │ 624 │
│ Vulnerabilities │ github:python │ true │ 2024-09-26T12:14:50Z │ 3226 │
│ Vulnerabilities │ github:rust │ true │ 2024-09-26T12:14:50Z │ 804 │
│ Vulnerabilities │ github:swift │ true │ 2024-09-26T12:14:50Z │ 32 │
│ Vulnerabilities │ msrc:10378 │ true │ 2024-09-26T12:14:49Z │ 2668 │
│ Vulnerabilities │ msrc:10379 │ true │ 2024-09-26T12:14:49Z │ 2645 │
│ Vulnerabilities │ msrc:10481 │ true │ 2024-09-26T12:14:49Z │ 1951 │
│ Vulnerabilities │ msrc:10482 │ true │ 2024-09-26T12:14:49Z │ 2028 │
│ Vulnerabilities │ msrc:10483 │ true │ 2024-09-26T12:14:49Z │ 2822 │
│ Vulnerabilities │ msrc:10484 │ true │ 2024-09-26T12:14:49Z │ 1934 │
│ Vulnerabilities │ msrc:10543 │ true │ 2024-09-26T12:14:49Z │ 2796 │
│ Vulnerabilities │ msrc:10729 │ true │ 2024-09-26T12:14:49Z │ 2908 │
│ Vulnerabilities │ msrc:10735 │ true │ 2024-09-26T12:14:49Z │ 3006 │
│ Vulnerabilities │ msrc:10788 │ true │ 2024-09-26T12:14:49Z │ 466 │
│ Vulnerabilities │ msrc:10789 │ true │ 2024-09-26T12:14:49Z │ 437 │
│ Vulnerabilities │ msrc:10816 │ true │ 2024-09-26T12:14:49Z │ 3328 │
│ Vulnerabilities │ msrc:10852 │ true │ 2024-09-26T12:14:49Z │ 3043 │
│ Vulnerabilities │ msrc:10853 │ true │ 2024-09-26T12:14:49Z │ 3167 │
│ Vulnerabilities │ msrc:10855 │ true │ 2024-09-26T12:14:49Z │ 3300 │
│ Vulnerabilities │ msrc:10951 │ true │ 2024-09-26T12:14:49Z │ 716 │
│ Vulnerabilities │ msrc:10952 │ true │ 2024-09-26T12:14:49Z │ 766 │
│ Vulnerabilities │ msrc:11453 │ true │ 2024-09-26T12:14:49Z │ 1240 │
│ Vulnerabilities │ msrc:11454 │ true │ 2024-09-26T12:14:49Z │ 1290 │
│ Vulnerabilities │ msrc:11466 │ true │ 2024-09-26T12:14:49Z │ 395 │
│ Vulnerabilities │ msrc:11497 │ true │ 2024-09-26T12:14:49Z │ 1454 │
│ Vulnerabilities │ msrc:11498 │ true │ 2024-09-26T12:14:49Z │ 1514 │
│ Vulnerabilities │ msrc:11499 │ true │ 2024-09-26T12:14:49Z │ 981 │
│ Vulnerabilities │ msrc:11563 │ true │ 2024-09-26T12:14:49Z │ 1344 │
│ Vulnerabilities │ msrc:11568 │ true │ 2024-09-26T12:14:49Z │ 2993 │
│ Vulnerabilities │ msrc:11569 │ true │ 2024-09-26T12:14:49Z │ 3095 │
│ Vulnerabilities │ msrc:11570 │ true │ 2024-09-26T12:14:49Z │ 2975 │
│ Vulnerabilities │ msrc:11571 │ true │ 2024-09-26T12:14:49Z │ 3266 │
│ Vulnerabilities │ msrc:11572 │ true │ 2024-09-26T12:14:49Z │ 3238 │
│ Vulnerabilities │ msrc:11583 │ true │ 2024-09-26T12:14:49Z │ 1038 │
│ Vulnerabilities │ msrc:11644 │ true │ 2024-09-26T12:14:49Z │ 1054 │
│ Vulnerabilities │ msrc:11645 │ true │ 2024-09-26T12:14:49Z │ 1089 │
│ Vulnerabilities │ msrc:11646 │ true │ 2024-09-26T12:14:49Z │ 1055 │
│ Vulnerabilities │ msrc:11647 │ true │ 2024-09-26T12:14:49Z │ 1074 │
│ Vulnerabilities │ msrc:11712 │ true │ 2024-09-26T12:14:49Z │ 1442 │
│ Vulnerabilities │ msrc:11713 │ true │ 2024-09-26T12:14:49Z │ 1491 │
│ Vulnerabilities │ msrc:11714 │ true │ 2024-09-26T12:14:49Z │ 1447 │
│ Vulnerabilities │ msrc:11715 │ true │ 2024-09-26T12:14:49Z │ 999 │
│ Vulnerabilities │ msrc:11766 │ true │ 2024-09-26T12:14:49Z │ 912 │
│ Vulnerabilities │ msrc:11767 │ true │ 2024-09-26T12:14:49Z │ 915 │
│ Vulnerabilities │ msrc:11768 │ true │ 2024-09-26T12:14:49Z │ 940 │
│ Vulnerabilities │ msrc:11769 │ true │ 2024-09-26T12:14:49Z │ 934 │
│ Vulnerabilities │ msrc:11800 │ true │ 2024-09-26T12:14:49Z │ 382 │
│ Vulnerabilities │ msrc:11801 │ true │ 2024-09-26T12:14:49Z │ 1277 │
│ Vulnerabilities │ msrc:11802 │ true │ 2024-09-26T12:14:49Z │ 1277 │
│ Vulnerabilities │ msrc:11803 │ true │ 2024-09-26T12:14:49Z │ 981 │
│ Vulnerabilities │ msrc:11896 │ true │ 2024-09-26T12:14:49Z │ 792 │
│ Vulnerabilities │ msrc:11897 │ true │ 2024-09-26T12:14:49Z │ 762 │
│ Vulnerabilities │ msrc:11898 │ true │ 2024-09-26T12:14:49Z │ 763 │
│ Vulnerabilities │ msrc:11923 │ true │ 2024-09-26T12:14:49Z │ 1733 │
│ Vulnerabilities │ msrc:11924 │ true │ 2024-09-26T12:14:49Z │ 1726 │
│ Vulnerabilities │ msrc:11926 │ true │ 2024-09-26T12:14:49Z │ 1536 │
│ Vulnerabilities │ msrc:11927 │ true │ 2024-09-26T12:14:49Z │ 1503 │
│ Vulnerabilities │ msrc:11929 │ true │ 2024-09-26T12:14:49Z │ 1433 │
│ Vulnerabilities │ msrc:11930 │ true │ 2024-09-26T12:14:49Z │ 1429 │
│ Vulnerabilities │ msrc:11931 │ true │ 2024-09-26T12:14:49Z │ 1474 │
│ Vulnerabilities │ msrc:12085 │ true │ 2024-09-26T12:14:49Z │ 1044 │
│ Vulnerabilities │ msrc:12086 │ true │ 2024-09-26T12:14:49Z │ 1053 │
│ Vulnerabilities │ msrc:12097 │ true │ 2024-09-26T12:14:49Z │ 964 │
│ Vulnerabilities │ msrc:12098 │ true │ 2024-09-26T12:14:49Z │ 939 │
│ Vulnerabilities │ msrc:12099 │ true │ 2024-09-26T12:14:49Z │ 943 │
│ Vulnerabilities │ nvd │ true │ 2024-09-26T12:14:58Z │ 263831 │
│ Vulnerabilities │ alpine:3.10 │ true │ 2024-09-26T12:13:37Z │ 2321 │
│ Vulnerabilities │ alpine:3.11 │ true │ 2024-09-26T12:13:37Z │ 2659 │
│ Vulnerabilities │ alpine:3.12 │ true │ 2024-09-26T12:13:37Z │ 3193 │
│ Vulnerabilities │ alpine:3.13 │ true │ 2024-09-26T12:13:37Z │ 3684 │
│ Vulnerabilities │ alpine:3.14 │ true │ 2024-09-26T12:13:37Z │ 4265 │
│ Vulnerabilities │ alpine:3.15 │ true │ 2024-09-26T12:13:37Z │ 4815 │
│ Vulnerabilities │ alpine:3.16 │ true │ 2024-09-26T12:13:37Z │ 5271 │
│ Vulnerabilities │ alpine:3.17 │ true │ 2024-09-26T12:13:37Z │ 5630 │
│ Vulnerabilities │ alpine:3.18 │ true │ 2024-09-26T12:13:37Z │ 6144 │
│ Vulnerabilities │ alpine:3.19 │ true │ 2024-09-26T12:13:37Z │ 6338 │
│ Vulnerabilities │ alpine:3.2 │ true │ 2024-09-26T12:13:37Z │ 305 │
│ Vulnerabilities │ alpine:3.20 │ true │ 2024-09-26T12:13:37Z │ 6428 │
│ Vulnerabilities │ alpine:3.3 │ true │ 2024-09-26T12:13:37Z │ 470 │
│ Vulnerabilities │ alpine:3.4 │ true │ 2024-09-26T12:13:37Z │ 679 │
│ Vulnerabilities │ alpine:3.5 │ true │ 2024-09-26T12:13:37Z │ 902 │
│ Vulnerabilities │ alpine:3.6 │ true │ 2024-09-26T12:13:37Z │ 1075 │
│ Vulnerabilities │ alpine:3.7 │ true │ 2024-09-26T12:13:37Z │ 1461 │
│ Vulnerabilities │ alpine:3.8 │ true │ 2024-09-26T12:13:37Z │ 1671 │
│ Vulnerabilities │ alpine:3.9 │ true │ 2024-09-26T12:13:37Z │ 1955 │
│ Vulnerabilities │ alpine:edge │ true │ 2024-09-26T12:13:37Z │ 6466 │
│ Vulnerabilities │ amzn:2 │ true │ 2024-09-26T12:13:34Z │ 2280 │
│ Vulnerabilities │ amzn:2022 │ true │ 2024-09-26T12:13:34Z │ 276 │
│ Vulnerabilities │ amzn:2023 │ true │ 2024-09-26T12:13:34Z │ 736 │
│ Vulnerabilities │ chainguard:rolling │ true │ 2024-09-26T12:13:19Z │ 4462 │
│ Vulnerabilities │ debian:10 │ true │ 2024-09-26T12:14:52Z │ 32021 │
│ Vulnerabilities │ debian:11 │ true │ 2024-09-26T12:14:52Z │ 33497 │
│ Vulnerabilities │ debian:12 │ true │ 2024-09-26T12:14:52Z │ 32452 │
│ Vulnerabilities │ debian:13 │ true │ 2024-09-26T12:14:52Z │ 31631 │
│ Vulnerabilities │ debian:7 │ true │ 2024-09-26T12:14:52Z │ 20455 │
│ Vulnerabilities │ debian:8 │ true │ 2024-09-26T12:14:52Z │ 24058 │
│ Vulnerabilities │ debian:9 │ true │ 2024-09-26T12:14:52Z │ 28240 │
│ Vulnerabilities │ debian:unstable │ true │ 2024-09-26T12:14:52Z │ 35913 │
│ Vulnerabilities │ mariner:1.0 │ true │ 2024-09-26T12:14:41Z │ 2092 │
│ Vulnerabilities │ mariner:2.0 │ true │ 2024-09-26T12:14:41Z │ 2624 │
│ Vulnerabilities │ ol:5 │ true │ 2024-09-26T12:14:44Z │ 1255 │
│ Vulnerabilities │ ol:6 │ true │ 2024-09-26T12:14:44Z │ 1709 │
│ Vulnerabilities │ ol:7 │ true │ 2024-09-26T12:14:44Z │ 2196 │
│ Vulnerabilities │ ol:8 │ true │ 2024-09-26T12:14:44Z │ 1906 │
│ Vulnerabilities │ ol:9 │ true │ 2024-09-26T12:14:44Z │ 870 │
│ Vulnerabilities │ rhel:5 │ true │ 2024-09-26T12:14:59Z │ 7193 │
│ Vulnerabilities │ rhel:6 │ true │ 2024-09-26T12:14:59Z │ 11121 │
│ Vulnerabilities │ rhel:7 │ true │ 2024-09-26T12:14:59Z │ 11359 │
│ Vulnerabilities │ rhel:8 │ true │ 2024-09-26T12:14:59Z │ 6998 │
│ Vulnerabilities │ rhel:9 │ true │ 2024-09-26T12:14:59Z │ 4039 │
│ Vulnerabilities │ sles:11 │ true │ 2024-09-26T12:14:47Z │ 594 │
│ Vulnerabilities │ sles:11.1 │ true │ 2024-09-26T12:14:47Z │ 6125 │
│ Vulnerabilities │ sles:11.2 │ true │ 2024-09-26T12:14:47Z │ 3291 │
│ Vulnerabilities │ sles:11.3 │ true │ 2024-09-26T12:14:47Z │ 7081 │
│ Vulnerabilities │ sles:11.4 │ true │ 2024-09-26T12:14:47Z │ 6583 │
│ Vulnerabilities │ sles:12 │ true │ 2024-09-26T12:14:47Z │ 6018 │
│ Vulnerabilities │ sles:12.1 │ true │ 2024-09-26T12:14:47Z │ 6205 │
│ Vulnerabilities │ sles:12.2 │ true │ 2024-09-26T12:14:47Z │ 8339 │
│ Vulnerabilities │ sles:12.3 │ true │ 2024-09-26T12:14:47Z │ 10396 │
│ Vulnerabilities │ sles:12.4 │ true │ 2024-09-26T12:14:47Z │ 10215 │
│ Vulnerabilities │ sles:12.5 │ true │ 2024-09-26T12:14:47Z │ 12444 │
│ Vulnerabilities │ sles:15 │ true │ 2024-09-26T12:14:47Z │ 8737 │
│ Vulnerabilities │ sles:15.1 │ true │ 2024-09-26T12:14:47Z │ 9245 │
│ Vulnerabilities │ sles:15.2 │ true │ 2024-09-26T12:14:47Z │ 9572 │
│ Vulnerabilities │ sles:15.3 │ true │ 2024-09-26T12:14:47Z │ 10074 │
│ Vulnerabilities │ sles:15.4 │ true │ 2024-09-26T12:14:47Z │ 10436 │
│ Vulnerabilities │ sles:15.5 │ true │ 2024-09-26T12:14:47Z │ 10880 │
│ Vulnerabilities │ sles:15.6 │ true │ 2024-09-26T12:14:47Z │ 3775 │
│ Vulnerabilities │ ubuntu:12.04 │ true │ 2024-09-26T12:15:12Z │ 14934 │
│ Vulnerabilities │ ubuntu:12.10 │ true │ 2024-09-26T12:15:12Z │ 5641 │
│ Vulnerabilities │ ubuntu:13.04 │ true │ 2024-09-26T12:15:12Z │ 4117 │
│ Vulnerabilities │ ubuntu:14.04 │ true │ 2024-09-26T12:15:12Z │ 37910 │
│ Vulnerabilities │ ubuntu:14.10 │ true │ 2024-09-26T12:15:12Z │ 4437 │
│ Vulnerabilities │ ubuntu:15.04 │ true │ 2024-09-26T12:15:12Z │ 6220 │
│ Vulnerabilities │ ubuntu:15.10 │ true │ 2024-09-26T12:15:12Z │ 6489 │
│ Vulnerabilities │ ubuntu:16.04 │ true │ 2024-09-26T12:15:12Z │ 35057 │
│ Vulnerabilities │ ubuntu:16.10 │ true │ 2024-09-26T12:15:12Z │ 8607 │
│ Vulnerabilities │ ubuntu:17.04 │ true │ 2024-09-26T12:15:12Z │ 9094 │
│ Vulnerabilities │ ubuntu:17.10 │ true │ 2024-09-26T12:15:12Z │ 7900 │
│ Vulnerabilities │ ubuntu:18.04 │ true │ 2024-09-26T12:15:12Z │ 29533 │
│ Vulnerabilities │ ubuntu:18.10 │ true │ 2024-09-26T12:15:12Z │ 8367 │
│ Vulnerabilities │ ubuntu:19.04 │ true │ 2024-09-26T12:15:12Z │ 8634 │
│ Vulnerabilities │ ubuntu:19.10 │ true │ 2024-09-26T12:15:12Z │ 8414 │
│ Vulnerabilities │ ubuntu:20.04 │ true │ 2024-09-26T12:15:12Z │ 25271 │
│ Vulnerabilities │ ubuntu:20.10 │ true │ 2024-09-26T12:15:12Z │ 9974 │
│ Vulnerabilities │ ubuntu:21.04 │ true │ 2024-09-26T12:15:12Z │ 11304 │
│ Vulnerabilities │ ubuntu:21.10 │ true │ 2024-09-26T12:15:12Z │ 12628 │
│ Vulnerabilities │ ubuntu:22.04 │ true │ 2024-09-26T12:15:12Z │ 23527 │
│ Vulnerabilities │ ubuntu:22.10 │ true │ 2024-09-26T12:15:12Z │ 14483 │
│ Vulnerabilities │ ubuntu:23.04 │ true │ 2024-09-26T12:15:12Z │ 15562 │
│ Vulnerabilities │ ubuntu:23.10 │ true │ 2024-09-26T12:15:12Z │ 18431 │
│ Vulnerabilities │ ubuntu:24.04 │ true │ 2024-09-26T12:15:12Z │ 19537 │
│ Vulnerabilities │ wolfi:rolling │ true │ 2024-09-26T12:14:43Z │ 2867 │
│ Vulnerabilities │ anchore:exclusions │ true │ 2024-09-26T12:14:43Z │ 12851 │
│ CISA KEV (Known Exploited Vulnerabilities) │ kev_db │ true │ 2024-09-26T13:13:47Z │ 1181 │
| Exploit Prediction Scoring System Database │ epss_db │ true │ 2024-11-18T18:04:12Z │ 266565 │
└────────────────────────────────────────────┴────────────────────┴─────────┴──────────────────────┴──────────────┘
This command will report list the feeds synchronized by Anchore Enterprise, last sync time and current record count.
Note: Time is reported as UTC, not local time.
Manually initiating feed sync
You can initiate a manual sync of the latest datasets which tells the Data Syncer Service to download the latest feed data from the Anchore Data Service.
anchorectl feed sync
✔ Synced feeds
This will also inform the policy-engine to sync down the new dataset if the Data Syncer Service has successfully downloaded the latest data.
Forcing a full resync
If there is a scenario where you want the Data Syncer Service to force download the latest datasets and overwrite the existing data, you can use the --force_sync flag.
./anchorectl feed sync --force_sync
✔ Synced feeds
6.3 - Air-Gapped
For any deployment which is air-gapped, a release compatible AnchoreCTL should be used when downloading the required datasets from
the Anchore Data Service and then again uploading them to your Anchore Enterprise deployment.
For more detail regarding the Anchore Data Service, please see Anchore Data Service.

Configuration
To configure your Anchore Enterprise deployment to work in an air-gapped environment, you will need to disable the Data Syncer Service’s automatic feed sync.
For helm
Set the following in your values.yaml
dataSyncer:
extraEnv:
- name: ANCHORE_DATA_SYNC_AUTO_SYNC_ENABLED
value: "false"
Nginx ingress
Please note that when using an nginx ingress you may need the following to allow the large file upload required for air-gap feed upload:
ingress:
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: "0"
nginx.ingress.kubernetes.io/proxy-read-timeout: "3600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "3600"
For docker-compose
Set the following in your docker compose yaml file
services:
data-syncer:
environment:
- ANCHORE_DATA_SYNC_AUTO_SYNC_ENABLED=false
Auto Sync Disabled Log
To confirm auto sync is disabled the following log will be emitted by the data-syncer service upon startup (in the event you wanted to double check):
[INFO] [anchore_enterprise.services.data_syncer.service/handle_data_sync():33] | Auto sync is disabled. Skipping data sync.
Downloading and Importing Datasets
Note
For downloading and uploading datasets using anchoreCTL, ensure you have greater than 2GB of free space in the current working directory of your host system in which you are saving the bundle.Once installed, AnchoreCTL can be used to download the latest feed data from the Anchore Data Service. This data can then be moved across the air
gap and uploaded into your Anchore Enterprise deployment.
Downloading the Datasets
Run the following command outside your air-gapped environment to download the datasets
Using your license key
anchorectl airgap feed download -f <filename> -k <your api key>
Using your license file
anchorectl airgap feed download -f <filename> -l <path to your license file>
- To get your API key, check your license file for a field called
apiKey - This command will download all the feeds from the hosted service to the file specified by ‘-f’.
- This command can take a bit of time to return depending on your connection speed.
- The resulting file will be approximately 0.5 GB in size as of this writing but will continue to grow as more data is added to the feeds.
Importing the Datasets
Take a copy of this file and move it into your air-gapped environment. Then run the following command to import the feeds into your Anchore Enterprise deployment.
anchorectl airgap feed upload -f <filename>
Your Analyzer Service and Policy Engine Service will now be able to fetch the latest data from the Data Syncer Service as normal.
This procedure must be repeated each time you want to update the datasets in your air gapped environment.
Note
Use the same file for downloading data every time. AnchoreCTL will read the metadata from the file and determine if it needs to download any newer data or if you already have the latest. If it does download newer data, the metadata in the file is overwritten with the latest metadata, this way you will not have to perform any unnecessary downloads.6.4 - Status Page
A live status page is available for real-time updates on the Anchore Data Service, including information on outages, maintenance, and options for subscribing to notifications.
You can access the status page at https://status.anchore-enterprise.com

The status page is updated in real-time and provides information on the following:
- Current Status - The current status of the Anchore Data Service.
- Incidents - A list of any ongoing incidents that may be affecting the Anchore Data Service.
- Scheduled Maintenance - A list of any upcoming maintenance windows that may affect the Anchore Data Service.
- Subscribe to Updates - Options for subscribing to updates via email, SMS, or webhook.
- Past Incidents - A list of past incidents that have affected the Anchore Data Service.
- Historical Uptime - Historical uptime data for the Anchore Data Service.
The status page does not auto refresh. You have to refresh it manually to see the latest status.
7 - Integration
Overview
Anchore Enterprise exposes an API through which external software entities like inventory
agents can report their health status. These software entities (agents, plugins etc.) serve
as a mechanism for external systems like Kubernetes clusters or container image repositories
to integrate with Anchore Enterprise.
Enterprise refer these software entities simply as integrations. A deployed Kubernetes
Inventory agent is example of an integration instance. A deployed Kubernetes Admission
Controller is another example of an integration instance.
Integration health reporting
An integration instance can send health reports to Anchore Enterprise, which in turn maintains
a record of those health reports. They are used by Enterprise to determine the status of the
integration instances.
An integration instance can send a health report at most every 30 seconds. To prevent
unlimited growth of stored health reports, Anchore’s Catalog Service will prune old health
reports.
The configuration setting below allow you to specify how long health reports should be
kept by Catalog Service. This is the default setting found in the values file.
services:
catalog:
integrations:
integration_health_report_ttl_days: 2
8 - Logging Configuration
Anchore services produce detailed logs that contain information about user interactions, internal processes, warnings and errors.
Log Level
The verbosity of the logs is controlled using the logging.log_level setting in config.yaml (for manual installations) or the corresponding ANCHORE_LOG_LEVEL environment variable (for docker compose or Helm installations) for each service.
The log levels are DEBUG, INFO, WARNING, ERROR, and CRITICAL, where the default is INFO. Most of the time, the default level is sufficient as the logs will container WARNING, ERROR and CRITICAL messages as well. But for deep troubleshooting, it is always recommended to increase the log level to DEBUG in order to ensure the availability of the maximum amount of information.
Changing Log Level via the API
The log level can be adjusted via the API without having to redeploy services:
echo '[{ "service_name": "all", "logging_level": "debug" }]' > log_level.json
curl -u {admin_user}:{admin_pass} -X POST -H 'Content-Type: application/json' -d @log_level.json http://localhost:8228/v2/system/logging
Changing Log Level via the UI
The log level can also be modified by a user with the system configuration permissions by navigating to System -> Configuration. Each service’s log level can be configured individually. Example for Analyzer Log Level:

