After you have installed Anchore Enterprise, there are various ways to monitor its operations:
1 - System Health
Overview
Added in Anchore Enterprise 2.2, the Health section within the System tab is an administrator’s new display for investigating the operational status of their system’s various services and feeds. Leverage this view to understand when your system is ready or if it requires intervention.
The following sections in this document describe how to determine system readiness, the state of your services, and the progression of your feed sync.
For more information on the overall architecture of a full Anchore Enterprise deployment, please refer to the Architecture documentation. Or refer to the Feeds Overview if you’re interested in the feeds-side of things.
System Readiness
Ready
(Tentatively) Ready
Not Ready
The indicator for system readiness can be seen from any screen by viewing the System tab header:
The system readiness status relies on the service and feed data which are routinely updated every 5 minutes. Using the example indicator provided above, once all the feed groups are successfully synced, the status icon will turn green.
For up-to-date information outside of the normal update cycle, navigate to the Health section within the System tab and click on Refresh Service Health, Refresh Feed Data, or manually refresh the page.
Services
As shown above and as of 2.2, there are five services required by the system to function (API, Catalog, Policy Engine, SimpleQueue, and Analyzer).
For every service, the Base URL, Host ID, and Version is displayed. As long as one instance of each service is up and available, the main system is regarded as ready. In the example image provided above, we see that we have multiple instances of the Policy Engine and Analyzer services.
For the full, filterable list of instances for that service, click on the numbers provided. In the case of the Policy Engine, that would be the 1/2 Available.
Note that orphaned services are filtered out by default in this view (with a toggle to include it again) but will still impact the availability count on the main page.
In the case of service errors, they are logged within the Events & Notifications tab so we recommend following up there for more information or browse our Troubleshooting documentation for remediation guidance.
Feeds Sync
Listed in this section are the various feed groups your system relies on for vulnerability and package data. This data comes from a variety of upstream sources which is vital for policy engine operations such as evaluating policies or listing vulnerabilities.
As shown, you can keep track of your sync progression using the Last Sync column. To manually update the feed data displayed outside of its normal 5-minute cycle, click the Refresh Feed Data button or refresh the page.
If you’d rather have them grouped by feed rather than listed out individually, you can toggle the layout from list to cards using the buttons in the top-right corner above the table:
Similar to the service cards, if you decide to have them grouped as we show below using the layout buttons, you can click on the number of groups synced to view the full, filterable list within.
When viewing a list of feed groups - whether through the default list or through a specific feed card - you can filter for a specific value using the input provided or click on the button attached to filter by category. In this case, groups can be filtered by whether they are synced or unsynced.
In the case of feed sync errors, they are logged within the Events & Notifications tab so we recommend following up there for more information or browse our Troubleshooting documentation for remediation guidance.
Or if you