Structured Logging (JSON)
Anchore services can be configured to log in JSON format. This is particularly helpful if users ship logs to an external log aggregator.
Helm
With our Helm chart’s values.yaml, users can change the structured logging boolean in the following section:
anchoreConfig:
[...]
logging:
[...]
structured_logging: true
Docker
With Docker Compose, users will need to mount the config.yaml file into the containers with the following section modified to enable structured logging:
logging:
[...]
structured_logging: true # Enable structured logging output (JSON)
Mounting config.yaml file in Docker
To obtain the default config.yaml file that can then be modified and remounted, first get the file from the Enterprise image:
docker create --name temp docker.io/anchore/enterprise:{version}
docker cp temp:/config/config.yaml config.yaml
docker rm -f temp
Make the modifications in the config.yaml to enable structured logging, and mount it to each service. The following is an example for the API service, but for each service that structured logging needs to be enabled on, the config.yaml will need to be mounted similarly as a volume:
# The primary API endpoint service
api:
[...]
volumes:
- ./license.yaml:/license.yaml:ro
- ./config.yaml:/config/config.yaml:ro
Audit Logging
Anchore Enterprise includes comprehensive audit logging capabilities that track security-sensitive operations and administrative changes across the system. Audit logs provide a detailed record of who performed what actions, when they occurred, and their outcomes, which is essential for compliance, security monitoring, and forensic analysis.
Overview
The audit logging feature captures and records:
- User authentication and authorization events
- Account and user management operations
- RBAC (Role-Based Access Control) changes
- API key management
- SAML/SSO configuration changes
- User group modifications
Audit logs are written to the standard logging output with a special “AUDIT” log level, making them easily distinguishable from regular application logs. Each audit event includes detailed context about the request, the authenticated user, and the response.
Configuration
Helm Chart Configuration
When deploying Anchore Enterprise with Helm, audit logging is configured through the values.yaml file. The audit feature is enabled by default in the Helm chart:
anchoreConfig:
# Audit logging configuration
audit:
enabled: true # Enable or disable audit logging (default: true)
additionalResourceURIs: [] # List of additional resource URIs to audit (available from chart v3.14.2 / Enterprise v5.20.2)
# - "/images"
# - "/images/{imageDigest}"
# - "/registries"
# - "/registries/{registry}"
Info
Configuring audit logging for additional URIs (such as /images) can introduce a performance overhead on the system. Consider auditing only your required actions.The Helm chart automatically configures the full audit settings in the generated config.yaml:
- Mode: Set to
log (currently the only supported mode) - Verbs: Configured to audit POST, PUT, DELETE, and PATCH operations
- Resource URIs: Pre-configured with all security-sensitive endpoints including:
- Account management endpoints (
/accounts/*) - User management endpoints (
/accounts/{account_name}/users/*) - API key endpoints (
/user/api-keys/*) - RBAC and role management (
/rbac-manager/*) - SAML/SSO configuration (
/rbac-manager/saml/*) - User group management (
/system/user-groups/*) - Credential endpoints (
/user/credentials)
To add additional endpoints to audit beyond the default list (requires Helm chart v3.14.2+ with Anchore Enterprise v5.20.2+):
anchoreConfig:
audit:
enabled: true
additionalResourceURIs:
- "/images"
- "/images/{imageDigest}"
- "/registries"
- "/registries/{registry}"
Note: The additionalResourceURIs field was introduced in Helm chart version 3.14.2 along with Anchore Enterprise version 5.20.2. For earlier versions, you’ll need to use a configOverride to customize the audited endpoints.
Example using configOverride for full customization:
configOverride: |
audit:
enabled: true
mode: log
verbs:
- post
- put
- delete
- patch
resource_uris:
# Default endpoints
- "/accounts"
- "/accounts/{account_name}"
- "/accounts/{account_name}/state"
- "/accounts/{account_name}/users"
- "/accounts/{account_name}/users/{username}"
- "/accounts/{account_name}/users/{username}/api-keys"
- "/accounts/{account_name}/users/{username}/api-keys/{key_name}"
- "/accounts/{account_name}/users/{username}/credentials"
- "/rbac-manager/roles"
- "/rbac-manager/roles/{role_name}/members"
- "/rbac-manager/saml/idps"
- "/rbac-manager/saml/idps/{name}"
- "/rbac-manager/saml/idps/{name}/user-group-mappings"
- "/system/user-groups"
- "/system/user-groups/{group_uuid}"
- "/system/user-groups/{group_uuid}/roles"
- "/system/user-groups/{group_uuid}/users"
- "/user/api-keys"
- "/user/api-keys/{key_name}"
- "/user/credentials"
# Custom additional endpoints
- "/images"
- "/images/{imageDigest}"
- "/registries"
- "/registries/{registry}"
To disable audit logging in Helm deployments:
anchoreConfig:
audit:
enabled: false
Important Note: When specifying resource URIs (both in configuration files and additionalResourceURIs), do not include the /v2 API version prefix. The audit system automatically handles API versioning. For example:
- Correct:
/accounts/{account_name}/users - Incorrect:
/v2/accounts/{account_name}/users
Environment Variables
For container deployments using Docker Compose, audit logging can be configured using environment variables:
ANCHORE_AUDIT_ENABLED=true
ANCHORE_AUDIT_MODE=log
ANCHORE_AUDIT_VERBS="post,put,delete,patch"
Note: Environment variable configuration for audit logging is limited. For full control over audit settings, including custom resource URIs, you should mount a custom config.yaml file.
Each audit log entry contains the following information:
{
"request": {
"method": "POST",
"url": "https://anchore.example.com/v2/accounts/engineering/users",
"data": {
"username": "newuser",
"email": "[email protected]"
},
"request_id": "550e8400-e29b-41d4-a716-446655440000"
},
"auth": {
"username": "admin",
"account": "admin"
},
"response": {
"code": 200,
"message": "User created successfully"
}
}
Log Entry Fields
- request: Details about the incoming request
- method: HTTP method used (GET, POST, PUT, DELETE, etc.)
- url: Full URL of the request
- data: Request body data (sanitized for sensitive endpoints)
- request_id: Unique identifier for request tracing
- auth: Authentication context
- username: Username of the authenticated user
- account: Account name the user belongs to
- response: Details about the response
- code: HTTP status code
- message: Response message or error details
Sensitive Data Handling
The audit logging system automatically sanitizes sensitive data to prevent exposure of secrets:
- Password fields are removed from logged request data
- API keys and tokens are redacted
- Credentials endpoints have their data completely redacted
- Registry passwords, webhook secrets, and SMTP passwords are sanitized
The following endpoints have special handling for sensitive data:
/user/credentials - All data redacted/accounts/{account_name}/users/{username}/credentials - All data redacted/oauth/token - Sensitive fields removed/registries/* - Passwords and credentials sanitized/notifications/endpoints/*/configurations - Secrets and tokens sanitized
Filtering and Searching Audit Logs
Since audit logs use a special “AUDIT” log level, they can be easily filtered from regular application logs. When using structured logging (JSON format), you can search and filter audit logs using standard log aggregation tools.
Example filtering with grep:
grep "AUDIT" anchore-api.log | jq '.'
Example with journalctl (for systemd-based systems):
journalctl -u anchore-api | grep AUDIT
Compliance and Best Practices
Enable audit logging in production: Always enable audit logging in production environments to maintain a security trail.
Protect audit logs: Ensure audit logs are stored securely and have appropriate access controls. Consider shipping them to a centralized, tamper-resistant logging system.
Regular review: Establish processes to regularly review audit logs for suspicious activities or unauthorized access attempts.
Retention policy: Define and implement a log retention policy that meets your compliance requirements. Many regulations require audit logs to be retained for specific periods.
Monitor failed authentication: Pay special attention to authentication failures (401 responses) which may indicate attempted unauthorized access.
Avoid wildcard auditing: While you can use "*" to audit all endpoints, this is not recommended in production as it can generate excessive log volume and may impact performance.
Troubleshooting
If audit logs are not appearing:
- Verify audit logging is enabled in your configuration
- Check that the endpoints you’re testing match the configured
resource_uris - Ensure the HTTP methods match the configured
verbs - Verify the service has been restarted after configuration changes
- Check the overall log level - audit logs require at least INFO level logging
9 - Custom Certificate Authority
When Anchore Enterprise needs to communicate with external HTTPS endpoints like container registries, Anchore’s data feed service, or LDAP servers. If your environment uses a transparent SSL/TLS inspection proxy (a “man-in-the-middle” proxy) or service endpoints that use a self-signed certificates, you must provide the appropriate Custom Certificate Authority (CA) to avoid SSL/TLS verification errors.
This guide explains how to identify the need for a custom CA as well as how to configure your Docker Compose or Kubernetes deployments to utilize them.
🩺 Diagnosis and Preparation
Before you begin to configure Anchore Enterprise, confirm if a custom CA is necessary. If a CA certificate is required, we show you how to get the certificate for use in later steps.
Do I Need a Custom CA?
You can test for SSL verification issues by running a curl command from a host or container within your environment. If the command fails with a certificate verification error, you likely need to add a custom CA. A good test is to try connecting to Anchore’s public data service feed:
# -v enables verbose output to show SSL handshake details
curl -v https://data.anchore-enterprise.com
# An error might look like -> curl: (60) SSL certificate problem: self signed certificate in certificate chain indicates a CA is missing.
Note
For private container registries, you can often bypass certificate validation by enabling the “Allow Self-Signed” (skip TLS verify) option in the registry configuration within the Anchore Enterprise UI or via AnchoreCTL. However, using a custom CA is the more secure and recommended approach.How Do I Get the CA Certificate?
If you’ve confirmed a custom CA is needed, you can fetch it from the target server using openssl. The certificate should be created with the .pem extension and then mounted into the relevant Anchore Enterprise container(s).
# Replace data.anchore-enterprise.com with your server's hostname
openssl s_client -showcerts -servername data.anchore-enterprise.com -connect data.anchore-enterprise.com:443 > custom-ca.pem
You can then verify that the fetched certificate works by using it with curl:
# Replace data.anchore-enterprise.com with your server's hostname
curl -v --cacert custom-ca.pem https://data.anchore-enterprise.com
# A success message might look like -> * SSL certificate verify ok.
Note
You might need to perform this task multiple times if you have a different self-signed certs in use across services as well as tls/ssl proxy in your environment.🐳 Docker Compose
The entrypoint scripts in the Anchore Enterprise containers are designed to automatically detect and trust any certificates mounted into the /home/anchore/certs directory.
Update your Core Services:
For each Anchore service (e.g., api, catalog, policy-engine, etc.), mount your custom-ca.pem file as a volume.
# Add this volume to each core Anchore service in your docker-compose.yaml
services:
api:
image: docker.io/anchore/enterprise:v5.X.X
volumes:
- ./custom-ca.pem:/home/anchore/certs/custom-ca.pem:ro
# ... repeat for other services
Update your UI Service:
The UI service is a Node.js application and requires an additional environment variable, NODE_EXTRA_CA_CERTS, to load the certificate. This cert could be used for connectivity to services such as LDAP.
# Add both the volume and the environment variable to the UI service
services:
ui:
image: docker.io/anchore/enterprise-ui:v5.X.X
volumes:
- ./custom-ca.pem:/home/anchore/certs/custom-ca.pem:ro
environment:
- NODE_EXTRA_CA_CERTS=/home/anchore/certs/custom-ca.pem
☸️ Kubernetes (Helm)
For Helm deployments, you first store your certificate(s) in a Kubernetes secret and then reference that secret in your values.yaml.
Create a Kubernetes Secret
Create a generic secret in the same namespace as your Anchore Enterprise deployment. You can include multiple CA certificates in a single secret if needed.
# Replace 'anchore' with your namespace if different
# Add multiple --from-file flags for multiple certificates
kubectl create secret generic custom-ca-certs \
--from-file=my-registry-ca.pem=./custom-ca.pem \
--from-file=my-ldap-ca.pem=./ldap-ca.pem \
--from-file=my-db-ca.pem=./my-db-ca.pem \
-n anchore
Update your Helm values
Now change your Helm values to use the secret containing the CA cert. The certStoreSecretName key is used to mount the secret’s contents into the trusted certificate path. You can then reference each specific CA certificate file as needed. Once you have modified your values to utilize the secret and relvant CA certificate files, perform a helm upgrade. Below is an example values.yaml configuration:
# Name of secret containing the certificates & keys used for SSL, SAML & CAs
certStoreSecretName: "custom-ca-certs"
# Example: Reference a specific CA for the UI's LDAPS connection
ui:
# Setting this creates the required NODE_EXTRA_CA_CERTS
ldapsRootCaCertName: "my-ldap-ca.pem"
# Example: Reference a specific CA for the database connection
anchoreConfig:
database:
ssl: true
sslRootCertFileName: "my-db-ca.pem"
Note
There are other certs you can supply and configure such as anchoreConfig.internalServicesSSL & anchoreConfig.keys.privateKeyFileName10 - Network Proxies
As covered in the Network sections of the requirements document, Anchore requires three categories of network connectivity.
Registry Access
Network connectivity, including DNS resolution, to the registries from which Anchore needs to download images.
Feed Service
Anchore synchronizes feed data such as operating system vulnerabilities (CVEs) from Anchore Cloud Service. See Feeds Overview for the full list of endpoints.
Access to Anchore Internal Services
Anchore is composed of six smaller services that can be deployed in a single container or scaled out to handle load. Each Anchore service should be able to connect the other services over the network.
In environments were access to the public internet is restricted then a proxy server may be required to allow Anchore to connect to Anchore Cloud Feed Service or to a publicly hosted container registry.
Anchore can be configured to access a proxy server by using environment variables that are read by Anchore at run time.
https_proxy:
Address of the proxy service to use for HTTPS traffic in the following form: {PROTOCOL}://{IP or HOSTNAME}:{PORT}
eg. https://proxy.corp.example.com:8128
http_proxy:
Address of the proxy service to use for HTTP traffic in the following form: {PROTOCOL}://{IP or HOSTNAME}:{PORT}
eg. http://proxy.corp.example.com:8128
no_proxy:
Comma delimited list of hostnames or IP address which should be accessed directly without using the proxy service.
eg. localhost,127.0.0.1,registry,example.com
Environment Variables to Control Proxy Behavior
- Setting the endpoints to HTTP proxy:
- Set both
HTTP_PROXY and http_proxy environment variables for regular HTTP protocol use. - Set both
HTTPS_PROXY and https_proxy environment variables for HTTP + TLS (HTTPS) protocol use.
- Setting endpoints to exclude from proxy use:
- Set both
NO_PROXY and no_proxy environment variables to exclude those domains from proxy use defined in the preceding proxy configurations.
If using Docker Compose these need to be set in each service entry.
If using Helm Chart, set these in the extraEnv entry for each service.
Notes:
- Do not use double quotes (") around the proxy variable values.
Authentication
For proxy servers that require authentication the username and password can be provided as part of the URL:
eg. https_proxy=https://user:[email protected]:8128
If the username or password contains and non-url safe characters then these should be urlencoded.
For example:
The password F@oBar! would be encoded as F%40oBar%21
Setting Environment Variables
Docker Compose: https://docs.docker.com/compose/environment-variables/
An example - You would need these entries for each service. Please tweak the example for your environment.
environment:
- http_proxy=http://my-proxy.domain:8080
- https_proxy=http://my-proxy.domain:8080
- no_proxy=localhost, localhost.localdomain, 127.0.0.1, analyzer, anchore-db, api, catalog, notifications, policy-engine, queue, reports, reports-worker, ui-redis, ui, data-syncer, swagger-ui, prometheus, *.my-registry.domain
- HTTP_PROXY=http://my-proxy.domain:8080
- HTTPS_PROXY=http://my-proxy.domain:8080
- NO_PROXY=localhost, localhost.localdomain, 127.0.0.1, analyzer, anchore-db, api, catalog, notifications, policy-engine, queue, reports, reports-worker, ui-redis, ui, data-syncer, swagger-ui, prometheus, *.my-registry.domain
Kubernetes: https://kubernetes.io/docs/tasks/inject-data-application/define-environment-variable-container/
An example - You can set this in your Helm values.yaml file at the global level. Please tweak the example for your environment.
extraEnv:
- name: http_proxy
value: http://my-proxy.domain:8080
- name: https_proxy
value: http://my-proxy.domain:8080
- name: no_proxy
value: 'localhost, 127.0.0.1, cluster.local, anchore-enterprise-api, anchore-enterprise-catalog, anchore-enterprise-datasyncer, anchore-enterprise-notifications, anchore-enterprise-policy, anchore-enterprise-reports, anchore-enterprise-reportsworker, anchore-enterprise-reportsworker, anchore-enterprise-ui, anchore-postgresql, anchore-ui-redis-headless, anchore-ui-redis-master, anchore-postgresql-hl'
- name: HTTP_PROXY
value: http://my-proxy.domain:8080
- name: HTTPS_PROXY
value: http://my-proxy.domain:8080
- name: NO_PROXY
value: 'localhost, 127.0.0.1, cluster.local, anchore-enterprise-api, anchore-enterprise-catalog, anchore-enterprise-datasyncer, anchore-enterprise-notifications, anchore-enterprise-policy, anchore-enterprise-reports, anchore-enterprise-reportsworker, anchore-enterprise-reportsworker, anchore-enterprise-ui, anchore-postgresql, anchore-ui-redis-headless, anchore-ui-redis-master, anchore-postgresql-hl'
Deployment Architecture Notes
When setting up a network proxy, keep in mind that you will need to explicitly allow inter-service communication within the Anchore Enterprise deployment to bypass the proxy, and potentially other hostnames as well (e.g. internal registries) to ensure that traffic is directed correctly. In general, all Anchore Enterprise service endpoints (the URLs for enabled services in the output of an ‘anchorectl system status’ command) as well as any internal registries (the hostnames you may have set up with ‘anchorectl registry add –username …’ or as part of an un-credentialed image add ‘anchorectl image add registry:port/….’), should not be proxied (i.e. added to the no_proxy list, as described above).
If you wish to tune this further, below is a list of each component that makes an external URL fetch for various purposes:
- Catalog: makes connections to image registries (any host added via ‘anchorectl registry add’ or directly via ‘anchorectl image add’)
- Analyzer: same as catalog
- Data Syncer: by default connects to Anchore Data Service for downloading vulnerability datasets. See Data Feeds and Data Synchronization for more details.
11 - TLS / SSL
The following sections describe how to configure TLS for Anchore API and/or Anchore Enterprise Services.
Please note that the UI service currently does not support listening via TLS.
Internal TLS for Anchore Enterprise Services Helm deployments
graph TB
subgraph External Traffic
user[User]
kubernetes[Ingress Controller]
end
subgraph Services with Internal TLS
api[API]
policy[Policy]
catalog[Catalog]
analyzer[Analyzer]
reports[Reports]
reportsworker[Reports Worker]
notifications[Notifications]
dataSyncer[Data Syncer]
simplequeue[Simple Queue]
end
subgraph Services Without TLS
ui[UI]
end
user -- HTTP/HTTPS --> kubernetes
kubernetes -- HTTPS --> api
kubernetes -- HTTP --> ui
api <--> policy
api <--> catalog
api <--> analyzer
api <--> reports
api <--> reportsworker
api <--> notifications
api <--> dataSyncer
api <--> simplequeue
policy <--> catalog
catalog <--> analyzer
analyzer <--> reports
reports <--> reportsworker
reportsworker <--> notifications
notifications <--> dataSyncer
dataSyncer <--> simplequeueThe following will configure Anchore Enterprise internal services to communicate with one another via TLS.
This script is provided as a demonstration of how to generate certificates (generate-anchore-tls-certs.sh):
#!/bin/bash
export NAMESPACE="$1";
export RELEASE="$2";
export SANS="DNS:*.${NAMESPACE}.svc.cluster.local,DNS:${RELEASE}-enterprise-api,DNS:${RELEASE}-enterprise-catalog,DNS:${RELEASE}-enterprise-notifications,DNS:${RELEASE}-enterprise-policy,DNS:${RELEASE}-enterprise-reports,DNS:${RELEASE}-enterprise-reportsworker,DNS:${RELEASE}-enterprise-simplequeue,DNS:${RELEASE}-enterprise-ui,DNS:${RELEASE}-enterprise-datasyncer"
# NOTE: This ends up being the filename of resulting certificates
SERVER_NAME="anchore"
ANCHORE_TLS=./anchore-tls
SCRIPT=$(readlink -f "$0")
DIR=$(dirname "$SCRIPT")
echo "Making ANCHORE_TLS dir..."
mkdir -p ${ANCHORE_TLS}
cd ${ANCHORE_TLS}
# Customize as needed
CORPORATION=Anchore
GROUP=K8S
CITY=Atlanta
STATE=Georgia
COUNTRY=US
CERT_AUTH_PASS=`openssl rand -base64 32`
echo $CERT_AUTH_PASS > cert_auth_password
CERT_AUTH_PASS=`cat cert_auth_password`
# create the certificate authority
openssl \
req \
-subj "/CN=$SERVER_NAME.ca/OU=$GROUP/O=$CORPORATION/L=$CITY/ST=$STATE/C=$COUNTRY" \
-new \
-x509 \
-passout pass:$CERT_AUTH_PASS \
-keyout ca-cert.key \
-out ca-cert.crt \
-days 3650
# create client private key (used to decrypt the cert we get from the CA)
openssl genrsa -out $SERVER_NAME.key
# create the CSR(Certitificate Signing Request)
openssl \
req \
-new \
-nodes \
-subj "/CN=$SERVER_NAME/OU=$GROUP/O=$CORPORATION/L=$CITY/ST=$STATE/C=$COUNTRY" \
-sha256 \
-extensions v3_req \
-reqexts SAN \
-key $SERVER_NAME.key \
-out $SERVER_NAME.csr \
-config <(cat /etc/ssl/openssl.cnf <(printf "[SAN]\nsubjectAltName=$SANS")) \
-days 3650
# sign the certificate with the certificate authority
openssl \
x509 \
-req \
-days 3650 \
-in $SERVER_NAME.csr \
-CA ca-cert.crt \
-CAkey ca-cert.key \
-CAcreateserial \
-out $SERVER_NAME.crt \
-extfile <(cat /etc/ssl/openssl.cnf <(printf "[SAN]\nsubjectAltName=$SANS")) \
-extensions SAN \
-passin pass:$CERT_AUTH_PASS
# Create key pem
cat $SERVER_NAME.key > $SERVER_NAME-key.pem
# Create cert pem
cat $SERVER_NAME.crt > $SERVER_NAME.pem
cat ca-cert.crt >> $SERVER_NAME.pem
cd ..
cat << EOF > anchore-tls-certs.yaml
---
apiVersion: v1
kind: Secret
metadata:
name: anchore-tls-certs
namespace: $NAMESPACE
type: Opaque
data:
internal-cert.pem: $(base64 anchore-tls/$SERVER_NAME.pem --wrap 0)
internal-cert-key.pem: $(base64 anchore-tls/$SERVER_NAME-key.pem --wrap 0)
ca.pem: $(base64 anchore-tls/ca-cert.crt --wrap 0)
EOF
kubectl apply -n $NAMESPACE -f anchore-tls-certs.yaml
If Custom CA certificates are required for LDAP or Postgres be sure to append them to the anchore-tls/ca-cert.crt & anchore-tls/anchore.pem file.
The script can be called as follows:
chmod +x generate-anchore-tls-certs.sh
# Provide values for your kubernetes namespace containing anchore and your helm release
./generate-anchore-tls-certs.sh $NAMESPACE $RELEASE
Make the following adjustments in your helm values file:
certStoreSecretName: anchore-tls-certs
anchoreConfig:
internalServicesSSL:
enabled: true
verifyCerts: false
certSecretKeyFileName: internal-cert-key.pem
certSecretCertFileName: internal-cert.pem
ui:
ldapsRootCaCertName: ca.pem
You will need to perform a Helm install or upgrade to apply all the changes and restart all the pods.
If using an ingress controller see the next section.
Separating API & UI Ingress for Helm deployments
If you are using ingress to access Anchore Enterprise API & Anchore Enterprise UI then you will need to seperate the ingress configuration if you configure either External or Internal TLS.
Since API supports TLS and UI does not once TLS is enabled for API the ingress controller will need to send encrypted traffic to API and unencrypted traffic to UI.
Make the following change to your helm values file to configure the ingress to use TLS to communicate with the API service:
ingress:
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
# These are optional
nginx.ingress.kubernetes.io/proxy-body-size: '0'
nginx.ingress.kubernetes.io/proxy-read-timeout: '600'
nginx.ingress.kubernetes.io/proxy-send-timeout: '600'
uiHosts: []
Add an ingress directly in kubernetes for the UI:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: anchore-ingress-ui
annotations:
# These are optional
nginx.ingress.kubernetes.io/proxy-body-size: '0'
nginx.ingress.kubernetes.io/proxy-read-timeout: '600'
nginx.ingress.kubernetes.io/proxy-send-timeout: '600'
spec:
ingressClassName: nginx # NOTE: This could be another value such as alb
tls: []
rules:
- host: anchore.yourdomain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: anchore-enterprise-ui # Ensure this matches the name of the Anchore UI service
port:
number: 80
Apply UI Ingress changes:
kubectl apply -n $NAMESPACE -f anchore-ingress-ui.yaml
External TLS for Anchore Enterprise API Service
Please note that configuring Internal TLS above also includes External TLS. If you performed the steps above then this is not necessary.
In the following example the external API service is configured to listen on port 443 and is configured with a certificate for its external hostname anchore.example.com
Each service published in the Anchore Enterprise configuration (apiext, catalog, simplequeue, analyzer, policy_engine and kubernetes_webhook) can be configured to use transport level security.
services:
apiext:
enabled: True
endpoint_hostname: 'anchore.example.com'
listen: '0.0.0.0'
port: 443
ssl_enable: True
ssl_cert: '/config/anchore-ex.crt'
ssl_key: '/config/anchore-ex.key'
ssl_chain: '/config/anchore-ex.crt'
| Setting | Notes |
|---|
| enabled | If the service is enabled |
| endpoint_hostname | DNS name of service |
| listen | IP address of interface on which the service should listen (use ‘0.0.0.0’ for all - default) |
| port | Port on which service should listen. |
| ssl_enable | Enable transport level security |
| ssl_cert | name, including full path of private key file. |
| ssl_chain | [optional] name, including full path of certificate chain |
The certificate files should be placed on a path accessible to the Anchore Enterprise service, for example in the /config directory which is typically mapped as a volume into the container. Note that the location outside the container will depend on your configuration - for example if you are volume mounting ‘/path/to/aevolume/config/’ on the docker host to ‘/config’ within the container, you’ll need to place the ssl files in ‘/path/to/aevolume/config/’ on the docker host, so that they are accessible in ‘/config/’ inside the container, before starting the service.
The ssl_chain file is optional and may be required by some certificate authorities. If your certificate authority provides a chain certificate then include it within the configuration.
Note: While a certificate may be purchased from a well-known and trusted certificate authority in some cases the certificate is signed by an intermediate certificate which is not included within a TLS/SSL clients trust stores. In these cases the intermediate certificate is signed by the certificate authority however without the full ‘chain’ showing the provenance and integrity of the certificate the TLS/SSL client may not trust the certificate.
Any certificates used by the Anchore Enterprise services need to be trusted by all other Anchore Enterprise services.
If an internal certificate authority is used the root certificate for the internal CA can be added to the Anchore Enterprise using the following procedure or SSL verification can be disabled by setting the following parameter:
internal_ssl_verify: True
12 - Notifications
Overview
Alert external endpoints (Email, GitHub, Slack, and more) about Anchore events such as policy evaluation results, vulnerability updates, and system errors with our new Notifications service. Configure notification endpoints and manage which specific events you need through Anchore Enterprise UI.
For more information on the Notifications Service in general, its concepts, and details on its configuration, please refer to the Notifications Service.
The following sections in this document describe the current endpoints available for configuration, the options provided for selecting events, the various actions you can do with a configuration (add, edit, test, and remove), and how to disable an endpoint as an admin.
Anchore Enterprise includes Notifications service to alert external endpoints about the system’s activity. Services that make up Anchore Enterprise generate events to record significant activity, such as an update, in the policy evaluation result or vulnerabilities for a tag, or an error analyzing an image. This service provides a mechanism to selectively notify events of interest to supported external endpoints. The actual notification itself depends on the endpoint - formatted message to Slack, email and MS Teams endpoints, tickets in GitHub and Jira endpoints, and JSON payload to webhook endpoint.
Glossary
- Event
- An information packet generated by Anchore Enterprise service to indicate some activity.
- Endpoint
- External tool capable of receiving messages such as Slack, GitHub, Jira, MS Teams, email or webhook.
- Endpoint Configuration
- Connection information of the endpoint used for sending messages.
- Selector
- Criteria for selecting events to be notified.
Installation
Anchore Enterprise Notifications is included with Anchore Enterprise, and is installed by default when deploying a trial quickstart with Docker Compose, or a production deployment Kubernetes.
Configuration
Enterprise Notifications Service
The service loads configuration from the notifications section of the config.yaml. See the following snippet of the configuration:
...
services:
notifications:
enabled: true
require_auth: true
endpoint_hostname: "<hostname>"
listen: '0.0.0.0'
port: 8228
cycle_timers:
notifications: 30
# Set Anchore Enterprise UI base URL to receive UI links in notifications
ui_url: "<enterprise-ui-url>"
The cycle_timers -> notifications controls how often the service checks for events in the system that need to be processed for notifications. Default is every 30 seconds.
The ui_url is used for constructing links to Enterprise UI pages in the notifications. Configure this property to the Enterprise UI’s base URL. This URL should be accessible from the endpoint receiving the notification for the links to work correctly. If the value is not set, the notification message is still be sent to the endpoint, but it won’t contain a clickable link to the Enterprise UI.
Note: Any changes to the configuration requires a restart of the service for the updates to take effect.
RBAC Permissions
In the Anchore Enterprise deployment, the table below lists the required actions and containing roles:
| Description | Action | Roles |
|---|
| List all the available notification endpoints and their status | listNotificationEndpoints | Read Only, Read Write |
| List all available configurations for an endpoint | listNotificationEndpointConfigurations | Read Only, Read Write |
| Get an endpoint configuration and associated selectors | getNotificationEndpointConfiguration | Read Only, Read Write |
| Create an endpoint configuration and associated selectors | createNotificationEndpointConfiguration | Read Write |
| Update an endpoint configuration and associated selectors | updateNotificationEndpointConfiguration | Read Write |
| Delete an endpoint configuration and associated selectors | deletetNotificationEndpointConfiguration | Read Write |
To send notifications to an external tool/endpoint, the service requires connection information to that endpoint. See the following for the required information for each endpoint:
Concepts
Endpoint Status
All endpoints in the Notifications service can be toggled as Enabled or Disabled. The endpoint status reflects the eabled or disabled state. By default, the status for all endpoints is enabled by default. Setting the endpoint status to disabled stops all notifications from going out to any configurations of that specific endpoint. This is a system-wide setting that can only be updated by the admin account. It is read-only for remaining accounts.
Endpoint Configuration
The endpoint configuration is the connection information such as URL, user credentials, and so on for an endpoint. The service allows multiple configurations per endpoint. Endpoint configurations are scoped to the account.
Selector
The services provides a mechanism to selectively choose notifications and route them to a configured endpoint. This is achieved using a Selector, which is a collection of filtering criteria. Each event is processed against a Selector to determine whether it is a match or not. If the Selector matches the event, a notification is sent to the configured endpoint by the service.
For a quick list of useful notifications and associated Selector configurations, see Quick Selection.
A Selector encapsulates the following distinct filtering criteria: scope, level, type, and resource type. Some allow a limited set of values, and others wildcards. The value for each criteria has to be set for the matching to compute correctly.
Scope
Allowed values: account, global
Events are scoped to the account responsible for the event creation.
account scope matches events associated with a user account.global scope matches events of any and all users. global scope is limited to admin account only. Non-admin account users can only specify account as the scope.
Level
Allowed values: info, error, *
Events are associated with a level that indicates whether the underlying activity is informational or resulted in an error. - info matches informational events such as policy evaluation or vulnerabilities update, image analysis completion and so on.
error matches failures such as image analysis failure.* will match all events.
Type
Allowed values: strings with or without regular expressions
Event types have a structured format <category>.<subcategory>.<event>. Thus, * matches all types of events. Category is indicative of the origin of the event.
system.* matches all system events.user.* matches events that are relevant to individual consumption.- Omitting an asterisk will do an exact match. See the GET /event_types route definition in the external API for the list of event types.
Resource Type
Allowed values: *, image_digest, image_tag, image_reference, repository, feeds, feed, feed_group, *
In most cases, events are generated during an operation involving a resource. Resource type is metadata of that resource. For instance image_tag is the resource type in a policy evaluation update event. * matches all resource types if you are uncertain what resource type to use.
Quick Selection
The following Selector configurations are for notifying a few interesting events.
| Receive | Scope | Level | Type | Resource Type |
|---|
| Policy evaluation and vulnerabilities updates | account | * | user.checks.* | * |
| User errors | account | error | user.* | * |
| User infos | account | info | user.* | * |
| Everything user related | account | * | user.* | * |
| System errors | account | error | system.* | * |
| System infos | account | info | system.* | * |
| Everything system related | account | * | system.* | * |
| All | account | * | * | * |
| All for every account (admin account only) | global | * | * | * |
Notifications UI Walkthrough

Supported Endpoints
- Email
- Send notifications to a specific SMTP mail service.
- GitHub
- Version control for software development using Git.
- JIRA
- Issue tracking and agile product management software by Atlassian.
- Slack
- Team collaboration software tools and online services by Slack Technologies.
- Teams
- Team collaboration software tools and online services by Microsoft.
- Webhook
- Send notifications to a specific API endpoint.
Event Selector Options

When adding or editing a configuration, selecting which events to be notified on can be as easy as choosing one of the above three options: All Notification Events, Policy & Vulnerability Events, or Error Events.
Advanced users can select Add Custom Selector for more granularity:

In the example shown, we configure to be notified on all system info events affecting any resource associated with the user’s account. For an in-depth explanation on the provided properties and their possible values, view our Selector documentation.
Adding a Configuration

If you haven’t already defined a configuration for an endpoint, simply click Let’s Add One! as shown above. Once you have, add additional configurations with Add New Configuration as shown below.

Upon doing so, a modal will appear with various properties shown on the left side. Note that based on the type of endpoint, these properties may differ.
To view the various requirements, check the documentation for Email, GitHub, JIRA, Slack, and Teams.

For more information on adding a custom selector, please view our Selector documentation.
Prior to saving your new configuration, feel free to test with the Test Configuration button. Then save with OK.
Note: If OK is not enabled, be sure all required fields have been filled out.
Editing a Configuration

The process to edit a configuration entry is started by clicking Edit which is found within the Actions column as shown above.

The various fields available for editing are the same shown when adding the configuration. For additional info on a specific field, hover over the provided question icon circled with an orange ring next to the field name.
At any time, you can select Cancel to disregard any changes you’ve made.
For testing any new changes prior to saving them, click Test Configuration.
To save your changes, click OK. If OK is not enabled, be sure all required fields have been filled out.
Testing a Configuration

When viewing your configurations, testing is easy - just look under the Actions column and click Test for that entry.

Otherwise, when adding or editing a configuration, search for the test button pictured above. It can be found near the bottom of the modal, next to the Cancel and OK buttons.
Removing a Configuration

To remove a specific notification configuration, simply click on the Remove button (as shown above) within the Actions column for that entry.
Select Yes to proceed with the deletion process or No to cancel. Please note that once you agree to remove the configuration, you won’t be able to recover it.
Admin-specific Actions

Disabling Endpoints
As an admin, navigate to System > Notifications and click on the toggle visible in the lower-right corner of the specific endpoint you’re aiming to disable.
By default, all endpoints (such as Email, Slack, and Webhook) are enabled out of the box. Disabling a specific endpoint requires admin privileges as it ensures all notifications are stopped from going out to any configuration for that endpoint system-wide.
Note that users are still able to add, edit, test, and remove notification configuration items, but no event messages will be sent for that endpoint until it is re-enabled.
12.1 - Slack
Notifications to Slack are in the form of messages to a channel.
Requirements
Do the following to receive Slack notifications.
- An Incoming Webhook URL is required. Follow instructions to create one.
- Copy the Incoming Webhook URL.
- Create a Slack endpoint configuration in the Notifications service either via Enterprise UI or the API directly.
12.2 - GitHub
Notifications to GitHub are in the form of new issues in a repository.
Requirements
Do the following to receive GitHub notifications.
- Provide the following required GitHub account and repository-related information.
- Username of the account for creating issues.
- Token with repository access. Follow instructions to create a new Access Token in the account used for creating issues.
- Name of the repository where the issues are created.
- Owner of the repository.
- (Optional) GitHub API URL, defaults to https://api.github.com if not specified.
- (Optional) milestone assigned to the issue.
- (Optional) one or more labels assigned to the issue.
- (Optional) one or more GitHub users assigned to the issue.
- Create a GitHub endpoint configuration in the Notifications service either via Enterprise UI, or the API directly.
12.3 - Jira
Notifications to Jira are in the form of new issues in a project.
Requirements
Do the following to receive Jira notifications.
- Provide the following required Jira account and project related information.
- URL of the Jira project.
- Username of the account for creating issues.
- API token or password depending on the Jira project.
- For Jira Cloud projects an API token is required. Follow instructions to create a new API token for the account creating issues.
- For Jira Self-managed projects password of the account creating issues is required.
- Project key, same as the prefix in the issue identifier. For instance, issue
TEST-1 has the project key TEST. - Type of the issue created such as
Bug, Task, Story, and so on. - (Optional) priority assigned to the issue such as
Low, Medium, High, and so on. - (Optional) one or more labels to be assigned to the issue.
- (Optional) Jira user to be assigned to the issue.
- Create a Jira endpoint configuration in the Notifications service either via Enterprise UI, or the API directly.
12.4 - SMTP
Notifications to SMTP server are in the form of html and plain text message packets.
Requirements
Do the following to receive SMTP notifications.
- Provide the following required SMTP server information.
- Host name/address
- Port number
- From address
- To address
- (Optional) username
- (Optional) password
- (Optional) use tls to encrypt connection
- Create an SMTP endpoint configuration in the Notifications service either via Enterprise UI, or the API directly.
12.5 - Microsoft Teams
Notifications to Microsoft Teams are in the form of messages to a channel.
Requirements
Do the following to receive Microsoft Teams notifications.
- An incoming webhook URL is required. See the Microsoft instructions to create one.
- Copy the incoming webhook URL.
- Create a Microsoft Teams endpoint configuration in the Notifications service either via Enterprise UI, or the API directly.
12.6 - Webhook
Anchore Enterprise uses outgoing webhooks to send event notifications to external services. When a webhook is triggered, Anchore makes a POST request to the registered URL.
| Header | Value |
|---|
| Content-Type | application/json |
| Authorization | Basic (if configured) |
| User-Agent | python-requests/x.x.x |
| Accept | / |
Payload Example
The following represents a payload example in the body of the webhook POST request:
{
"id": "string",
"type": "string",
"level": "string",
"message": "string",
"details": {
"msg": "string"
},
"timestamp": "ISO-8601 string",
"resource": {
"account_name": "string",
"type": "string",
"id": "string | null"
},
"source": {
"request_id": "string | null",
"service_name": "string",
"host_id": "string",
"base_url": "string"
}
}
Payload Details
According to the example above, the fields are described as follows:
| Field | Description |
|---|
| id | Unique identifier of the webhook event |
| type | Event type (e.g., system.test.random_wisdom, policy_eval, analysis_update) |
| level | Severity level (info, warn, error) |
| message | Human-readable description of the event |
| details | Object containing additional event-specific data |
Details regarding where the resource and event type:
| Field | Description |
|---|
| timestamp | Event timestamp in ISO-8601 format |
| account_name | Anchore account where the event originated |
| type | Type of resource (e.g., wisdom, image, policy) |
| id | Identifier for the resource (nullable) |
Details regarding the source of the event:
| Field | Description |
|---|
| request_id | ID of the request (nullable) |
| service_name | Anchore service that generated the event |
| host_id | Pod or container identifier |
| base_url | Base URL of the Anchore API |
Example Payload
{
"id": "211c5fff5641456d935e60f905c46a66",
"type": "system.test.random_wisdom",
"level": "info",
"message": "Unsolicited random wisdom of the moment",
"details": {
"msg": "It is better to keep your mouth closed and let people think you are a fool than to open it and remove all doubt - Mark Twain"
},
"timestamp": "2025-10-01T09:08:54.749806",
"resource": {
"account_name": "admin",
"type": "wisdom",
"id": null
},
"source": {
"request_id": null,
"service_name": "apiext",
"host_id": "anchore-enterprise-api-b7d8c686b-p6wbr",
"base_url": "http://anchore-enterprise-api.anchore.svc.cluster.local:8228"
}
}
Example of failed analysis
This is a notification due to an image not found in registry.
{
"id": "5fb694f3c245447cb1302ec412b490fe",
"source": {
"service_name": "catalog",
"host_id": "anchore-enterprise-catalog-5654fb8d84-5ln8r",
"base_url": "http://anchore-enterprise-catalog.anchore.svc.cluster.local:8082",
"request_id": null
},
"resource": {
"account_name": "admin",
"id": "docker.io/sopuru24/alpine:latest",
"type": "image_reference"
},
"type": "system.image_analysis.registry_lookup_failed",
"level": "error",
"message": "Referenced image not found in registry",
"details": {
"anchore_error_json": {
"message": "cannot fetch image digest/manifest from registry",
"detail": {
"raw_exception_message": "could not get manifest/digest for image (docker.io/sopuru24/alpine:latest) from registry (https://index.docker.io) - error: Error encountered in skopeo operation. cmd=/bin/sh -c skopeo inspect --raw --tls-verify=true --creds \"${SKOPUSER}\":\"${SKOPPASS}\" docker://docker.io/sopuru24/alpine:latest, rc=2, stdout=None, stderr=b'time=\"2025-10-01T10:43:27Z\" level=fatal msg=\"Error parsing image name \\\\\"docker://docker.io/sopuru24/alpine:latest\\\\\": reading manifest latest in docker.io/sopuru24/alpine: manifest unknown\"\\n', error_code=REGISTRY_IMAGE_NOT_FOUND",
"error_codes": []
},
"httpcode": 400
}
},
"timestamp": "2025-10-01T10:43:27.011960Z"
}
13 - Reports
Overview
Anchore Enterprise Reports aggregates data to provide insightful analytics and metrics for account-wide artifacts.
The service employs GraphQL to expose a rich API for querying the aggregated data and metrics.
Note
This service captures a snapshot of artifacts in Anchore Enterprise at a given point in time. Therefore, analytics and metrics computed by the service are not in real time, and may not reflect most up-to-date state in Anchore Enterprise.Installation
Anchore Enterprise Reports is included with Anchore Enterprise, and is installed by default when deploying a trial
quickstart with Docker Compose, or a production deployment
Kubernetes.
How it works
One of the main functions of Anchore Enterprise Reports is aggregating data. The service keeps a summary of all current
and historical images and tags for every account known to Anchore Enterprise. It also maintains vulnerability reports
and policy evaluations generated using the active bundle for all the images and tags respectively.
Note
Anchore Enterprise Reports shares a persistence layer with Anchore Enterprise. Ensure sufficient storage is provisioned.Configuration
Anchore Enterprise Reports are broken up into two services:
- The
reports_worker service which is responsible for the ingress and egress of data into our reports. - The
reports service which is responsible for the report generation.
Each service has a configuration section in the values file. Below are sample configurations and the default values.
...
services:
reports_worker:
# Set enable_data_ingress to true for periodically syncing data from anchore enterprise into the reports service
enable_data_ingress: true
# Set enable_data_egress to true to periodically remove reporting data that has been removed in other parts of system
enable_data_egress: false
# data_egress_window defines a number of days to keep reporting data following its deletion in the rest of system.
# Default value of 0 will remove it on next task run
data_egress_window: 0
# data_refresh_max_workers is the maximum number of concurrent threads to refresh existing results (etl vulnerabilities and evaluations) in reports service. Set non-negative values greater than 0, otherwise defaults to 10
data_refresh_max_workers: 10
# data_load_max_workers is the maximum number of concurrent threads to load new results (etl vulnerabilities and evaluations) to reports service. Set non-negative values greater than 0, otherwise defaults to 10
data_load_max_workers: 10
cycle_timers:
# Timers that describe how often each operation should run
reports_image_load: 600 # MIN 300 MAX 100000 Default 600
reports_tag_load: 600 # MIN 300 MAX 100000 Default 600
reports_runtime_inventory_load: 600 # MIN 300 MAX 100000 Default 600
reports_extended_runtime_vuln_load: 1800 # MIN 300 MAX 100000 Default 1800
reports_image_refresh: 7200 # MIN 3600 MAX 100000 Default 7200
reports_tag_refresh: 7200 # MIN 3600 MAX 100000 Default 7200
reports_metrics: 3600 # MIN 1800 MAX 100000 Default 3600
reports_image_egress: 600 # MIN 300 MAX 100000 Default 600
reports_tag_egress: 600 # MIN 300 MAX 100000 Default 600
runtime_report_generation:
# Provides the ability to enable/disable individual runtime report loading.
inventory_images_by_vulnerability: true
vulnerabilities_by_k8s_namespace: true
vulnerabilities_by_k8s_container: true
vulnerabilities_by_ecs_container: true
reports:
# GraphiQL is a GUI for editing and testing GraphQL queries and mutations.
# Set enable_graphiql to true and open http://<host>:<port>/v2/reports/graphql in a browser for reports API
enable_graphiql: true
# This is the number of execution threads which will be used during report generation.
max_async_execution_threads: 1
# Configure async_execution_timeout to adjust how long a scheduled query must be running for before it is considered timed out
# This may need to be adjusted if the system has large amounts of data and reports are being prematurely timed out.
# The value should be a number followed by "w", "d", or "h" to represent weeks, days or hours
async_execution_timeout: "48h"
# Set use_volume to `true` to have the reports worker buffer report generation to disk instead of in memory. This should be configured
# in production systems with large amounts of data (10s of thousands of images or more). Scratch volumes should be configured for the reports pods
# when this option is enabled.
use_volume: false
Any changes to the configuration requires a restart of the service for the updates to take effect.
In an Anchore Enterprise deployment, any non-admin account user must at least have listImages permission
to execute queries against Reports API. There RBAC Role available called report-admin which provides permissions to administer reports and schedules. Please see Role-Based Access Control
for more information.
Data ingress
Reports_worker service handles data ingress from Anchore Enterprise via the following asynchronous processes triggered
periodically:
Loader: Compares the working set of images and tags in Anchore Enterprise with its own records. Based on the
difference, images and tags along with the vulnerability report and policy evaluations are loaded into the service.
Artifacts deleted from Anchore Enterprise are marked inactive in the service.
This process is triggered periodically as described by the cycle timers listed above.
Refresher: Refreshes the vulnerability report and policy evaluations of all the images and tags actively
maintained by the service.
This process is triggered periodically as described by the cycle timers listed above.
Reports service may miss updates to artifacts if they are added and deleted in between consecutive ingress processes.
Data ingress is enabled by default. It can be turned off with enable_data_ingress: false in the config.yaml snippet
shown previously. In a quickstart deployment, add ANCHORE_ENTERPRISE_REPORTS_ENABLE_DATA_INGRESS=false to the
environment variables section of the reports service in docker-compose.yaml. When the ingress is turned off, Reports
service will no longer aggregate data from Anchore Enterprise, metric computations will also come to a halt. However,
the service will continue to serve API requests/queries with the existing data.
Data egress
It is highly recommended that data egress is enabled and that an egress window value is set to prevent exponential DB growth. Removing old data from the system helps reduce DB disk size.
Provides the ability to remove data which is no longer active in Anchore Enterprise from the stored report data.
This process is disabled by default and controlled by the value enable_data_egress. A configuration setting to determine how old this data is prior to its removal data_egress_window is also available.
Metrics
Reports service comes loaded with a few pre-defined/canned metric definitions. A metric definition consists of an
identifier, readable name, description and the type of the metric. The type is loosely based on statsd metric types.
Currently, all the pre-defined metrics are of type ‘counter’ - a measure of the number of items that match certain
criteria. A value for each of these metric definitions is computed using the data aggregated by the service.
All metric values are computed periodically every hour (3600 seconds). To modify the interval, update
cycle_timers -> reports_metrics in the config.yaml snippet above. In a quickstart deployment, add
ANCHORE_ENTERPRISE_REPORTS_METRICS_INTERVAL_SEC=<interval-in-seconds> to the environment variables section of the
reports service in docker-compose.yaml.
See it in action
To see Reports service in the Enterprise UI, see Dashboard or
Reporting & Remediation view. The dashboard view utilizes metrics generated by the
service and renders customizable widgets. The reports view employs graphQL queries and aggregates the results into
multiple formats (CSV, JSON, and so on).
For using the API directly, see API Access.
14 - Runtime Inventory
Overview
Using Anchore’s runtime inventory agents provides Anchore Enterprise access to what images are being used
in your deployments. This can help give insight into where vulnerabilities or policy violations are in your
production workloads.
Agents
Anchore provides agents for collecting the inventory of different container runtime environments:
General Runtime Configuration
Inventory Time-To-Live
As part of reporting on your runtime environment, Anchore maintains an active record of the containers, the images they run,
and other related metadata based on time they were last reported by an inventory agent.
The configuration setting below allow you to specify how long inventory should remain part of the Catalog Service’s working set.
These are the default settings found in the values file.
services:
catalog:
runtime_inventory:
inventory_ingest_overwrite: false
inventory_ttl_days: 120
Below are a few examples on how you may want to use this feature.
Keep most recently reported inventory
inventory_ingest_overwrite: true
inventory_ttl_days: 7
For each cluster/namespace reported from the inventory agent, the system will delete any previously reported
containers and images and replace it with the new inventory.
Note: The inventory_ttl_days is still needed to remove any cluster/namespaces that are no longer reported as well as
some of the supporting metadata (ie. pods, nodes). This value should be configured to be long enough that inventory isn’t incorrectly removed in case of an outage from the reporting agent.
The exact value depends on each deployment, but 7 days is a reasonable value here.
Keep inventory reported over a time period
inventory_ingest_overwrite: false
inventory_ttl_days: 14
This will delete any container and image that has not been reported by an agent in the last 14 days. This includes its supporting metadata (ie. pods, nodes).
Keep inventory indefinitely
inventory_ingest_overwrite: false
inventory_ttl_days: 0
This will keep any containers, images, and supporting metadata reported by an inventory agent indefinitely.
Deleting Inventory via API
Where it is not desirable to wait for the Image TTL to remove runtime inventory images it is possible to manually delete inventory items via the API by issuing a DELETE to /v2/inventories with the following query parameters.
inventory_type (required) - either ecs or kubernetescontext (required) - it must match a context as seen by the output of anchorectl inventory list- Kubernetes - this is a combination of cluster name (as defined by the anchore-k8s-inventory config) and a namespace containing running containers e.g.
cluster1/default. - ECS - this is the cluster ARN e.g.
arn:aws:ecs:eu-west-2:123456789012:cluster/myclustername
image_digest (optional) - set if you only want to remove a specific image
e.g. DELETE /v2/inventories?inventory_type=<string>&context=<string>&image_digest=<string>
Using curl: curl -X DELETE -u username:password "http://{servername:port}/v2/inventories?inventory_type=&context=&image_digest=
15 - Scanning
Introduction
This section describes common configuration options for image and SBOM scanning.
Limiting Image Size
Anchore Enterprise can be configured to have a size limit for images being added for analysis. Images that exceed the configured maximum size will not be added to Anchore and the catalog service will log an error message providing details of the failure. This size limit is applied when adding images to Anchore Enterprise via AnchoreCTL, tag subscriptions, and repository watchers.
Note
By default the max_compressed_image_size_mb feature is disabled.This limit can be enabled via the max_compressed_image_size_mb property in the Anchore Enterprise configuration file or by using the ANCHORE_MAX_COMPRESSED_IMAGE_SIZE_MB env variable.
- When a value greater than zero is supplied, the value represents the size limit in MB of the compressed image.
- When a value less than zero is supplied, it will disable the feature and allow images of any size to be added to Anchore.
- A value of 0 will prevent any images from being added.
- Finally, non-integer values will cause bootstrap of the service to fail.
If using Docker Compose with the default config, this can be set through the ANCHORE_MAX_COMPRESSED_IMAGE_SIZE_MB env variable on the catalog service.
If using Helm, it can be configurated by using the values file and adding the ANCHORE_MAX_COMPRESSED_IMAGE_SIZE_MB env variable to the catalog.extraEnv property.
Malware Scanning
When an Image is Analyzed/Scanned you have the ability to configure the process to best suit your particular use case and/or desired security control. After discovery these data can later be used within Anchore’s policy engine rules and gates.
For an overview of the feature and how it works. See Malware Scanning
Note
Malware scanning can be configured via the UI as well as the methods documented below. To enable it in the UI, go to System -> Configuration, search for Malware, and click the check button to enable the feature.Limitations and Resource Usage
Malware scanning will impact analysis/scanning time, and this time will depend on the size and number of files the image contains. Anchore supports sources, however, sources currently need to be analyzed with Syft and not AnchoreCTL. Syft does not currently support malware checks. Where possible, and use case depending, you should offload to Distributed Scanning/Analysis to reduce analyzer compute load on your central Anchore Deployment.
Anchore Enterprise 5.13 and above supports scanning of images greater than 2GB in size through splitting images for analysis.
- Malware scanning can ONLY operate when using Centralized Analysis and NOT Distributed Analysis.
- ClamAV scan timeout has been increased from 2 minutes to 30 minutes in order to accomodate malware scanning for larger images. This can be changed through the
max_scan_time parameter in the Helm chart.
Enabling & Disabling
The process for enabling and configuring the Malware scan differs between Helm and Compose deployments. Additionally, there are two modes in which you can scan and analyze images, and therefore two places to configure this capability: 1. Distributed Mode 2. Centralized Mode.
For Centralized Analysis, Malware scans are configured in the centralized Anchore Deployment via the Analyzer config documented on this page.
Helm
Update the Helm values.yaml file. Below is an example configuration for enabling Malware scanning. Helm will take these values and define a ConfigMap in your Anchore Kubernetes deployment.
Malforming this file can cause the Anchore Analyzer to fail on all image analysis!
anchoreConfig:
analyzer:
configFile:
## Malware scanning occurs only at analysis time when the image content itself is available
malware:
clamav:
# Set to true to enable the malware scan
enabled: true
# Set to true to enable the db refresh on each scan
db_update_enabled: true
# Maximum time in milliseconds that ClamAV scan is allowed to run (default is 30 minutes)
max_scan_time: 1800000
Please review the helm chart example values.yaml file for further detail.
Docker Compose
The Malware scan can be configured and enabled in the ‘analyzer_config.yaml’ file. This file needs to then be mounted as a file volume in your Anchore Docker Compose file under the analyzer: service as shown below:
analyzer:
volumes:
- ./analyzer_config.yaml:/anchore_service/analyzer_config.yaml:ro #mounted analyzer_config
This file should contain the required configuration parameters. Please see the following example and adjust as required.
malware:
clamav:
# Set this to true to enable the malware scan
enabled: true
# Set this to false to turn off the db refresh on each scan
db_update_enabled: true
Cataloger Scanning
During Analysis/Scans of your images, Anchore has the ability to run extra catalogers or searches. These are as follows:
retrieve_files - retrieve and index files matching a configured file list
secret_search and content_search - perform a search across file contents for a configured regexp match. Findings are then cataloged accordingly.
Limitations and Resource Usage
Running extra catalogers will require more resources and time to perform analysis of images. Please take this into consideration when enabling and defining your regexp values.
This can be controlled by limiting the search with MAXFILESIZE to limit the search to large and/or very small files.
Catalogers will impact analysis/scanning time, and this time will depend on the size and number of files the image contains. Anchore supports sources, however, sources currently need to be analyzed with Syft and not AnchoreCTL. Syft does not currently support catalogers. Where possible, and use case depending, you should offload to Distributed Scanning/Analysis to reduce analyzer compute load on your central Anchore Deployment.
Enabling & Disabling
The process for enabling and configuring the catalogers differs between Helm and Compose deployments. Additionally, there are two modes in which you can scan and analyze images: 1. Distributed Mode 2. Centralized Mode.
For Distributed Analysis, the catalogers are configured in the AnchoreCTL Configuration.
For Centralized Analysis, the catalogers are configured in the centralized Anchore Deployment via the Analyzer config documented below.
Helm
Update the Helm values.yaml file. Below is an example configuration for enabling retrieve_files and secret_search catalogers. Helm will take these values and define a ConfigMap in your Anchore Kubernetes deployment.
Malforming this file can cause the Anchore Analyzer to fail on all image analysis!
anchoreConfig:
analyzer:
malware:
configFile:
retrieve_files:
file_list:
- '/etc/passwd'
secret_search:
match_params:
- MAXFILESIZE=10000
regexp_match:
- "AWS_ACCESS_KEY=(?i).*aws_access_key_id( *=+ *).*(?<![A-Z0-9])[A-Z0-9]{20}(?![A-Z0-9]).*"
- "AWS_SECRET_KEY=(?i).*aws_secret_access_key( *=+ *).*(?<![A-Za-z0-9/+=])[A-Za-z0-9/+=]{40}(?![A-Za-z0-9/+=]).*"
- "PRIV_KEY=(?i)-+BEGIN(.*)PRIVATE KEY-+"
- "DOCKER_AUTH=(?i).*\"auth\": *\".+\""
- "API_KEY=(?i).*api(-|_)key( *=+ *).*(?<![A-Z0-9])[A-Z0-9]{20,60}(?![A-Z0-9]).*"
# - "ALPINE_NULL_ROOT=^root:::0:::::$"
#
## Uncomment content_search: {} to configure file content searching
# Very expensive operation - recommend you carefully test and review
# content_search:
# match_params:
# - MAXFILESIZE=10000
# regexp_match:
# - "EXAMPLE_MATCH="
Please review the helm chart example values.yaml file for further detail.
Docker Compose
The Catalogers can be configured and enabled in the ‘analyzer_config.yaml’ file. This file needs to then be mounted as a file volume in your Anchore Docker Compose file under the analyzer: service as shown below:
services:
analyzer:
volumes:
- ./analyzer_config.yaml:/anchore_service/analyzer_config.yaml:ro #mounted analyzer_config
This file should contain the required configuration parameters. Please see the following example and adjust as required.
retrieve_files:
max_file_size_kb: 1000
file_list:
- '/etc/passwd'
- '/etc/services'
- '/etc/sudoers'
secret_search:
match_params:
- MAXFILESIZE=10000
regexp_match:
- "AWS_ACCESS_KEY=(?i).*aws_access_key_id( *=+ *).*(?<![A-Z0-9])[A-Z0-9]{20}(?![A-Z0-9]).*"
- "AWS_SECRET_KEY=(?i).*aws_secret_access_key( *=+ *).*(?<![A-Za-z0-9/+=])[A-Za-z0-9/+=]{40}(?![A-Za-z0-9/+=]).*"
- "PRIV_KEY=(?i)-+BEGIN(.*)PRIVATE KEY-+"
- "DOCKER_AUTH=(?i).*\"auth\": *\".+\""
- "API_KEY=(?i).*api(-|_)key( *=+ *).*(?<![A-Z0-9])[A-Z0-9]{20,60}(?![A-Z0-9]).*"
## Uncomment content_search: {} to configure file content searching
# Very expensive operation - recommend you carefully test and review
# content_search:
# match_params:
# - MAXFILESIZE=10000
# regexp_match:
# - "EXAMPLE_MATCH="
Imported SBOM Scanning
SBOMs imported via Anchore SBOM are automatically scanned for vulnerabilities after upload and at regular intervals following each feed update.
By default, the system runs in auto_scale mode. This automatically calculates the number of concurrent background tasks required to completely rescan your imported SBOM inventory within a six-hour window.
It does so by adjusting the following settings based on a function of the number of imported SBOMs in the system and the number of Policy Engine and Catalog instances configured in your deployment:
batch_size: The number of imported SBOMs to scan in a single batch. Maximum of 8.
pool_size: The number of concurrent scan threads to run on each Policy Engine. Maximum of 4.
If you wish to override the auto_scale behaviour and manually configure these settings, first set catalog.sbom_vuln_scan.auto_scale to false. You may then set catalog.sbom_vuln_scan.batch_size and catalog.sbom_vuln_scan.pool_size to your desired values.
Helm
In your values.yaml file set the following:
anchoreConfig:
catalog:
sbom_vuln_scan:
auto_scale: false
batch_size: 4
pool_size: 2
Docker Compose
In your config.yaml file set the following:
services:
catalog:
sbom_vuln_scan:
auto_scale: false
batch_size: 4
pool_size: 2
Redhat Enterprise Linux (RHEL) Extended Update Support (EUS)
Anchore Enterprise supports the detection of Red Hat Enterprise Linux (RHEL) Extended Update Support (EUS) in images analysed by Anchore Secure.
You can decide how Anchore Secure should act when scanning RHEL EUS images for vulnerabilities by setting the following configuration options:
These settings can be changed via the configuration API or by modifying your configuration file as follows.
Helm
To override the default values, alter the following fields in your values.yaml file:
anchoreConfig:
policy_engine:
vulnerabilities:
extended_support:
rhel:
enabled: "auto"
versions: ">=8.0"
Docker Compose
To override the default values, alter the following fields in your config.yaml file:
services:
policy_engine:
vulnerabilities:
extended_support:
rhel:
enabled: "auto"
versions: ">=8.0"
16 - Storage Configuration
Anchore Enterprise uses configurable storage mechanisms in accordance with a number of operations:
Note
Anchore recommends configuring scratch and layer caching according to your use-case, then using the DB storage driver for Active Data Set and object storage (e.g. S3/S3-compatible) for Archive Data Set. You should configure Archive Rules and Artifact Lifecycle Policies to keep your Active Data Set small.Storage During Analysis
Scratch Space
Anchore uses a local directory for image analysis operations including downloading layers and unpacking the image content
for the analysis process. This space is necessary on each analyzer worker service and should not be shared. The scratch
space is ephemeral and can have its lifecycle bound to that of the service container. For more information, see Scratch.
Layer Cache
The layer cache is an extension of the analyzer’s scratch space that is used to cache layer downloads to reduce analysis
time and network usage during the analysis process itself. For more information, see, Layer Caching.
Storing Analysis Results (Active Data Set)
Note
The Anchore Enterprise Database Driver is the default object storage driver for the Active Data Set.For structured data that must be quickly queried and indexed, Anchore relies on PostgreSQL as its primary data store. See here for deployment requirements.
Anchore Enterprise is a data intensive system and uses external storage systems for all data persistence. None of the services
are stateful in themselves. For less structured data, Anchore implements an internal object store that can be overlayed on different backend providers,
but defaults to also using the main postgres db to reduce the out-of-the-box dependencies. However, S3/S3-compatible is supported for leveraging external systems, for more information on the configuration of the DB driver see Database.
Archiving Analysis Results (Archive Data Set)
To aid in capacity management, Anchore provides a separate storage location where completed image analysis can be moved to. This reduces consumption of database capacity and primary object storage. It also removes the analysis from most API actions but makes it available to restore into the primary storage systems as needed. The analysis archive is
configured as an alternate object store to the Active Data Set object store. For more information, see: Configuring Analysis Archive.
16.1 - Database Storage
Anchore stores all metadata in a structured format in a PostgreSQL database to support API operations and searches.
Examples of data persisted in the database:
- Image metadata (distro, version, layer counts, …)
- Image digests to tag mapping (docker.io/nginx:latest is hash sha256:abcd at time t)
- Image analysis content indexed for policy evaluation (files, packages, ..)
- Feed data
- vulnerability info
- package info from upstream (gem/npm)
- Accounts, users…
- …
If the object store is not explicitly set to an external provider, then that data is also persisted in
the database but can be migrated
Reducing Database Storage Usage
Beyond enabling a non-DB object store there are some configuration
options to reduce database storage and IO used by Anchore.
Configuration of Indexed DB Storage for Package DB File Entries
There is a configuration option for the policy engine service to disable the usage of
the database for storing indexed package database entries from each analyzed image. This data represents the files in
each distro package and their metadata (digests and permissions) from each scanned image in the image_package_db_entries table.
That table is only used by the policy engine to deliver the policy trigger [‘packages.verify’],
but if you do not use that trigger then the use of the storage can be disabled thereby reducing database load and resource usage.
The data can be quite large, often in the thousands of rows per analyzed image, so for some customers that do not use this
data for policy, disabling the loading of this data can reduce database consumption significantly.
Disabling Indexed DB Storage for Package DB File Entries
In each policy engine’s config.yaml file, change:
enable_package_db_load: true
to
enable_package_db_load: false
You can configure this by adding an environment variable ANCHORE_POLICY_ENGINE_ENABLE_PACKAGE_DB_LOAD with your chosen value on the policy engine service for both Compose and Helm deployments. This is enabled or set to ’true’ by default.
Note that disabling the table usage will also disable support for the packages.verify trigger and any policies that have the
trigger in a rule will be considered invalid and return errors on evaluation. Any new policies that attempt to use the trigger
will be rejected on upload as invalid if the trigger is included.
Once this configuration is set, you may delete data in that db table to reclaim some database storage capacity. If
you’re interested in this option please contact support for guidance on this process.
Enabling Indexed DB Storage for Package DB File Entries
If you find that you do need the trigger, you can change the configuration to use the table then support will be
restored. However, any images analyzed while the setting was ‘false’ will need to be re-analyzed in order to
populate their data in that table correctly.
16.2 - File Storage Configuration
Anchore uses a local directory for image analysis operations including downloading layers and unpacking the image content for the analysis process.
For configuration of local storage for scratch space, see Scratch.
In many cases the images will share a number of common layers, especially if images are built form a consistent set of base images. Anchore Enterprise can cache image layers to improve analysis time, see Layer Caching.
16.2.1 - Scratch Configuration
Anchore uses a local directory for image analysis operations including downloading layers and unpacking the image content for the analysis process.
Analysis Process
Once an image is submitted to Anchore Enterprise for centralized analysis the system will attempt to retrieve metadata about the image from the Docker registry and if successful will download the image and queue the image for analysis. Anchore Enterprise can run one or more analyzer services to scale out processing of images. The next available analyzer worker will process the image.
Docker Images are made up of one or more layers, which are described in the manifest. The manifest lists the layers which are typically stored as gzipped compressed TAR files.
As part of image analysis Anchore Enterprise will:
- Download all layers that comprise an image
- Extract the layers to a temporary file system location
- Perform analysis on the contents of the image including:
- Digest of every file (SHA1, SHA256 and MD5)
- File attributes (size, owner, permissions, etc.)
- Operating System package manifest
- Software library package manifest (NPM, GEM, Java, Python, NuGet)
- Scan for secret materials (api keys, private keys, etc.)
Following the analysis the extracted layers and downloaded layer tar files are deleted.
Configuration of Scratch Space
Note
It is typically recommended that the cache data is stored in an external volume to ensure that the cache does not use up the ephemeral storage space allocated to the container host.By default Anchore Enterprise uses the /tmp directory within the container to download and extract images. You may wish to define a temporary directory or a volume mounted specifically for scratch image data. This can be configured in the config.yaml:
tmp_dir: '/scratch'
In this example a volume has been mounted as /scratch within the container and config.yaml updated to use /scratch as the temporary directory for image analysis.
With the layer cache disabled the temporary directory should be sized to at least 3 times the uncompressed image size to be analyzed. To understand layer caching, see Layer Caching
16.2.2 - Layer Caching Configuration
To speed up Anchore Enterprise can be configure to cache image layers to eliminate the need to download the same layer for many different images.
Configuring Layer Caching
Layer cache should be enabled in order to tell the analyzer service to cache image layers.
Note
Layer cache should be sized to at least 3 times the uncompressed image size + 4 gigabytes.To enable layer caching, adjust the layer_cache_max_gigabytes parameter in the analyzer section of the Anchore Enterprise Helm values file, for example:
analyzer:
enabled: True
require_auth: True
cycle_timer_seconds: 1
analyzer_driver: 'nodocker'
endpoint_hostname: '${ANCHORE_HOST_ID}'
listen: '0.0.0.0'
port: 8084
layer_cache_max_gigabytes: 4
In the above, the layer cache is set to 4 gigabytes.
- The minimum size for the cache is 1 gigabyte.
- The cache users a least recently used (LRU) policy.
- The cache files will be stored in the anchore_layercache directory of the /tmp_dir volume, as noted above.
Note For further specifics, consult the Anchore Enterprise Helm chart here.
16.3 - Object Storage
Note
Anchore Enterprise allows independent configuration of object storage drivers for both the Active Data Set and the Archive Data Set.Anchore Enterprise uses a PostgreSQL database by default to store structured data for images, tags, policies, subscriptions and metadata
about images, but other types of data in the system are less structured and tend to be larger pieces of data. Because of
that, there are benefits to supporting key-value access patterns for things like image manifests, analysis reports, and
policy evaluations. For such data, Anchore has an internal object storage interface that, while defaulted to use the
same Postgres database for storage, can be configured to use external object storage providers to support simpler capacity
management and lower costs. The options are:
If you’re using an S3-compatible storage provider (not AWS), you may encounter issues with request or response checksum validation. To avoid these, set the following as extra Environment variables in catalog: AWS_REQUEST_CHECKSUM_CALCULATION & AWS_RESPONSE_CHECKSUM_CALCULATION with their value set to when_required.
For the Active Data Set, configuration for the object store is set in the catalog’s object_store service configuration in the config.yaml.
For the Archive Data Set, configuration for the object store is set in the catalog’s analysis_archive configuration in the config.yaml. See Analysis Archive).
Migration instructions to move from the default provider to external object store can be found here.
Common Configurations
Single shared object store backend: set object_store details in config.yaml and omit the analysis_archive config from config.yaml, or set it to null or {}
Different bucket/container: the object_store and analysis_archive configurations are both specified and identical
with the exception of the bucket or container values for the analysis_archive so that its data is split into a
different backend bucket to allow for lifecycle controls or cost optimization since its access is much less frequent (if ever).
Primary object store in DB, analysis_archive in external S3: this keeps latency low as no external service is
needed for the object store and active data but lets you use more scalable external object storage for archive data. This
approach is most beneficial if you can keep the working set of images small and quickly transition old analysis to the
archive to ensure the db is kept small and the analysis archive handles the data scaling over time.
16.3.1 - Database Driver
The default object store driver is the PostgreSQL database driver which stores all object store documents within the PostgreSQL database.
A component of the object store driver is the archive_document. When the default object store driver is used, as opposed to a user configuring a S3 bucket, this is the location where image SBOMs, vulnerability scans, policy evaluations, and reports are stored.
Compression is not supported for this driver since the underlying database will handle compression.
There are no configuration options required for the Database driver.
The embedded configuration for anchore enterprise includes the default configuration for the db driver.
object_store:
compression:
enabled: False
min_size_kbytes: 100
storage_driver:
name: db
config: {}
16.3.2 - Analysis Archive Storage Configuration
For information on what the analysis archive is and how it works, see Concepts: Analysis Archive
The Analysis Archive is an object store with specific semantics and thus is configured as an object store using the same configuration options as object_store which is used for the active working set of images, just with a different config key: analysis_archive
Amazon S3 Example
Anchore strongly recommends using IAM roles for secure access to Amazon S3.
Example configuration snippet for using the DB for working set object store and Amazon S3 for the analysis archive:
...
services:
...
catalog:
...
object_store:
compression:
enabled: false
min_size_kbytes: 100
storage_driver:
name: db
config: {}
analysis_archive:
compression:
enabled: False
min_size_kbytes: 100
storage_driver:
name: 's3'
config:
iamauto: True
region: <AWS_REGION_HERE>
bucket: 'anchorearchive'
create_bucket: True
S3-Compatible Example
Example configuration snippet for using the DB for working set object store and S3-API compatible object storage for the analysis archive:
...
services:
...
catalog:
...
object_store:
compression:
enabled: false
min_size_kbytes: 100
storage_driver:
name: db
config: {}
analysis_archive:
compression:
enabled: False
min_size_kbytes: 100
storage_driver:
name: 's3'
config:
access_key: 'MY_ACCESS_KEY'
secret_key: 'MY_SECRET_KEY'
url: 'https://my-s3-compatible-endpoint.example.com:optional_port'
region: False
bucket: 'anchorearchive'
create_bucket: True
Default Configuration
By default, if no analysis_archive config is found or the property is not present in the config.yaml, the analysis archive
will use the object_store or archive (for backwards compatibility) config sections and those defaults (e.g. db if found).
Anchore stores all of the analysis archive objects in an internal logical bucket: analysis_archive that is distinct in
the configured backends (e.g a key prefix in the s3 bucket)
Changing Configuration
Unless there are image analyses actually in the archive, there is no data to move if you need to update the configuration
to use a different backend, but once an image analysis has been archived to update the configuration you must follow
the object storage data migration process found here. As noted in that guide, if you need
to migrate to/from an analysis_archive config you’ll need to use the –from-analysis-archive/–to-analysis-archive
options as needed to tell the migration process which configuration to use in the source and destination config files
used for the migration.
16.3.3 - Amazon S3
This page describes configuration when using Amazon S3 for object storage with IAM role authentication.
Anchore strongly recommends using IAM roles for secure access to Amazon S3.
IAM Role Authentication
For Anchore to use an AWS IAM role, the environment it runs in (such as an EC2 instance, ECS task, or Kubernetes pod) must have an AWS IAM role with the necessary S3 bucket permissions:
"Action": [
"s3:PutObject*",
"s3:GetObject*",
"s3:DeleteObject*",
],
In your values.yaml file storage_driver section, set the iamauto parameter to true:
services:
catalog:
archive:
storage_driver:
name: 's3'
config:
iamauto: true
With iamauto: true, Anchore automatically adopts the IAM role of its host environment. This is the most secure method for granting Amazon S3 access as it removes the need to store credentials such as ACCESS_KEY and SECRET_KEY in configuration files.
Other S3 Configuration Options
Below are other configurable parameters for the Anchore S3 driver:
The Anchore S3 driver supports document compression to reduce storage space. Set to true to enable or false to disable and
min_size_kbytes sets the minimum document size in kilobytes to be compressed.
config:
...
compression:
enabled: true
min_size_kbytes: 1
region - the AWS region of your Amazon S3 bucket. It is required if url is not specified.
bucket - the name of the Aamzon S3 bucket for Anchore’s data storage.
create_bucket - if set to true, Anchore will attempt to create the bucket if it doesn’t exist. It is, however, recommended to pre-create the bucket.
Example
Here is a full configuration example for the S3 driver using IAM role authentication:
services:
catalog:
archive:
storage_driver:
name: 's3'
config:
# AWS IAM role authentication
iamauto: true
# Amazon S3 bucket configuration
region: 'us-east-1'
bucket: 'my-anchore-data'
create_bucket: false
# Optional compression
compression:
enabled: true
min_size_kbytes: 1
16.3.4 - S3-Compatible
Anchore Enterprise can be configured to use third-party S3 API-compatible object storage systems.
Anchore strongly recommends using Kubernetes secrets rather than plaintext entries in your values.yaml to store your S3-compatible access keys.
Example Configuration
object_store:
compression:
enabled: False
min_size_kbytes: 100
storage_driver:
name: 's3'
config:
access_key: 'MY_ACCESS_KEY'
secret_key: 'MY_SECRET_KEY'
#iamauto: True
url: 'https://my-s3-compatible-endpoint.example.com:optional_port'
region: False
bucket: "anchorearchive"
create_bucket: True
Configuration Options
The following additional configuration parameters can be used.
Compression
The S3 driver supports compression of documents. The documents are JSON formatted and will see significant reduction in
size through compression there is an overhead incurred by running compression and decompression on every access of these
documents. Anchore Enterprise can be configured to only compress documents above a certain size to reduce unnecessary
overhead. In the example below any document over 100kb in size will be compressed.
Authentication
Anchore Enterprise can authenticate against the S3-compatible service using access keys.
Endpoints
url - (required) A URL to set to reach an S3-API compatible service. Note that if the URL is configured, the region config value is ignored, as this is only used for Amazon S3.
Buckets
bucket - (required) The name of the S3 bucket that Anchore will use for storing data.
create_bucket- (default: false) Try to create the bucket if it doesn’t already exist. This should be used very sparingly. For most cases, you should pre-create the bucket so that it has the permissions you desire, then set this to false.
Storing Object Store API keys in a Kubernetes Secret
You can configure your object store API keys to be pulled from a Kubernetes Secret as follows:
extraEnv:
- name: ANCHORE_OBJ_STORAGE_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: accessKey
- name: ANCHORE_OBJ_STORAGE_SECRET_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: secretKey
anchoreConfig:
catalog:
object_store:
storage_driver:
name: s3
config:
access_key: ${ANCHORE_OBJ_STORAGE_ACCESS_KEY}
secret_key: ${ANCHORE_OBJ_STORAGE_SECRET_KEY}
In this example the secret was called minio-secret but you can use whatever name you would like. The secret looks as follows:
apiVersion: v1
data:
accessKey: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
secretKey: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
kind: Secret
16.3.5 - Migrating Data to New Drivers
To migrate data from one driver to another (e.g. DB to S3), Anchore Enterprise includes capabilities that automate the process in the anchore-manager tool packaged with the system. For Helm-based deployments, this is further automated via Helm upgrade helpers, whereas for Docker Compose deployments the tool must be run manually.
Caution
The migration process is an offline process; Anchore Enterprise is not designed to handle an online migration.The object storage migration process migrates any data stored in the source config to the destination configuration, if the analysis archive is configured to use the same storage backend as the primary object store then that data is migrated along with all other data, but if the source or destination configurations define different storage backends for the analysis archive than that which is used by the primary object store, then additional paramters are necesary to indicate which configurations to migrate to/from.
The most common migration patterns are:
- Migrate from a single backend configuration to a split configuration to keep the Active Data Set in the DB and then move the Archive Data Set (analysis archive data) to an external system (db -> db + s3)
- Migrate from a dual-backend configuration to a single-backend configuration with a different config (e.g. db + s3-compatible -> s3-compatible)
At a high-level the process is:
- Shutdown all Anchore Enterprise services and components. The system should be fully offline, but the database must be online and available. For a docker compose install, this is achieved by simply stopping the engine container, but not deleting it.
- Prepare a new
config.yaml that includes the new driver configuration for the destination of the migration (dest-config.yaml) in the same location as the existing config.yaml - Test a new
dest-config.yaml to ensure correct configuration - Run the migration
- Get coffee… this could take a while if you have a lot of analysis data
- When complete, view the results
- Ensure the
dest-config.yaml is in place for all the components as config.yaml - Start Anchore Enterprise services and components.
EXAMPLE: Migration of Object Store in Helm-based Deployment from DB to Amazon S3
The Anchore Enterprise Helm Chart provides a way to run the migration steps listed in this page automatically by spinning up a job and crafting the configs required and running the necessary migration commands. Further information is available via instructions found in our Helm Chart here. Below are example configurations:
Note
Anchore recommends using IAM roles for access to Amazon S3, as in the example below, you can find role configuration details here.Example config
osaaMigrationJob:
enabled: true # note that we are enabling the migration job
analysisArchiveMigration:
run: true # we are specifying to run the analysis_archive migration
bucket: "analysis_archive"
mode: to_analysis_archive
# the deployment will be migrated to use the following configs for catalog.analysis_archive
analysis_archive:
enabled: true
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: s3
config:
iamauto: true
region: <MY_AWS_REGION>
bucket: analysisarchive
objectStoreMigration:
run: true
# note that since this is the same as anchoreConfig.catalog.object_store, the migration
# command for migrating the object store will still run, but it will not do anything as there
# is nothing to be done
object_store:
verify_content_digests: true
compression:
enabled: false
min_size_kbytes: 100
storage_driver:
name: db
config: {}
# the deployment was previously deployed using the following configs
anchoreConfig:
default_admin_password: foobar
catalog:
analysis_archive:
enabled: true
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: db
config: {}
object_store:
verify_content_digests: true
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: db
config: {}
EXAMPLE: Migration of Object Store in Helm-based Deployment from DB to S3-compatible
Example config
osaaMigrationJob:
enabled: true # note that we are enabling the migration job
analysisArchiveMigration:
run: true # we are specifying to run the analysis_archive migration
bucket: "analysis_archive"
mode: to_analysis_archive
# the deployment will be migrated to use the following configs for catalog.analysis_archive
analysis_archive:
enabled: true
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: s3
config:
access_key: MY_ACCESS_KEY
secret_key: MY_SECRET_KEY
url: 'https://my-s3-compatible-endpoint.example.com:optional_port'
region: null
bucket: analysisarchive
objectStoreMigration:
run: true
# note that since this is the same as anchoreConfig.catalog.object_store, the migration
# command for migrating the object store will still run, but it will not do anything as there
# is nothing to be done
object_store:
verify_content_digests: true
compression:
enabled: false
min_size_kbytes: 100
storage_driver:
name: db
config: {}
# the deployment was previously deployed using the following configs
anchoreConfig:
default_admin_password: foobar
catalog:
analysis_archive:
enabled: true
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: db
config: {}
object_store:
verify_content_digests: true
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: db
config: {}
EXAMPLE: Migration of Object Store in Docker Compose from DB to S3-compatible
The following example demonstrates migration for a Docker Compose deployment.
Preparing for Migration
For the migration process you will need:
- The original
config.yaml used by the services already, if services are split out or using different config.yaml for different services, you need the config.yaml used by the catalog services - An updated
config.yaml (named dest-config.yaml in this example), with the archive driver section of the catalog service config set to the config you want to migrate to - The db connection string from
config.yaml, this is needed by the anchore-manager script directly - Credentials and resources (bucket etc) for the destination of the migration
If Anchore Enterprise is deployed using Docker Compose, the migration must be manually initiated using the anchore-manager script. The following is an example migration for Anchore Enterprise deployed via Docker Compose on a single host with a local postgresql container. This process requires that you run the command in a location that has access to both the source archive driver configuration and the new archive driver configuration.
Step 1: Shutdown all services
All services should be stopped, but the postgresql db must still be available and running. You can use the docker compose stop command and supply all services names except the DB:
docker compose stop anchore-analyzer anchore-api anchore-catalog anchore-policy-engine anchore-queue anchore-enterprise-api-gateway anchore-enterprise-rbac-service redis
Step 2: Prepare a new config.yaml
Both the original and new configurations are needed, so create a copy and update the archive driver section to the configuration you want to migrate to
cd config
cp config.yaml dest-config.yaml
<edit dest-config.yaml>
Step 3: Test the destination config
Assuming that config is dest-config.yaml:
$ docker compose run anchore-catalog /bin/bash
[root@3209ad44d7bb ~]# anchore-manager objectstorage --db-connect ${db} check /config/dest-config.yaml
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB params: {"db_pool_size": 30, "db_connect": "postgresql+pg8000://postgres:postgres.dev@postgres-dev:5432/postgres", "db_connect_args": {"ssl": false, "connect_timeout": 120, "timeout": 30}, "db_pool_max_overflow": 100}
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB connection configured: True
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB attempting to connect...
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB connected: True
[MainThread] [anchore_manager.cli.objectstorage/check()] [INFO] Using config file /config/dest-config.yaml
[MainThread] [anchore_engine.subsys.object_store.operations/initialize()] [INFO] Archive initialization complete
[MainThread] [anchore_manager.cli.objectstorage/check()] [INFO] Checking existence of test document with user_id = test, bucket = anchorecliconfigtest and archive_id = cliconfigtest
[MainThread] [anchore_manager.cli.objectstorage/check()] [INFO] Creating test document with user_id = test, bucket = anchorecliconfigtest and archive_id = cliconfigtest
[MainThread] [anchore_manager.cli.objectstorage/check()] [INFO] Checking document fetch
[MainThread] [anchore_manager.cli.objectstorage/check()] [INFO] Removing test object
[MainThread] [anchore_manager.cli.objectstorage/check()] [INFO] Archive config check completed successfully
Step 3a: Test the current config.yaml
If you are running the migration for a different location than one of the Anchore Enterprise containers, same as above but using /config/config.yaml as the input to check (skipped in this instance since we’re running the migration from the same container)
Step 4: Run the migration
By default, the migration process will remove data from the source once it has confirmed it has been copied to the destination and the metadata has been updated in the anchore db. To skip the deletion on the source, use the --nodelete option. It is the safest option, but if you use it, you are responsible for removing the data later.
[root@3209ad44d7bb ~]# anchore-manager objectstorage --db-connect ${db} migrate /config/config.yaml /config/dest-config.yaml
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB params: {"db_pool_size": 30, "db_connect": "postgresql+pg8000://postgres:postgres.dev@postgres-dev:5432/postgres", "db_connect_args": {"ssl": false, "connect_timeout": 120, "timeout": 30}, "db_pool_max_overflow": 100}
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB connection configured: True
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB attempting to connect...
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB connected: True
[MainThread] [anchore_manager.cli.objectstorage/migrate()] [INFO] Loading configs
[MainThread] [anchore_manager.cli.objectstorage/migrate()] [INFO] Migration from config: {
"storage_driver": {
"config": {},
"name": "db"
},
"compression": {
"enabled": false,
"min_size_kbytes": 100
}
}
[MainThread] [anchore_manager.cli.objectstorage/migrate()] [INFO] Migration to config: {
"storage_driver": {
"config": {
"access_key": "9EB92C7W61YPFQ6QLDOU",
"create_bucket": true,
"url": "http://minio-ephemeral-test:9000/",
"region": false,
"bucket": "anchore-engine-testing",
"prefix": "internaltest",
"secret_key": "TuHo2UbBx+amD3YiCeidy+R3q82MPTPiyd+dlW+s"
},
"name": "s3"
},
"compression": {
"enabled": true,
"min_size_kbytes": 100
}
}
Performing this operation requires *all* anchore-engine services to be stopped - proceed? (y/N)y
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Initializing migration from {'storage_driver': {'config': {}, 'name': 'db'}, 'compression': {'enabled': False, 'min_size_kbytes': 100}} to {'storage_driver': {'config': {'access_key': '9EB92C7W61YPFQ6QLDOU', 'create_bucket': True, 'url': 'http://minio-ephemeral-test:9000/', 'region': False, 'bucket': 'anchore-engine-testing', 'prefix': 'internaltest', 'secret_key': 'TuHo2UbBx+amD3YiCeidy+R3q82MPTPiyd+dlW+s'}, 'name': 's3'}, 'compression': {'enabled': True, 'min_size_kbytes': 100}}
[MainThread] [anchore_engine.subsys.object_store.migration/migration_context()] [INFO] Initializing source object_store: {'storage_driver': {'config': {}, 'name': 'db'}, 'compression': {'enabled': False, 'min_size_kbytes': 100}}
[MainThread] [anchore_engine.subsys.object_store.migration/migration_context()] [INFO] Initializing dest object_store: {'storage_driver': {'config': {'access_key': '9EB92C7W61YPFQ6QLDOU', 'create_bucket': True, 'url': 'http://minio-ephemeral-test:9000/', 'region': False, 'bucket': 'anchore-engine-testing', 'prefix': 'internaltest', 'secret_key': 'TuHo2UbBx+amD3YiCeidy+R3q82MPTPiyd+dlW+s'}, 'name': 's3'}, 'compression': {'enabled': True, 'min_size_kbytes': 100}}
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Migration Task Id: 1
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Entering main migration loop
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Migrating 7 documents
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/policy_bundles/2c53a13c-1765-11e8-82ef-23527761d060
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/manifest_data/sha256:0873c923e00e0fd2ba78041bfb64a105e1ecb7678916d1f7776311e45bf5634b
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/analysis_data/sha256:0873c923e00e0fd2ba78041bfb64a105e1ecb7678916d1f7776311e45bf5634b
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/image_content_data/sha256:0873c923e00e0fd2ba78041bfb64a105e1ecb7678916d1f7776311e45bf5634b
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/manifest_data/sha256:a0cd2c88c5cc65499e959ac33c8ebab45f24e6348b48d8c34fd2308fcb0cc138
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/analysis_data/sha256:a0cd2c88c5cc65499e959ac33c8ebab45f24e6348b48d8c34fd2308fcb0cc138
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Deleting document on source after successful migration to destination. Src = db://admin/image_content_data/sha256:a0cd2c88c5cc65499e959ac33c8ebab45f24e6348b48d8c34fd2308fcb0cc138
[MainThread] [anchore_engine.subsys.object_store.migration/initiate_migration()] [INFO] Migration result summary: {"last_state": "running", "executor_id": "3209ad44d7bb:37:139731996518208:", "archive_documents_migrated": 7, "last_updated": "2018-08-15T18:03:52.951364", "online_migration": null, "created_at": "2018-08-15T18:03:52.951354", "migrate_from_driver": "db", "archive_documents_to_migrate": 7, "state": "complete", "migrate_to_driver": "s3", "ended_at": "2018-08-15T18:03:53.720554", "started_at": "2018-08-15T18:03:52.949956", "type": "archivemigrationtask", "id": 1}
[MainThread] [anchore_manager.cli.objectstorage/migrate()] [INFO] After this migration, your anchore-engine config.yaml MUST have the following configuration options added before starting up again:
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
config:
access_key: 9EB92C7W61YPFQ6QLDOU
bucket: anchore-engine-testing
create_bucket: true
prefix: internaltest
region: false
secret_key: TuHo2UbBx+amD3YiCeidy+R3q82MPTPiyd+dlW+s
url: http://minio-ephemeral-test:9000/
name: s3
Note
If something goes wrong you can reverse the parameters of the migrate command to migrate back to the original configuration (e.g. migrate /config/dest-config.yaml /config/config.yaml)Step 5: Get coffee!
The migration time will depend on the amount of data and the source and destination systems performance.
Step 6: View migration results summary
[root@3209ad44d7bb ~]# anchore-manager objectstorage --db-connect ${db} list-migrations
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB params: {"db_pool_size": 30, "db_connect": "postgresql+pg8000://postgres:postgres.dev@postgres-dev:5432/postgres", "db_connect_args": {"ssl": false, "connect_timeout": 120, "timeout": 30}, "db_pool_max_overflow": 100}
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB connection configured: True
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB attempting to connect...
[MainThread] [anchore_manager.cli.utils/connect_database()] [INFO] DB connected: True
id state start time end time from to migrated count total to migrate last updated
1 complete 2018-08-15T18:03:52.949956 2018-08-15T18:03:53.720554 db s3 7 7 2018-08-15T18:03:53.724628
This lists all migrations for the service and the number of objects migrated. If you’ve run multiple migrations you’ll see multiple rows in this response.
Step 7: Replace old config.yaml with updated dest-config.yaml
You should now permanently move into place the new configuration, replacing the old.
[root@3209ad44d7bb ~]# cp /config/config.yaml /config/config.old.yaml
[root@3209ad44d7bb ~]# cp /config/dest-config.yaml /config/config.yaml
Step 8: Restart Anchore Enterprise services
Run the following command at the same location as your docker-compose file to bring all services back up:
docker compose start
The system should now be up and running using the new configuration! You can verify with the anchorectl command by fetching a policy, which will have been migrated:
$anchorectl policy list
✔ Fetched policies
┌─────────────────────────┬──────────────────────────────────────┬────────┬──────────────────────┐
│ NAME │ POLICY ID │ ACTIVE │ UPDATED │
├─────────────────────────┼──────────────────────────────────────┼────────┼──────────────────────┤
│ Default bundle │ 2c53a13c-1765-11e8-82ef-23527761d060 │ true │ 2022-07-14T22:52:27Z │
│ anchore_security_only │ anchore_security_only │ false │ 2022-07-14T22:52:27Z │
│ anchore_cis_1.13.0_base │ anchore_cis_1.13.0_base │ false │ 2022-07-14T22:52:27Z │
└─────────────────────────┴──────────────────────────────────────┴────────┴──────────────────────┘
$ anchorectl -o json-raw policy get 2c53a13c-1765-11e8-82ef-23527761d060
[
{
"blacklisted_images": [],
"comment": "Default bundle",
"id": "2c53a13c-1765-11e8-82ef-23527761d060",
... <lots of json>
If that returns the content properly, then you’re all done!
17 - Working with Subscriptions
Introduction
Anchore Enterprise supports 7 types of subscriptions:
- Tag Update
- Policy Update
- Vulnerability Update
- Analysis Update
- Alerts
- Repository Update
- Runtime Inventory
Enabling some of these will generate a notification when the event is triggered while others may have a more significant impact on the system.
Note
Please read carefully what each subscription watches/manages and what effect enabling them may have on the overall deployment.Tag Update
| |
|---|
| Granularity | Per Image Tag |
| Notification Generated | Yes |
| Background Process | Yes |
| Default Timer Frequency | every 60 min |
| Default State | Disabled (Unless the Tag is added by AnchoreCTL) |
| Other Considerations | Adds new tag/digest pairs to the system |
When the tag_update subscription is enabled, a background process, called a “watcher”, will periodically query the repository for any new image digests with the same tag.
For each new image digest found:
- it will be pulled into the catalog and analyzed
- a Tag Update Notification will be triggered.
Policy Updates
| |
|---|
| Granularity | Per Image Tag |
| Notification Generated | Yes |
| Background Process | Yes |
| Default Timer Frequency | every 60 min |
| Default State | Disabled |
| Other Considerations | None |
This class of notification is triggered if a Tag to which a user has subscribed has a change in its policy evaluation status. The policy evaluation status of an image can be one of two states: Pass or Fail. If an image that was previously marked as Pass changes status to Fail or vice-versa then the policy update notification will be triggered.
The policy status of a Tag may be changed by a number of methods.
- Change to policy
- If an policy was changed, for example adding, editing or removing a policy check, then the policy status of an image may be effected. For example adding policy rule that denylists a specific package that is present in a given Tag may cause the Tag’s policy status to move to Fail.
- Changes to Allowlist
- If a allowlist is changed to add or remove a CVE then this may cause a policy status change. For example if an image contains a package that is vulnerable to Crticial Severity CVE-2017-9999 then this image may fail in it’s policy evaluation. If CVE-2017-9999 is added to a CVE Allowlist that is mapped to the subscribed Tag then the policy status may change from Fail to Pass.
- Change in Policy / Allowlist Mapping
- If the policy mapping is changed then a new policy or allowlist may be applied to an image which may change the status of the image. For example changing the mapping to add a more restrictive policy may change an Tag’s status from Pass to Fail.
- Change in Package or Vulnerability Data
- Some policy checks make use of data from external feeds. For example vulnerability checks use CVE data feeds. Changes in data within these feed may change the policy status, such as adding a new CVE vulnerability.
Vulnerability / CVE Update
| |
|---|
| Granularity | Per Image Tag |
| Notification Generated | Yes |
| Background Process | Yes |
| Default Timer Frequency | every 4 hours |
| Default State | Disabled |
| Other Considerations | None |
This class of notification is triggered if the list of CVEs or other security vulnerabilities in the image changes.
For example, a user was subscribed to the library/nginx:latest tag. On the 12th of September 2017 a new vulnerability was added to the Debian 9 vulnerability feed which matched a package in the library/nginx:latest image, triggering a notification.
Based on the changes made by the upstream providers of CVE data (operating system vendors and NIST) CVEs may be added, removed or modified – for example a CVE initially marked as severity level Unknown may be upgraded to a higher severity level.
Note: A change to the CVE list in a Tag may not trigger a policy status change based on the policy rules configured for an image. In the example above the CVE had an unknown severity level which may not be tested by the policy mapped to this image.
Analysis Update
| |
|---|
| Granularity | Per Image Tag |
| Notification Generated | Yes |
| Background Process | No |
| Default Timer Frequency | n/a |
| Default State | Enabled |
| Other Considerations | None |
This class of notification is triggered when an image has been analyzed. Typically, this is triggered when a new Tag has been added to the catalog.
A common use case for this trigger is to alert an external system that a new Tag was added and has been successfully analyzed.
Forcing a re-analysis on an existing image will also cause this notification to be generated.
Alerts
| |
|---|
| Granularity | Per Image Tag |
| Notification Generated | No |
| Background Process | Yes |
| Default Timer Frequency | 10 minutes |
| Default State | Disabled |
| Other Considerations | Enabling this Subscription may be resource intensive as frequent policy evaluations will occur |
The UI and API use stateful alerts that will be raised for policy violations on tags to which you are subscribed for alerts.
This raises a clear notification in the UI to help initiate the remediation workflow and address the violations via the remediation feature.
Once all findings are addressed the alert is closed, allowing an efficient workflow for users to bring their image’s into compliance with their policy.
Repository Update
| |
|---|
| Granularity | Per Repository |
| Notification Generated | No |
| Background Process | Yes |
| Default Timer Frequency | 60 seconds |
| Default State | Disabled |
| Other Considerations | Adds all the tags found in a repository to the system |
This subscription, when enabled, will query the provided repository for any new tags. Any tag not already managed with in Anchore, will be added.
This subscription also provides the ability to determine if the tag_update subscription should be enabled for any new tag added to Anchore.
Please see Repositories for more information.
Please Note: Enabling this subscription may add a large number of tags to the system.
Runtime Inventory
| |
|---|
| Granularity | Per Runtime Inventory Context (Cluster/Namespace) |
| Notification Generated | No |
| Background Process | Yes |
| Default Timer Frequency | 2.5 minutes |
| Default State | Disabled |
| Other Considerations | Adds all the images found in the Context to the system |
This subscription, when enabled, will find any newly reported images from the runtime inventory and add them to Anchore to be analyzed.
Please Note: Enabling this subscription may add a large number of tags to the system.
18 - User Authentication
Overview
Anchore Enterprise offers Authentication via HTTP basic auth, SAML/SSO, LDAP and API Keys.
For more information about specific types of Anchore authentication, see the following topics:
18.1 - API Keys
Overview
API keys, or Application Programming Interface keys, are alphanumeric codes used to authenticate and control access to web-based services or APIs (Application Programming Interfaces). These keys serve as unique identifiers for developers or applications seeking permission to interact with Anchore Enterprise. API keys are commonly employed in software development to manage and secure the flow of data between different applications, allowing authorized access while preventing unauthorized usage. They play a crucial role in ensuring the integrity, security, and controlled usage of APIs, acting as a form of digital credentials for developers to connect their applications to external services.
Generating API Keys
A system user can generate an API key for self use. Some users have specific RBAC roles (ie account-user-admin) that allow management of API keys for other system users.
For more details on generating and managing API keys, please refer to this section: Generating API keys
Generating API keys as an SAML (SSO) user
API keys for SAML (SSO) users are disabled by default.
To enable API keys for SAML users, please update your helm chart values file with the following:
anchoreConfig:
user_authentication:
allow_api_keys_for_saml_users: true
API keys are an additional authentication mechanism for SAML (SSO) users that bypasses the authentication control of the IDP.
When access has been revoked at the IDP, it does not automatically disable the user or revoke all API keys for the user.
Note
API keys are an additional authentication mechanism for SAML (SSO) users that bypasses the authentication control of the IDP. When access has been revoked at the IDP, it does not automatically disable the user or revoke all API keys for the user. Therefore, when access has been revoked for a user, the system administrator is responsible to manually delete the Anchore User or revoke any API key which was created for the user.Using API Keys
API keys are authenticated using basic auth. In order to use API keys you need to use a special username _api_key and the password is the value that was output when you created the API key.
e.g.
curl -u '_api_key:<API key value>' http://localhost:8228/v2/images
With AnchoreCTL:
ANCHORECTL_USERNAME="_api_key"
ANCHORECTL_PASSWORD="<API key value>"
Caveats for API keys
API Keys generally inherit the permissions and roles of the user they were generated for, but there are certain operations you cannot perform using API keys regardless of which user they were generated for:
- You cannot Add/Edit/Remove Users and Credentials.
- You cannot Add/Edit/Revoke API Keys.
18.2 - User Credential Storage
Overview
All user information is stored in the Anchore DB. The credentials can be stored as plaintext or in a hashed form using the Argon2 hashing algorithm.
Hashed passwords are much more secure, but can be more computationally expensive to compare. Hashed passwords cannot be used for internal service communication since they cannot be reversed. Anchore
provides a token based authentication mechanism as well (a simplified Password-Grant flow of Oauth2) to mitigate the performance issue, but it requires that
all Anchore services be deployed with a shared secret in the configuration or a public/private keypair common to all services.
Passwords
The configuration of how passwords are stored is set in the user_authentication section of the config.yaml file
and must be consistent across all components of an Anchore Enterprise deployment. Mismatch
in this configuration between components of the system will result in the system not being able to communicate internally.
user_authentication:
hashed_passwords: true|false
For all new deployments using the Enterprise Helm chart, hashed_passwords is defaulted to true.
All helm upgrades will carry forward the previous hashed_passwords setting.
NOTE: When the configuration is set to enable hashed_passwords, it must also be configured to use OAuth. When OAuth is not configured in the system, Anchore must be able to use HTTP Basic authentication between internal services and thus requires credentials that can be read.
Bearer Tokens/OAuth2
If Anchore is configured to support bearer tokens, the tokens are generated and returned to the user but never persisted in the database.
Users must still have password credentials, however. Password persistence and protection configuration still applies as in the Password section above.
Configuring Hashed Passwords and OAuth
NOTE: Password storage configuration must be done at the time of deployment, it cannot be modified at runtime or after installation with an existing DB since
it will invalidate all existing credentials, including internal system credentials and the system will not be functional. You must choose the mechanism
at system deployment time.
Set in config.yaml for all components of the deployment:
Option 1: Use a shared secret for signing/verifying oauth tokens
user_authentication:
oauth:
enabled: true
hashed_passwords: true
keys:
secret: mysecretvalue
Option 2: Use a public/private key pair, delivered as pem files on the filesystem of the containers anchore runs in:
user_authentication:
oauth:
enabled: true
hashed_passwords: true
keys:
private_key_path: <path to private key pem file>
public_key_path: <path to public key pem file>
Using environment variables with the config.yaml bundled into the Anchore provided anchore/enterprise image is also an option.
NOTE: These are only valid when using the config.yaml provided in the image due to that file referencing them explicitly as replacement values.
ANCHORE_AUTH_SECRET = the string to use as a secret
ANCHORE_AUTH_PUBKEY = path to public key file
ANCHORE_AUTH_PRIVKEY = path to the private key file
ANCHORE_OAUTH_ENABLED = boolean to enable/disable oauth support
ANCHORE_OAUTH_TOKEN_EXPIRATION = the number of seconds a token should be valid (default is 3600 seconds)
ANCHORE_OAUTH_REFRESH_TOKEN_EXPIRATION = the number of second a refresh token is valid (default is 86400 seconds)
ANCHORE_AUTH_ENABLE_HASHED_PASSWORDS = boolean to enable/disable hashed password storage in the anchore db instead of clear text
18.3 - LDAP
Overview
The Lightweight Directory Access Protocol (LDAP) is a standardized and widely-used client-server protocol for accessing directory information, and can be enabled in Anchore Enterprise Client to authenticate users against an existing directory server.
In order to configure Anchore Enterprise Client for use with LDAP, the requisite information for connecting and authenticating with an LDAP directory server must first be provided by an administrator. For the purposes of determining what users can see and do once they are logged in, the administrator must also create one or more account association entries, called user mappings.
When an LDAP user authenticates, the Anchore Enterprise account associated with their session is determined by the first user mapping containing a search filter that matches the information in their LDAP record. LDAP authentication will fail if no matches are found, if the associated account is disabled, or if the user’s login credentials are incorrect.
The following sections in this document describe how to configure the Anchore Enterprise Client for use with an LDAP directory server, how to add user mappings, and how to log in to the application as an LDAP user.
Server Connection Properties
Administrators can provide the information used to connect Anchore Enterprise Client to an LDAP server from the LDAP sidetab in the Configuration view. Please note that this sidetab is not visible to non-administrative users.
The connection property fields shown in this view are described below:
| Property | Description |
|---|
| Server URI | The ldap:// or ldaps:// URI of the LDAP directory server to query. |
| Manager DN | The distinguished name (DN) of an LDAP directory manager that the Anchore Enterprise Client can use to perform further queries about LDAP users during login. The directory manager is typically a privileged server administrator who, once authenticated, can access the LDAP record of any user intended to access the application. |
| Manager Password | The password associated with the Manager DN. |
| Base DN | The relative distinguished name in the LDAP directory tree hierarchy under which queries about users should be performed. |
After you have entered the required connection properties, click the Save button to store them. Once stored, you can click the Test button to verify that the application can authenticate with the LDAP server using the details you’ve provided.
Note: Clicking Save when no values are provided in any of the fields will disable LDAP in the application and prevent LDAP from being displayed as an authentication option on the login screen.
User Mappings
LDAP user mappings contain search filters that unite the results of searches made against the data attributes of LDAP records with account information stored in Anchore Enterprise.
When an LDAP user submits their credentials on the login page, the first match encountered will provide Anchore Enterprise Client with an associated Anchore Enterprise account that is used to define the scope of what the user can see and do once they are fully authenticated.
If a match is detected, the submitted password is then validated against the one stored inside the matched LDAP record. If the password is correct and the associated Anchore Enterprise account is not suspended, the user will be successfully logged in. If no match is found or the password is incorrect, authentication will fail.
Adding a User Mapping
User mappings can be created by administrators from inside an account within the Accounts sidetab in the Configuration view, or from the LDAP sidetab in the area below the server connection properties form.
To add a new user mapping containing an LDAP search filter, click the Add New LDAP User Mapping button—or if no user mappings are currently defined, click the Let’s add one! button in the empty table.
You will be presented a dialog, similar to the one shown below, where you can provide an LDAP search filter:

LDAP Search Filters
The LDAP search filter in each mapping provides the criteria for associating that mapping with an Anchore Enterprise account. For example:
uid=$USERNAME
In the above example, the user mapping requires that the uid (user ID) attribute in an LDAP record matches the data represented by the $USERNAME token.
The =$USERNAME string is a required entry, and the actual value of the token resolves to whatever value the user enters in the Username field when they log in to Anchore Enterprise Client.
In Microsoft® Active Directory® (AD) implementations that support the LDAP protocol, the sAMAccountName attribute is the broad equivalent of uid:
sAMAccountName=$USERNAME
Note: The submitted value of $USERNAME should always correspond to an attribute with a unique value within the LDAP user record, or one that is unique in combination with other criteria. In Active Directory, the uniqueness of sAMAccountName is enforced, whereas this may not be true for uid (which is an optional attribute in AD).
Additional filter criteria beyond the user identity can be provided to assert granular control over user access. The following examples describe filters with narrower scope:
(&(cn=$USERNAME)(|(ou:dn:=Administrative)(ou:dn:=Management)))
(&(ou=devops)(uniqueMember=uid=$USERNAME,dc=example,dc=org))
The following can be used with Microsoft Active Directory to verify a user is a member of a group “GroupB” or even nested group:
(&(objectCategory=Person)(sAMAccountName=$USERNAME)(memberOf:1.2.840.113556.1.4.1941:=CN=GroupB,OU=Users,OU=ad,DC=ad,DC=mydomain,DC=com))
In the example above you would replace the Group Distinguished Name (DN) of the group: GroupB,OU=Users,OU=ad,DC=ad,DC=mydomain,DC=com with a DN for a group to assert users are a part of in order for the search filter to match.
A detailed summary of the syntax and formula of LDAP search filters is beyond the scope of this document, however RFC 1558 provides a comprehensive description of how these entries are structured.
Mapping Order
By default, mappings are evaluated in priority order, with new entries being stored at the lowest priority. It can be challenging to infer the exact order of all mappings when they are spread across multiple accounts, so the table listing all current mappings the LDAP sidetab shows the priority of every item and includes the account with which they are associated. Example:

From here you can move row entries to a higher or lower order of precedence by clicking down on a hotspot

and then dragging the row up or down the list.
The priority order of user mappings determines the order in which search filters are evaluated when a user logs in. The first mapping to successfully locate an LDAP user record that matches the $USERNAME and any other criteria in its search filter will be used to determine the Anchore Enterprise account association for that user.
Once a user is located, subsequent mapping entries will be ignored, regardless of (possibly narrower) specificity, as only priority order matters here.
Test Mapping Behavior
You can evaluate the behavior of your user mappings by entering $USERNAME data (for example, the uid of a user) in the Check $USERNAME Against LDAP Mappings search field.
If an LDAP record is located that matches the search filter criteria of a mapping, you’ll be informed of which mapping provided the match, the associated Anchore Enterprise user, and the distinguished name of the user whose LDAP record was returned.
Login With LDAP Credentials
If a set of valid LDAP server connection properties have been stored by an administrator, the LDAP authentication option is activated in the application login view, in addition to the Default option of authenticating against the user records stored in Anchore Enterprise:

The value entered in the Username field will be used by the application to populate the $USERNAME token when evaluating each user mapping. The value entered in the Password field will be used to authenticate the matched user with the LDAP directory server.
Once these operations have completed, and providing the account associated with the mapping is not disabled, the user will be logged in.
18.4 - SSO
Overview
Anchore Enterprise can be configured to support user login to the UI using identities from external identity providers
that support SAML 2.0. Anchore never stores any credentials for the users, only their usernames
and Anchore permissions. All UI access is gated through a user’s valid login into the identity provider. Anchore uses the external
provider to verify username identity and initialize a username, account, and roles on first login for a new user. Once a
user’s identity is initialized in Anchore, the Anchore administrator can manage user permissions by managing the roles
associated with the user’s identity in Anchore itself.
Terms
SAML Terms:
- Identity Provider (IDP) - The service that stores the identity database and provides identity and authentication services to Anchore.
- Service Provider (SP) - The service providing resources to the end user, in this case, the Anchore Enterprise deployment.
- Assertion Consumer Service (ACS) - The consumer of SAML assertions generated by the Identity Provider. For Anchore Enterprise,
the UI proxies the SAML assertion to the Anchore Enterprise API service which consumes it, but the UI is the network
endpoint the user’s browser interacts with.
Anchore Terms:
- Native User - A user that exists in the Anchore DB and has login credentials (passwords).
- SAML User - A user that exists in the Anchore DB only with a username and permissions, but no credentials. This prevents any username
conflicts. SAML users will also be associated with a single Identity Provider. This prevents overlapping usernames from multiple Identity Providers gaining access to unexpected users or accounts.
How SAML integration works
When a user logs into the Anchore Enterprise UI, they can choose which Identity Provider to authenticate with. User credentials are never passed to Anchore Enterprise. Instead, other information about the user is passed from the Identity Provider to Anchore. Some information used by Anchore during login include the username, authenticating Identity Provider, associated account, and initial RBAC permissions.
After the initial login, RBAC permissions can be adjusted for this user directly by an Anchore administrator. This allows the Anchore administrator the ability to control access of Anchore users without having to gain access to the corporate IDP system.
Dynamic SAML User Provisioning
The first time a SAML User logs into Anchore, if the username is not found within the Anchore DB, a record will be automatically created for the user. If the user’s associated account is not found within the Anchore DB, an account record will also be automatically created at this time.
This is often referred to as Just In Time Provisioning (JIT).
Explicit Creation of SAML Users
An Anchore administrator has the ability to create other users with administrator privileges. This includes Native and SAML Users. When creating a SAML Administrator User, the username and the Identity Provider’s name will be required. Upon SSO login by this new user, it will be associated with account admin and have all the permissions of an Anchore administrator.
A global configuration mode is also available if SSO is the preferred method of login, but the Anchore administrator would like
explicit control over which users can gain access to Anchore Enterprise.
sso_require_existing_users: ${ANCHORE_SSO_REQUIRES_EXISTING_USERS}
When this configuration mode is set to true, any users who have permissions to create other users, will now have the ability to explicitly create SAML Users. As stated above, when creating a SAML User, the username and the Identity Provider’s name will be required. In addition, an RBAC role will also be needed for each SAML User creation. Upon SSO login by this new user, it will be associated with the account it was created in and have all the RBAC permissions provided for it.
When this configuration mode is set to true, SSO logins are only permitted within Anchore for users who have existing SAML user records fround in Anchore DB.
When explicitly creating SAML Users, the account and RBAC role provided will take precedent over any default values or IDP Attributes which may be configured in the SAML Configuration described below. For more information, please see Mapping.
Note: Any users that have previously authenticated via SSO will continue to have access regardless of the configuration mode setting. If you wish to prevent future access when setting sso_require_existing_users to true, simply delete the user record in Anchore.
SSO Login Validation
During subsequent SSO logins, Anchore will find an existing user record in the Anchore DB. The following information will be validated:
- The user record must be a SAML User. If the user was previously configured as a Native User and you want to convert it to a SAML User, simply delete the user record in Anchore and have the user log in again via SSO.
- The user record must be authenticating from the same Identity Provider. If the user has been changed to authenticate via a different Identity Provider, simply delete the user record in Anchore and have the user log in again via SSO.
Configuration Overview
In order to use SAML SSO, the Anchore Enterprise deployment must:
Have Oauth enabled. This is required so that Anchore can issue bearer tokens for subsequent API usage by the UI to the system APIs.
Using hashed passwords is optional but highly recommended. See User Authentication
for more information on configuring OAuth and hashed password storage.
Be able to reach the IDP login URL from the user’s browser.
Be able to reach the metadata XML endpoint in the IDP (if using url).
Configuration of SAML SSO is done via API/UI operations but requires configuration both in your Identity Provider and in Anchore.
In the IDP:
- Must support HTTP Redirect binding
- Should support signed assertions and signed documents
- Must allow unsigned client requests from Anchore
- Must allow unencrypted requests and responses
Anchore IDP Configuration Fields are as follows.
- Name - The name to use for this configuration. It will be part of the UI’s /service/auth/sso/ route as well as
the /saml/sso/ and /saml/login/ routes that are used to implement SSO.
- Enabled - Whether auth via this configuration is allowed.
- ACS HTTPS Port - HTTPS port if non-standard. If omitted or -1, 443 is used.
- SP Entity ID - The identity for the Anchore system to present when requesting auth from the SAML IDP. This is typically
a URL identifying the Anchore deployment.
- ACS URL - The URL to which SAML Responses should be sent from the IDP. For UI usage, this should be the hostname and
port of the UI deployment and a path: /service//sso/auth/{idp config name}.
- Default Account - If set, this is the account that SSO users will be initialized to be members of upon sign-in the
first time. This property or IDP Account Attribute must be set.
- Default Role - The role that will be granted to new users on first sign-in. Use this setting to apply a
consistent role to all users if you do not want that data imported from the IDP. This property or IDP Role Attribute must be set.
- IDP Account Attribute - A SAML assertion attribute name from the SAML responses that Anchore will use to determine
the account name to initialize the user into. If the account does not exist, it is created. For more information on the
initialization process see Initializing User Identities below. This property or Default Account must be set.
- IDP Username Attribute - A SAML assertion attribute name from the SAML responses that Anchore will use to determine
the username for the anchore identity. This is optional and typically will not need to be set. If omitted, the SAML Subject is used and this should meet most needs.
- IDP Metadata URL - URL to retrieve the IDP metadata xml from. This value is mutually exclusive with IDP Metadata XML,
so only one of the two properties may be specified.
- IDP Metadata XML - Raw XML for the IDP metadata. This value is mutually exclusive with IDP Metadata URL, so only one
of the two properties may be specified.
- IDP Role Attribute - The SAML assertion attribute from the SAML responses that Anchore will use to initialize a user’s
roles. This may be a multi-value property. This property or Default Account must be set.
- Require Signed Assertions - If true, require the individual assertions in the SAML response to be signed by the IDP.
- Require Signed Response - If true, require the SAML response document to be signed.
Using SAML Attributes to Initialize Users and Account in Anchore
The properties of the user including the account it belongs to, the roles it has in that account as well as any other accounts the user has role access to
are all initialized based on the combination of the Anchore IDP configuration and the SAML response presented by the IDP at the user’s first login.
See Mapping for more information on that process and how the configuration works.
Deleting SAML SSO Configuration
An Anchore administrator has the ability to create, modify, and delete the SAML Configuration. During deletion of the SAML Configuration, any user that was created with this Identity Provider, either dynamically or explicitly, will also be deleted.
18.4.1 - Mapping SSO Identities into Anchore
Overview of Mapping External Identities into Anchore
Anchore SSO support provides a way to keep users’ credentials centrally stored in a corporate Identity
Provider and outside of the Anchore deployment. Anchore’s SSO approach uses the external identity
store to authenticate a user and bootstrap its permissions using Anchore’s RBAC system. For each login, the user’s
identity is verified against the external provider but once the identity is initialized inside the Anchore deployment, its
access to resources is controlled by the Anchore Enterprise RBAC system. This approach allows Anchore admins to manage user
access without having to require administrator access to a corporate or central IT identity system while still being able
to leverage that system for defining identity and securing access credentials.
The identity mapping process has two distinct phases:
- Initial identity bootstrap - Occurs on the first login of a user to Anchore causing dynamic construction of an Anchore user record.
- Identity verification and assertion validation - Validates the administrators requirements against the external identity record on each login.
Defining the Username
By default, with SSO, the SAML Assertion’s “Subject” attribute is used to define the username. Using the subject is the
right solution in most situations, but in extreme cases it may be necessary to provide the username in some other form via
attributes in the SAML Response. This behavior can be configured by setting: idp_username_attribute in the SAML Configuration
within Anchore. This should only be used when the subject either cannot be used due to it being a transient ID as configured by the
IDP itself, or you want the username to map to some form other than the IDP’s username, email, or persistent ID.
If the idp_username_attribute is set to an attribute name, and that attribute is not found or has no value in the SAML
Response presented during login, then that user login will be rejected by Anchore.
If idp_username_attribute is an empty string or null, then the SAML Response’s subject attribute is used as the username.
This is the default behavior.
Defining the Account the User Belongs To
In Anchore, all users belong to an Account. When an SSO user logs into Anchore UI for the first time, the identity is initialized
with the username (as defined above), but the account to which the user belongs is configurable via a separate pair of configuration
properties in the SAML Configuration within Anchore. These configuration properties are mutually exclusive.
idp_account_attribute - If set in the SAML Configuration, this attribute must be found within the
SAML Response during each login for every user. The attribute value received is the ‘account name’. It must also be valid.
A valid value must be greater than three characters and must not be a reserved account name such as ‘admin’ or ‘anchore-system’
If the attribute is not found within the SAML Response or the value is not valid, the login is rejected.
default_account - If set in the SAML Configuration, it’s value is the account all users that login
from this IDP will be assigned.
- In both cases, on the initial login by the user, if the account does not already exist within Anchore, an
external account with that name is created.
Defining the User’s Initial Roles
In Anchore, all users are allowed to have one or more Roles that describe a set of access permissions.
Roles are assigned to the user via a separate pair of configuration properties in the SAML Configuration within Anchore.
These configuration properties are mutually exclusive.
idp_role_attribute - If set in the SAML Configuration, the attribute must be found within the
SAML Response during each login for every user. The attribute value received is one or more ‘role name’. The value must also be valid.
If the attribute is not found within the SAML Response or the value is not valid, the login is rejected.
default_role - If set in the SAML Configuration, it’s value will be the single role set for all users that login with this IDP.
During a user’s first login, this role will be set on the account during user identity initialization. On subsequent logins for this user, the value will be ignored.
Revoking SSO User Access
- Disable the Anchore account. Any user, SSO or otherwise, that is a member of a disabled account cannot log in or perform API operations.
- If using
idp_account_attribute or idp_role_attribute, simply remove or zero that attribute at the IDP for that user or group.
All affected users will no longer be able to log in to Anchore.
Changing the Anchore SAML Configuration
Initialization of identities and roles occurs on the user’s first login. Once initialized, the configuration must match the
SAML Response presented during each login for the user to log in.
Thus, changes to the SAML Configuration within Anchore may affect subsequent logins for your users.
For instance, if you change the SAML Configuration within Anchore to start using attributes
instead of defaults, a user’s SAML Response will need to contain the same attributes. Failure to find the correct attribute(s) with valid values will prevent the user’s login.
Example SSO configurations
Anchore and an external Identity Provider
Here are examples for both Okta and KeyCloak that provide simple defaults and identity mappings.
Identity Mapping configuration
Below are example configuration values for a single SAML Configuration within Anchore to achieve different behavior:
All SSO users in one account with the same read-write permissions:
- default_account = ‘account’
- default_role = ‘read-write’
SSO users in accounts managed by the IDP property, for example a ‘groups’ property:
default_account = nulldefault_role = nullidp_account_attribute = "primary_group"idp_role_attribute = "roles"- Will initialize the user with the roles specified in the ‘roles’ attribute for the accounts in the ‘primary_group’ attribute.
- E.g. if ‘primary_group’ = [’testers’], and ‘roles’ = [‘read-only’] for a user, [email protected]
- [email protected] will be initialized at login as username = [email protected] in account testers with role read-only
- Because the account is from an attribute, [email protected] might have ‘primary_group’ = [‘security_engineers’] and
thus be initialized in a different account in Anchore.
18.4.1.1 - KeyCloak SAML Example
Configuring SAML SSO for Anchore with KeyCloak
The JBoss KeyCloak system is a widely used and open-source identity management system that supports integration with applications via SAML and OpenID Connect. It also can operate as an identity broker
between other providers such as LDAP or other SAML providers and applications that support SAML or OpenID Connect.
The following is an example of how to configure a new client entry in KeyCloak and configure Anchore to use it to permit UI login by KeyCloak users that are granted access via KeyCloak configuration.
Configuring KeyCloak
Anchore supports multiple IDP configurations, each given a name. For this example we’ll choose the name “keycloak” for our configuration.
This is important as that name is used in several URL paths to ensure that the correct configuration is used for validating responses,
so make sure you pick a name that is meaningful to your users (they will see it in the login screen) and also that is url friendly.
Some config choices and assumptions specifically for this example:
- Let’s assume that you are running Anchore Enterprise locally. Anchore Enterprise UI is available at:
https://localhost:3000. Replace with the appropriate url as needed. - We’re going to choose
keycloak as the name of this saml/sso configuration within Anchore. This will identify the specific configuration and is used in urls. - Based on that, the Single-SignOn URL for this deployment will be:
https://localhost:3000/service/sso/auth/keycloak - Our SP Entity ID will use the same url:
http://localhost:3000/service/sso/auth/keycloak
Add a Client entry in KeyCloak
See SAML Clients in KeyCloak documentation
For this example, set the following values in “Add Client” screen (these are specific to the settings in this example described above):
- Client ID -
http://localhost:3000/service/sso/auth/keycloak - This will be the SP Entity ID used in the Anchore configuration later - Client Protocol: “saml”
- Client SAML Endpoint: “http://localhost:3000/service/sso/auth/keycloak”
In the next screen, Client Settings

Name - “Anchore Enterprise”. This is only used to display a friendly name to Keycloak users in the KeyCloak UI. Can use any name you like.
Enabled - Select on
Include Authn Statement - Select on
Sign Documents - Select on
Client Sign Authn Requests - Select Off
Sign Assertions - Select off
Encrypt Assertions - Select off
Client Signature Required - Select off
Force Post Binding - Select off. Anchore requires the HTTP Redirect Binding to work, so this setting must be off to enable that.
Force Name ID Format - Select on
Name ID Format - Select username or email (transient uses a generated UUID per login and persistent use the Keycloak user’s UUID)
Root URL - Leave empty
Valid Redirect URIs - Add http://localhost:3000/service/sso/auth/keycloak
Base URL - Leave empty
Master SAML Processing URL - http://localhost:3000/service/sso/auth/keycloak
Fine Grain SAML Endpoint Configuration
- Assertion Consumer Service Redirect Binding URL -
http://localhost:3000/service/sso/auth/keycloak
Save the configuration

Download the metadata xml to import into Anchore
- Select ‘Installation’ tab.
- Select Format
- Select Format Option - SAML Metadata IDPSSODescriptor

- Select Format Option - Mod Auth Mellon files

- Unzip the downloaded .zip and locate
idp-metadata.xml

- Download or copy the XML to save in the Anchore configuration
Partial Scoping for the Anchore Enterprise Client in Keycloak
By default, the effective scopes include all roles declared in the Keycloak realm. Anchore Enterprise expects to be able to map roles from Keycloak to roles within Anchore, so limiting it to partial scope instead of full scope prevents sending extra roles to Anchore that cannot be correctly interpreted. To change this default behavior, toggle Full Scope Allowed to OFF and declare the specific roles you want in each client under the Clients –> Anchore Enterprise Client Details –> Dedicated Scopes, Scope tab.

You’ll need the following information from keycloak in order to configure the SAML record within Anchore:
The name to use fo the configuration, in this example keycloak
Metadata XML downloaded or copied from the previous section
In the Anchore UI, create an SSO IDP Configuration:
Login as admin
Select “Configuration” Tab on the top
Select “SSO” on the left-side menu
Click “Let’s Add One” in the configuration listing

- Enter the values:
- Name: “keycloak” - This is the name of the configuration and will be referenced in login and sso URLs, so we use the value chosen at the beginning of this example
- Enabled: True - This controls whether or not users will be able to login with this configuration. We’ll enable it for the example but can disable later if no longer needed.
- ACS HTTPS Port: -1 or 443 - This is the port to use for HTTPS to the ACS (Assertion Consumer Service, in this case the UI). It is only needed if you need to use a non-standard https port
- SP Entity ID:
http://localhost:3000/service/sso/auth/keycloak (NOTE: this must match the Client ID you used for the Client in the KeyCloak setup - ACS URL:
http://localhost:3000/service/sso/auth/keycloak - Default Account:
keycloakusers for this example, but can be any account name (existing or not) that you’d like the users to be members of. See Mappings for more information on how this - Default Role:
read-write for this example so that the users have full access to the account to analyze images, setup policies, etc. - IDP Metadata XML: Paste the downloaded or copied XML from KeyCloak in step 4.3 above
- Require Signed Assertions - Select off
- Require Signed Response - Select on
- Save the configuration

You should now see a ‘keycloak’ option in the login screen for the Anchore Enterprise UI. This will redirect users to login to the KeyCloak instance for their username/password and will create a new user in Anchore in the keycloakusers account with read-write role.
18.4.1.2 - Microsoft Entra ID SAML Example
Azure Enterprise Applications allow identities from an Azure Directory to be federated via Single Sign On (SSO) to other applications. In doing so Azure is acting as a SAML Identity Provider (IdP) that can be used with Anchore Enterprise as a SAML Service Provider (SP).
Configuring Azure
Anchore supports multiple IDP configurations, each given a name. For this example we’ll choose the name “azure” for our configuration.
This is important as that name is used in several URL paths to ensure that the correct configuration is used for validating responses,
so make sure you pick a name that is meaningful to your users (they will see it in the login screen) and also that is url friendly.
Some config choices and assumptions specifically for this example:
- Let’s assume that you are running Anchore Enterprise locally. Anchore Enterprise UI is available at:
https://anchore.example.com. Replace with the appropriate url as needed. - We’re going to choose
azure as the name of this saml/sso configuration within Anchore. This will identify the specific configuration and is used in urls. - Based on that, the Single-SignOn URL for this deployment will be:
https://anchore.example.com/service/sso/auth/azure - Our SP Entity ID will use the same url:
https://anchore.example.com/service/sso/auth/azure
Azure Setup
Create a generic Enterprise Application in Azure.

Navigate to the Azure portal: https://portal.azure.com
Type “Enterprise Applications” into the search bar in the top middle of the screen and click on it.
Click on Create your own application near the upper left.
Select SAML as the single sign-on method.

From your new Azure AD Enterprise Application select Single sign-on.

Select Edit Basic SAML Configuration (section 1).

For both Identifier (Entity ID) & Reply URL (Assertion Consumer Service URL) enter the URL for your Anchore deployment along with: “/service/sso/auth/azure”. The word “azure” can be customized. This will become the name of the SSO configuration that users will see each time they login via SSO. Example URL: https://anchore.example.com/service/sso/auth/azure (Make note of the URL for upcoming steps) - Click Save when finished

Copy the “App Federation Metadata Url” found in section 3. This will be used in the next section.

Configure Users and Groups that will be allowed to login to Anchore.

Select Users and groups under Manage.
Click Add user/group.
Click on the hyper-linked “None Selected”.
Select/Check users and/or groups who will be granted access to login to Anchore.
Press Select when finished.
Ensure you have a non-admin Account created in Anchore. In this example I am creating an account named “saml” and setting it as the default account to create users who use this SSO configuration but do not already exist in Anchore.

Login to Anchore and navigate to System, SSO and click on Add new SAML IDP.

Enter the values (Note that all values can be changed except Name):
- Under “Name” enter “azure” or whatever you choose to name the SSO integration.
- Enter the URL (https://anchore.example.com/service/sso/auth/azure in this example) under “SP Entity ID” and “ACS URL”. This URL was known as Entity ID and Reply URL in Azure.
- Select the account created or selected in step 1 for “Default Account”.
- Select the appropriate role for “Default Role”.
- Paste the Federation Metadata URL from the previous section into “IDP Metadata URL”.
- Uncheck “Require Signed Response?”.

Save the configuration, configuration is complete when you see a login with ‘azure’ option on the login screen.
Users can now log in to your Anchore deployment using this Azure endpoint.
See: Mapping Users and Roles in SSO for more information on using the account
and role defaults, IDP attribute values and understanding how identities are mapped into Anchore’s RBAC system.
Using Azure Groups with Anchore User Groups
User groups in Anchore can grant users access to multiple Anchore accounts with varying/selectable access levels in each.
In this example we have two teams within the organization named TeamA and TeamB. We will create a group in Azure for each team that will be sent to Anchore upon SAML login where each team will have their own Anchore account. We can optionally grant each team read-only access to the other teams account.
To map groups from Azure to Anchore:
Create an account in Anchore for TeamA and TeamB.

In Azure create or add desired groups to the “Users and Groups” section of your Anchore SSO Enterprise Application.

In Anchore create (a) user group(s) matching group names from Azure. Please note that the name of a user group cannot be changed but its contents can be changed at any time. For the sake of this example add both the TeamA and TeamB accounts. Grant the TeamA user group full control to the TeamA account and read-only to the TeamB account. When adding the user group for TeamB grant full-admin access to the TeamB account and read-only access to the TeamA account.

In your Azure Enterprise Application under Single Sign On select edit on Attributes and Claims, section 2.

Click on Add a group claim.

For “Which groups associated with the user should be returned in the claim” Select “Groups assigned to the application”

- For Source attribute select “Cloud-only group display names”
- Expand Advanced Options
- Check “Customize the name of the group claim”
- Check “Emit groups as role claims”
Edit your Anchore SAML Identity Provider and enter “http://schemas.microsoft.com/ws/2008/06/identity/claims/role" in the “IDP User Groups Attribute”. Under User Groups select TeamA and TeamB.

At this point when logging in via azure SSO a user will either land in the Default Account and need to switch account from the drop down in the upper right or if an IDP Account Attribute was configured to initially put them in the desired account they would only need to switch accounts appropriately.

18.4.1.3 - Okta SAML Example
Configuring SAML SSO for Anchore with Okta
Some config choices and assumptions specifically for this example:
- Anchore UI endpoint:
http://localhost:3000. Replace with the appropriate url as needed. - IDP Config Name:
okta. This will identify the specific configuration and is used in urls, and can be any url-safe string you’d like. - The Single Sign-on URL (also called the Assertion Consumer Service/ACS URL) for this deployment will be:
http://localhost:3000/service/sso/auth/okta.
This is constructed with the UI endpoint and path /service/sso/auth/{IDP Config Name} - Our SP Entity ID will use the same url:
http://localhost:3000/service/sso/auth/okta. This could be different but for simplicity we use the same value.
See Okta SAML config to see how to create a new
application authorization server. The following steps are used during specific steps of that walk-thru

- In step #6
Single sign on URL, this is the URL Okta will direct users to. This must be a URL in the Anchore Enterprise UI
based on the name you chose for the configuration. In our example: http://localhost:3000/service/sso/auth/okta- Set the
Use this for Recipient URL and Destination URL checkbox as well.
a1. Set the Audience URI(SP Entity ID) to a URI that will identify the anchore installation. This can be the same as
the single-sign-on URL for simplicity. We’ll need to enter this value later in the Anchore config as well. - Leave
Default RelayState empty Name ID format can be left “Unspecified” or set to an email or username format.- Choose the application username that makes sense for your install. Anchore can support a regular username or email address for the usernames.
- In step #7, these attribute statements are not required but can be set. This is, however, where you can set additional
attributes that you want Anchore to use to initialize the user’s Anchore account or permission set. Later in the SAML Configuration
you can specify attributes that Anchore will look for to extract the account name and roles for initializing a user that doesn’t yet exist in Anchore.
- In step #9, be sure to copy the metadata URL link so you have that. Anchore will need that value.
- Right-click here and copy the link address:
 The
URL should be something like:
The
URL should be something like: https://<youraccount>.okta.com/app/<appid>/sso/saml/metadata
- Finish the setup and save the Application entry.
- Important: To allow Okta users to login to Anchore you need to assign the Okta user to this new Application entry. See
Assign and unassign apps to users for information on this process.
You’ll need the following information from okta to enter in the Anchore UI:
- The name chosen for the configuration:
okta in this case - Metadata XML URL (from “configuring okta” step 3.1 above)
- The Single Sign-on/ACS URL described in Step 3
In the Anchore UI, create an SSO Idp Configuration:
- Login as admin
- Select “Configuration” Tab on the top
- Select “SSO” on the left-side menu
- Click “Let’s Add One” in the configuration listing

And…

Enter the values:
- Name:
okta - This is the name of the configuration and will be referenced in login and sso URLs, so we use the value
chosen at the beginning of this example - Enabled: True - This controls whether or not users will be able to login with this configuration. We’ll enable it for
the example but can disable later if no longer needed.
- ACS HTTPS Port: -1 or 443 - This is the port to use for HTTPS to the ACS (Assertion Consumer Service, in this case the UI). It is only needed if you need to use a non-standard https port
- ACS URL:
http://localhost:3000/service/sso/auth/okta - Default Account - The account to add all okta users to when they login, for this example we use
oktausers - Default Role - The role to grant okta users when they login in initially. For this example, we use
read-write, the standard user type that has most abilities except user management. - IDP Metadata URL - The url from “Configure Okta” step 3.1
- Require Signed Assertions - Select On
- Require Signed Response - Select On
Save the configuration, configuration is complete when you see a login with ‘okta’ option on the login screen.
Users can now log in to your Anchore deployment using this Okta endpoint.
See: Mapping Users and Roles in SSO for more information on using the account
and role defaults, IDP attribute values and understanding how identities are mapped into Anchore’s RBAC system.
19.1 - User Management
Introduction
In this section you will learn how to create accounts, users, and role assignment with the Anchore Enterprise UI.
Assumptions
- You have a running instance of Anchore Enterprise and access to the UI.
- You have the appropriate permissions to create accounts, users, and roles. This means you are either a user in the admin account, or a user that already is a member of the account-users-admin role for your account.
For more information on accounts, users, roles, and permissions see: Role Based Access Control
Navigation
- After a successful login, navigate to the System tab on the main menu found on the left.
Creating Accounts
In order to create accounts, navigate to the accounts tab from inside the configuration view and select “Create New Account”.
Upon selection, a popup window will display asking for two items:
- Account Name (required)
- Email
In the following example I’ve created a ‘security’ account:

Now that a group has been created, I can begin to add users to it.
Viewing Role Permissions
To view the permissions associated with a specific role using the UI, select an account, and navigate to the roles tab:

To view the members in the account assigned to a specific role, select the ‘View’ button on the right-hand side.
Creating Users and assigning Roles
Upon immediate creation of an account, there will, by default be zero users. To add users, select the edit button corresponding the account you would like to add users to. This will bring you to the account page, where you can add your first user by selecting the “Let’s add one!” button.
Upon selection, a popup window will display asking for three items:
- Username (required)
- Password (required)
- Assign Role(s)
- Note that you can assign more than one role to a user. For a normal user with full access to add, update, and evaluate images, we recommend assigning the read-write role. The other roles are for specific use-cases such as CI/CD automation, and read-only access for reporting. See: Role Based Access Control from more details on the roles and their capabilities.
In this case I’ve assigned three roles to the user:

Once ‘OK’ is selected, the user will be created and you will be able to edit or remove the user as needed.
Deleting and Disabling Accounts
In order to delete an account, disable the account by sliding the button under the ‘Active’ column for the corresponding account, then select the ‘Remove’ button on the right-hand side.
A few notes to keep in mind when deleting accounts:
- The ‘admin’ account is locked and cannot be deleted.
- Once deletion is in progress, all resources (users, images, automated tasks, etc) will start a garbage collection process and won’t be viewable. Although it will still be present in the list to prevent admins from adding an account with the same name.
- Once deleted, an account and their associated resources can’t be recovered.
A couple notes on disabling accounts:
- Disabling accounts is a way for administrators to freeze an account while still keeping any associated analysis info intact.
- Any automated tasks associated with the disabled account will be frozen.
Switching Account Data Context
System administrator users are able to view another account’s data context using the dropdown located at the top-right:

Generating API Keys
Enterprise release 5.1 adds support for API keys for various operations. This is to facilitate use-cases where the user does not want to expose their main credentials e.g. integrations can switch to using API keys instead of username/password credentials.
In order to generate an API key, navigate to the Enterprise UI and click on the top right button and select ‘API Keys’:

Clicking ‘API Keys’ will present a dialog that lists your active, expired and revoked keys:

To create a new API key, click on the ‘Create New API Key’ and this will open another dialog where it asks you for relevant details for the API key:

You can specify the following fields:
- Name: The name of your API key. It is mandatory and unique i.e. you cannot have two API keys with the same name.
- Description: An optional text descriptor for your API key.
- Expiry Date: An expiry date for your API key, you cannot specify a date in the past and it cannot exceed 365 days by default.
Click save to save your API key, the UI will display the output of the operation:

NOTE!: Make sure you copy the value that’s output, there is no way to get this key value back.
Revoking API keys
If there is a situation where you feel your API key has been compromised, you can revoke an active key. This prevents the key from being used for authentication.
To revoke a key, click on the ‘Revoke’ button next to a key:

NOTE: Be careful revoking a key, this is an irreversible operation i.e. you cannot mark it active later.
The UI by default only displays active API keys, if you want to see your revoked and expired keys, check the toggle to ‘Show only active API keys’:

Managing API Keys as an Admin
As an account admin you can manage API keys for all users in the account you are admin in.
A global admin can manage API keys across all accounts and all users.
To access the API keys as an admin, click on the ‘System’ icon and navigate to ‘Accounts’:

Click ‘Edit’ for the account you want to manage keys for and click on the ‘Tools’ button against the user you wish to manage keys for:

19.2 - Accounts and Users
System Initialization
When the system first initializes it creates a system service account (invisible to users) and a administrator account (admin) with a single administrator user (admin). The password for this user is set at bootstrap using a default value or an override available in the config.yaml on the catalog service (which is what initializes the db). There are two top-level keys in the config.yaml that control this bootstrap:
default_admin_password - To set the initial password (can be updated by using the API once the system is bootstrapped). Defaults to foobar if omitted or unset.
default_admin_email - To set the initial admin account email on bootstrap. Defaults to admin@myanchore if unset
Managing Accounts Using AnchoreCTL
These operations must be executed by a user in the admin account. These examples are executed from within the enterprise-api container if using the quickstart guide:
First, exec into the enterprise-api container, if using the quickstart docker compose. For other deployment types (eg. helm chart into kubernetes), execute these commands anywhere you have AnchoreCTL installed that can reach the external API endpoint for you deployment.
docker compose exec enterprise-api /bin/bash
To list all the currently present accounts in the system, perform the following command:
anchorectl account list
✔ Fetched accounts
┌──────────┬────────────────────┬──────────┐
│ NAME │ EMAIL │ STATE │
├──────────┼────────────────────┼──────────┤
│ admin │ admin@myanchore │ enabled │
│ devteam1 │ [email protected] │ enabled │
│ devteam2 │ [email protected] │ enabled │
└──────────┴────────────────────┴──────────┘
To review the list of users for a specific account, issue the following:
anchorectl user list --account devteam1
✔ Fetched users
┌───────────────┬──────────────────────┬──────────────────────┬────────┬────────┐
│ USERNAME │ CREATED AT │ LAST UPDATED │ SOURCE │ TYPE │
├───────────────┼──────────────────────┼──────────────────────┼────────┼────────┤
│ devteam1admin │ 2022-08-25T17:43:43Z │ 2022-08-25T17:43:43Z │ │ native │
└───────────────┴──────────────────────┴──────────────────────┴────────┴────────┘
Adding a New Account
To add a new account which, by default, will have no active credentials, issue the following command:
anchorectl account add devteam1 --email [email protected]
✔ Added account
Name: devteam1
Email: [email protected]
State: enabled#
Note that the email address is optional and can be omitted.
At this point the account exists but contains no users. To create a user with a password, see below in the Managing Users section.
Disabling Account
Disabling an account prevents any of that account’s users from being able to perform any actions in the system. It also disabled all asynchronous updates on resources in that account, effectively freezing the state of the account and all of its resources. Disabling an account is idempotent, if it is already disabled the operation has no effect. Accounts may be re-enabled after being disabled.
Note
The admin account may not be disabled.anchorectl account disable devteam1
✔ Disabled account
State: disabled
Enabling an Account
To restore a disabled account to allow user operations and resource updates, simply enable it. This is idempotent, enabling an already enabled account has no effect.
anchorectl account enable devteam1
✔ Enabled account
State: enabled
Deleting an Account
Warning
Deleting an account is irreversible and will delete all of its resources (images, policies, evaluations, reports, etc).Deleting an account will synchronously delete all users and credentials for the account and transition the account to the deleting state. At this point the system will begin reaping all resources for the account. Once that reaping process is complete, the account record itself is deleted. An account must be in a disabled state prior to deletion. Failure to be in this state results in an error:
anchorectl account delete devteam1
error: 1 error occurred:
* unable to delete account:
{
"detail": {
"error_codes": []
},
"httpcode": 400,
"message": "Invalid account state change requested. Cannot go from state enabled to state deleting"
}
So, first you must disable the account, as shown above. Once disabled:
anchorectl account disable devteam1
✔ Disabled account
State: disabled
# anchorectl account delete devteam1
✔ Deleted account
No results
# anchorectl account get devteam1
✔ Fetched account
Name: devteam1
Email: [email protected]
State: deleting
Managing Users Using AnchoreCTL
Users exist within accounts, but usernames themselves are globally unique since they are used for authenticating api requests. User management can be performed by any user in the admin account in the default Anchore Enterprise configuration using the native authorizer. For more information on configuring other authorization plugins see: Authorization Plugins and Configuration.
Create User in a User-Type Account
To create a new user credential within a specified account, you can issue the following command. Note that the ‘role’ assigned will dictate the API/operation level permissions granted to this new user. See help output for a list of available roles, or for more information you can review roles and associated permissions via the Anchore Enterprise UI. In the following example, we’re granting the new user the ‘full-control’ role, which gives the credential full access to operations within the ‘devteam1’ account namespace.
ANCHORECTL_USER_PASSWORD=devteam1adminp4ssw0rd anchorectl user add --account devteam1 devteam1admin --role full-control
✔ Added user devteam1admin
Username: devteam1admin
Created At: 2022-08-25T17:50:18Z
Last Updated: 2022-08-25T17:50:18Z
Source:
Type: native
# anchorectl user list --account devteam1
✔ Fetched users
┌───────────────┬──────────────────────┬──────────────────────┬────────┬────────┐
│ USERNAME │ CREATED AT │ LAST UPDATED │ SOURCE │ TYPE │
├───────────────┼──────────────────────┼──────────────────────┼────────┼────────┤
│ devteam1admin │ 2022-08-25T17:50:18Z │ 2022-08-25T17:50:18Z │ │ native │
└───────────────┴──────────────────────┴──────────────────────┴────────┴────────┘
That user may now use the API:
ANCHORECTL_USERNAME=devteam1admin ANCHORECTL_PASSWORD=devteam1adminp4ssw0rd ANCHORECTL_ACCOUNT=devteam1 anchorectl user list
✔ Fetched users
┌───────────────┬──────────────────────┬──────────────────────┬────────┬────────┐
│ USERNAME │ CREATED AT │ LAST UPDATED │ SOURCE │ TYPE │
├───────────────┼──────────────────────┼──────────────────────┼────────┼────────┤
│ devteam1admin │ 2022-08-25T17:50:18Z │ 2022-08-25T17:50:18Z │ │ native │
└───────────────┴──────────────────────┴──────────────────────┴────────┴────────┘
Deleting a User
Using the admin credential, or a credential that has a user management role assigned for an account, you can delete a user with the following command. In this example, we’re using the admin credential to delete a user in the ‘devteam1’ account:
ANCHORECTL_USERNAME=admin ANCHORECTL_ACCOUNT=admin ANCHORECTL_PASSWORD=foobar anchorectl user delete devteam1admin --account devteam1
✔ Deleted user
No results
Updating a User Password
Note that only system admins can execute this for a different user/account.
As an admin, to reset another users credentials:
ANCHORECTL_USER_PASSWORD=n3wp4ssw0rd anchorectl user set-password devteam1admin --account devteam1
✔ User password set
Type: password
Value: ***********
Created At: 2022-08-25T17:58:32Z
To update your own password:
ANCHORECTL_USERNAME=devteam1admin ANCHORECTL_PASSWORD=existingp4ssw0rd ANCHORECTL_ACCOUNT=devteam1 anchorectl user set-password devteam1admin
❖ Enter new user password : ●●●●●●●●●●●
❖ Retype new user password : ●●●●●●●●●●●
✔ User password set
Type: password
Value: ***********
Created At: 2022-08-25T18:00:35Z
Or, to perform the operation fully-scripted, you can set the new password as an environment variable:
ANCHORECTL_USERNAME=devteam1admin ANCHORECTL_PASSWORD=existingp4ssw0rd ANCHORECTL_ACCOUNT=devteam1 ANCHORECTL_USER_PASSWORD=n3wp4ssw0rd anchorectl user set-password devteam1admin
✔ User password set
Type: password
Value: ***********
Created At: 2022-08-25T18:01:19Z
19.3 - Data Account/Context Switching
Overview
Administrators and specially-entitled standard users are offered the ability to context switch between the image analysis data contexts of different accounts. This capability allows you to view the analysis data held inside a different account while still retaining your own user profile configuration.
When you switch data context, the data-oriented aspects of the application will change but the qualities specific to your original account—herein referred to as your actual account—remain the same. Administrators keep their original permission set and have full control within the switched account. The account availability and associated permission set for standard users is decided by the role configuration of their switching entitlement, and these roles can be additionally set to differ per account.
This feature allows users to gain insights into multiple datasets, can be used by administrators for troubleshooting purposes or to make ad-hoc modifications to the data-oriented aspects of any account, and provides standard users with an additional level and vector of access control.
This following sections in this document describes how to switch and reset data contexts—both as an administrator and as a standard user—and how administrators can assign this capability to standard users.
Administrative Users
Context switching as as an administrator is available without prior configuration, and only requires that an account other than your own be available. When you click the account button in the top-right of the screen you are presented with a menu that contains an entry called Switch Account Data Context, which will be enabled when one or more accounts other than your own are present.
Clicking this item displays a submenu that describes all currently available accounts—both active and disabled—into which you can switch context:

Your home account is represented by the label Actual. If an account is disabled, this is indicated by the label Disabled (note that only administrators can context switch into disabled accounts). The account category—administrator or standard user—is indicated by the user-type icon.
Your current data context is represented by an entry with an emphasized title and checkmark prefix. When you click an entry for a different account, the application view will switch to use the data provided by this new context. The account button and dropdown items are similarly updated to reflect this change:

You will also notice a change to the background color of the main view, which serves as a reminder that your current data context is now different than the one provided by your actual account. In addition, a button is now present on the navigation bar that allows you to immediately revert to your actual data context when clicked (you can of course also use the menu to do this):

In the above example, the analysis information now presented is exactly what a user of the standard account would see in their actual account. As an administrator, you are now free to browse and interact with this data, add tags or repositories for analysis, create policies etc., and there are no permission restrictions on any of these operations.
Note: only the analysis data context has switched, and this new state does not extend to application data items such a private registry configurations.
Standard Users
Non-administrative users can also switch context if this capability has been conferred upon them by an administrator.
When you add a new standard user (or modify an existing one) you can optionally associate them with one or more additional accounts, providing those accounts are not currently disabled. The Add a New User dialog, which is accessed from within the account editor in the Configuration > Accounts view, is shown below:

Note: If an account is currently active and available for addition, but is subsequently disabled, the standard user will not be able to switch into that account.
For each associated account you must also provide one or more RBAC roles that determine how the standard user can interact with that account after they have switched context:

For example, a user may have full-control within their actual account, but could be restricted to read-only operations after switching context. You can provide multiple different roles for different accounts, but you must provide at least one role per account association:

Account associations can also be removed by clicking the X adjacent to each role list, or by removing the labels directly from the Associate Account(s) dropdown control.
Once you are satisfied with the user configuration, click OK to create (or update) these associations. The standard user will now be able to switch account data context using the same procedure as the one described for administrators, presented earlier in this document.
19.4 - Role-Based Access Control
Overview
Anchore Enterprise includes support for using Role-Based Access Control (RBAC) to control the permissions that a specific user has to a specific set of resources in the system. This allows administrators to configure specific, limited permissions on user enabling limited access usage for things like CI/CD automation accounts, read-only users for browsing analysis output, or security team users that can modify policy but not change image analysis configuration.
Anchore Enterprise provides a predefined of roles. Please see table below for complete list.
The Enterprise UI contains an enumeration of the specific permissions granted to users that are members of each of the roles.
Roles, Users, and Accounts
Roles are applied within the existing account and user frameworks defined in Anchore Enterprise. Resources are still scoped to the account namespace and accounts provide full resource isolation (e.g. an image must be analyzed within an account to be referenced in that account). Roles allow users to be granted permissions in both the account to which they belong as well as external accounts to facilitate resource-sharing.
Terminology
User: An authenticated identity (a principal in rbac-speak).
Account: A resource namespace and user grouping that also defines an authorization domain to which permissions are applied.
Role: A named set of permissions.
Permission: An action to grant an operation on a set of resources.
Action: The operation to be executed, such as listImages, createRegistry, and updateUser.
Target: The resource to be operated on, such as an image digest.
Role Membership: Mapping a username to a role within a specific account. This confers the permissions defined by the role to resources in the specified account to the specified user. The user is not required to be a member of the account itself.
Constraints
- A user may be a member of a role within one or more accounts.
- A user may be a member of many roles, or no roles.
- There is no default role set on a user when a user is created. Membership must be explicitly set.
- Roles are immutable. The set of actions they grant is static.
- Creating and deleting accounts is only available to users in the admin account. The scope of accounts and roles is different than other resources because they are global. The authorization domain for those resources is not the account name but rather the global domain: system.
Role Summary and Permissions
| Role | Allowed Actions | Description |
|---|
| system-admin | All actions within all domains. | Administrative control over all domains within the system. USE WITH EXTREME CAUTION |
| full-control | All actions within a specific account domain. | Full control over any account granted for. USE WITH EXTREME CAUTION |
| account-user-admin | listUsers, createUser, updateUser, deleteUser, listRoles, getRole, listRoleMembers, createRoleMember, deleteRoleMember, getAccount, listApiKeys, createApiKey, getApiKey, updateApiKey, deleteApiKey | Manage account creation and addition of users to accounts. |
| account-viewer | listAccounts | Role which can list all accounts on the system. This role is only available for use in the system domain. This role can only be conferred by a system administrator. |
| image-analyzer | listImages, getImage, createImage, getImageEvaluation, listEvents, getEvent, listSubscriptions, importImage, importSource, getSubscription, getAccount, listSources, getSource, importSource, getSourceEvaluation, listSubscriptions, updateSubscription, getSubscription, deleteSubscription, createSubscription, createArtifactRelationships, listArtifactRelationships, viewReports, listVulnAnnotations, getVulnAnnotation | Submit images for analysis, get results, but not change config. Intended for CI/CD systems and automation. |
| image-developer | listImages, getImage, listPolicies, getPolicy, listSubscriptions, getSubscription, listRegistries, getRegistry, getImageEvaluation, listEvents, getEvent, listArchives, listArchiveTransitionRules, getArchiveTransitionRule, listArchivedImageAnalysis, getArchivedImageAnalysis, getArchiveTransitionRuleHistory, getAccount, listNotificationEndpoints, listNotificationEndpointConfigurations, getNotificationEndpointConfiguration, getActions, listAlerts, getAlert, getCorrection, getApplication, listSources, getSource, getSourceEvaluation, listArtifactRelationships, listVulnAnnotations, getVulnAnnotation | Permissions view images, vulnerabilities and policy evaluations. |
| image-lifecycle | createArchivedImageAnalysis, createArchiveTransitionRule, deleteArchivedImageAnalysis, deleteArchiveTransitionRule, deleteArchiveTransitionRuleHistory, getArchivedImageAnalysis, getArchiveTransitionRule, getArchiveTransitionRuleHistory, listArchivedImageAnalysis, listArchives, listArchiveTransitionRules, | Permissions to manage archives and archival rules. |
| inventory-agent | syncInventory | Minimal permissions for use with runtime inventory agents (k8s or ECS). |
| read-write | createImage, createPolicy, createRegistry, createRepository, createSubscription, deleteEvents, deleteImage, deletePolicy, deleteRegistry, deleteSubscription, getAccount, getEvent, getImage, getImageEvaluation, getPolicy, getRegistry, getSubscription, importImage, importSource, listEvents, listImages, listPolicies, listRegistries, listSubscriptions, updatePolicy, updateRegistry, updateSubscription, listArchives, listArchiveTransitionRules, getArchiveTransitionRule, createArchiveTransitionRule, deleteArchiveTransitionRule, listArchivedImageAnalysis, getArchivedImageAnalysis, createArchivedImageAnalysis, deleteArchivedImageAnalysis, getArchiveTransitionRuleHistory, listNotificationEndpoints, listNotificationEndpointConfigurations, getNotificationEndpointConfiguration, createNotificationEndpointConfiguration, updateNotificationEndpointConfiguration, deleteNotificationEndpointConfiguration, listRuntimeInventories, getRuntimeInventory, createRuntimeInventory, syncInventory, deleteInventory, getActions, addAction, listAlerts, getAlert, createAlert, updateAlert, getCorrection, addCorrection, updateCorrection, deleteCorrection, createApplication, getApplication, deleteApplication, updateApplication, listSources, getSource, importSource, getSourceEvaluation, createArtifactRelationship, listArtifactRelationships, deleteArtifactRelationships, getArtifactRelationshipDiff, createScheduledQuery, updateScheduledQuery, executeScheduledQuery, deleteScheduledQuery, deleteScheduledQueryResult, viewReports, getKubernetesContainers, getKubernetesClusters, getKubernetesNamespaces, getKubernetesNodes, getKubernetesPods, getKubernetesVulnerabilities, listRuntimeInventories, getECSContainers, getECSServices, getECSTasks, listVulnAnnotations, getVulnAnnotation | Full read-write permissions for regular account-level resources, excluding user/role management. |
| read-only | listImages, getImage, listPolicies, getPolicy, listSubscriptions, getSubscription, listRegistries, getRegistry, getImageEvaluation, listEvents, getEvent, listArchives, listArchiveTransitionRules, getArchiveTransitionRule, listArchivedImageAnalysis, getArchivedImageAnalysis, getArchiveTransitionRuleHistory, getAccount, listNotificationEndpoints, listNotificationEndpointConfigurations, getNotificationEndpointConfiguration, listRuntimeInventories, getRuntimeInventory, getActions, listAlerts, getAlert, getCorrection, getApplication, listSources, getSource, getSourceEvaluation, listArtifactRelationships, viewReports, getKubernetesContainers, getKubernetesClusters, getKubernetesNamespaces, getKubernetesNodes, getKubernetesPods, getKubernetesVulnerabilities, listRuntimeInventories, getECSContainers, getECSServices, getECSTasks, listVulnAnnotations, getVulnAnnotation | Read only access to account resources, but includes policy evaluation permission. |
| policy-editor | listImages, listSubscriptions, listPolicies, getImage, getPolicy, getImageEvaluation, createPolicy, updatePolicy, deletePolicy, getAccount, getCorrection, listSources, getSource, getSourceEvaluation, viewReports, listVulnAnnotations, getVulnAnnotation | Edit policies, get evaluations of images, intended for users to set policies but not change the scanning configurations. |
| repo-analyzer | createRepository, updateSubscription (specifically for activation of type repo_update) | Permission to allow analysis of repositories. |
| report-admin | listImages, createScheduledQuery, updateScheduledQuery, executeScheduledQuery, deleteScheduledQuery, deleteScheduledQueryResult, viewReports, | Permissions to administer reports and schedules. |
| registry-editor | createRegistry, deleteRegistry, getRegistry, listRegistries, updateRegistry, | Permissions to manage registry credentials. |
| vuln-annotator-editor | listVulnAnnotations, getVulnAnnotation, createVulnAnnotation, updateVulnAnnotation, deleteVulnAnnotation | Role to create, update and delete vulnerability annotations |
Note: All account scoped roles have these roles implicitly granted as well: selfListApiKeys, selfCreateApiKey, selfUpdateApiKey, selfDeleteApiKey, selfGetApiKey, selfGetCredentials, selfAddCredential, selfDeleteCredential
Granting Cross-Account Access
The Anchore API supports a specific mechanism for allowing a user to make requests in another account’s namespace, the x-anchore-account header. By including x-anchore-account: "desiredaccount" on a request, a user can attempt that request in the namespace of the other account. This is subject to full authorization and RBAC.
To grant a username the ability to execute operations in another account, simply make the username a member of a role in the desired account. This can be accomplished in the UI or via API against the RBAC Manager service endpoint. For example, using curl:
curl -u admin:foobar -X POST -H "Content-Type: application/json" -d '{"username": "someuser", "for_account": "some_other_account"}' http://localhost:8229/roles/policy-editor/members
This should be done with caution as there is currently no support for resource-specific access controls. A user will have the permitted actions on all resources in the other account (based on the permissions of the role). For example, making a user a member of policy-editor role for another account will enable full ability to create, delete, and update that account’s policy bundles.
WARNING: Because roles do not currently provide custom target/resource definitions, assigning users to the Account User Admin role for an account other than their own is dangerous because there are no guards against that user then removing permissions of the granting user (unless that user is an ‘admin’ account user), so use with extreme caution.
NOTE: admin account users are not subject to RBAC constraints and therefore always have full access to add/remove users to roles in any account. So, while it is possible to grant them role membership, the result is a no-op and does not change the permissions of the user in any way.
19.4.1 - User Groups
Overview
User groups are abstractions that allow an administrator to manage permissions for users across the system without having to manage each individual user’s permissions.
Administrators simply have to create a user group, define roles per accounts within the user group and then associate users with it. Users can be associated with multiple user-groups. Each user inherits roles from their user group as well as any explicitly defined roles.
Users can be explicitly added to a User Group (as described above) or SAML users can have an indirect membership of a user group based on their IDP associations.
Note: User Group management is strictly limited to admin users only.
Terminology
- User Group: A basic resource that grants roles and permissions to users on various accounts
"name": "user-group-engineers",
"description": "The group permissions for all engineers",
- User Group Roles: A collection of roles associated with a user group, this can span multiple accounts and have multiple roles per account. E.g.
[
{Account: "devs_account", Roles: [“policy-editor”,”image-analyzer”]},
{Account: "devops_account", Roles: [“read-write”]},
{Account: "preview_account", Roles: [“read-only”]}
]
- IDP User Group Mappings: A set of User Groups that are mapped to a single Identity provider. E.g.
{
IDP Name: "keycloak",
User Groups: [“user-group-engineers”, ”user-group-devsec”, ”user-group-auditors”]}
- User Group Native User Member: A native user who has been explicitly associated with a User Group. This user inherits all roles from the User Group in addition to any roles assigned directly to this user.
- User Group IDP Member: An SAML user who is an indirect member of a User Group. As the SAML user authenticates, the IDP’s User Group Mappings are used to determine if this user should be associated with a User Group.
Native users
Native users are users that are defined in Anchore Enterprise and do not authenticate using an external SSO endpoint.
These users can be added to User Groups directly and inherit roles from the User Groups they are members of.
SAML(SSO) users
SAML users are users that authenticate using an external SAML IDP.
These users can be associated with User Groups based on their group memberships in the SAML IDP.
SAML users are automatically added to a User Group based on their group memberships in the SAML IDP and the IDP’s User Group associations.
User Group management
User Groups can be managed from the Anchore Enterprise UI or using the Anchore Enterprise API.
AnchoreCTL
User Groups can be managed using the anchorectl CLI tool. The following commands are available for User Group management:
- To create a new User Group, use the following command:
anchorectl usergroup add development --description "The development team"
✔ Added usergroup
Name: development
Description: The development team
Group Uuid: 4a5d8357-1fc3-44cf-8a1c-9882406df656
Created At: 2024-03-20T15:57:20.086665Z
Last Updated: 2024-03-20T15:57:20.086669Z
Account Roles:
Items:
- To list all User Group, use the following command:
anchorectl usergroup list
┌─────────────┬──────────────────────┬──────────────────────────────────────┐
│ NAME │ DESCRIPTION │ GROUP UUID │
├─────────────┼──────────────────────┼──────────────────────────────────────┤
│ development │ The development team │ 4a5d8357-1fc3-44cf-8a1c-9882406df656 │
└─────────────┴──────────────────────┴──────────────────────────────────────┘
- To edit the description of a User Group, use the following command:
anchorectl usergroup update development --description "New development team description"
✔ Update usergroup
Name: development
Description: New development team description
Group Uuid: 4a5d8357-1fc3-44cf-8a1c-9882406df656
Created At: 2024-03-20T15:57:20.086665Z
Last Updated: 2024-03-20T16:00:17.989822Z
Account Roles:
Items:
- To delete a User Group, use the following command:
anchorectl usergroup delete development
✔ Deleted usergroup
No results
- To add an account role to a User Group, use the following command:
anchorectl usergroup role add development dev_account --role image-analyzer,image-developer,read-only,repo-analyzer
✔ Added account and role(s)
┌────────────────┬───────────────────────────────────────────────────────────┐
│ ACCOUNT/DOMAIN │ ROLES │
├────────────────┼───────────────────────────────────────────────────────────┤
│ dev_account │ image-analyzer, image-developer, read-only, repo-analyzer │
└────────────────┴───────────────────────────────────────────────────────────┘
# anchorectl usergroup role add development devops_account --role read-only
✔ Added account and role(s)
┌────────────────┬───────────────────────────────────────────────────────────┐
│ ACCOUNT/DOMAIN │ ROLES │
├────────────────┼───────────────────────────────────────────────────────────┤
│ dev_account │ image-analyzer, image-developer, read-only, repo-analyzer │
│ devops_account │ read-only │
└────────────────┴───────────────────────────────────────────────────────────┘
- To list all account roles for a User Group, use the following command:
anchorectl usergroup role list development
✔ Fetched usergroups accounts and roles
┌────────────────┬───────────────────────────────────────────────────────────┐
│ ACCOUNT/DOMAIN │ ROLES │
├────────────────┼───────────────────────────────────────────────────────────┤
│ dev_account │ image-analyzer, image-developer, read-only, repo-analyzer │
│ devops_account │ read-only │
└────────────────┴───────────────────────────────────────────────────────────┘
- To remove account role(s) from a User Group, use the following command:
anchorectl usergroup role delete development dev_account --role image-analyzer,image-developer
✔ Deleted role
No results
- To add a native user to a User Group, use the following command:
anchorectl usergroup user add development -u dev_user
✔ Added user(s)
┌──────────┬─────────────────────────────┐
│ USERNAME │ ADDED TO USER GROUP ON │
├──────────┼─────────────────────────────┤
│ dev_user │ 2024-03-20T16:30:20.092909Z │
└──────────┴─────────────────────────────┘
- To list all members of a User Group, use the following command:
anchorectl usergroup user list development
✔ Fetched users within usergroup
┌──────────┬─────────────────────────────┐
│ USERNAME │ ADDED TO USER GROUP ON │
├──────────┼─────────────────────────────┤
│ dev_user │ 2024-03-20T16:30:20.092909Z │
└──────────┴─────────────────────────────┘
- To remove a native user from a User Group, use the following command:
anchorectl usergroup user delete development -u dev_user
✔ Deleted user(s)
No results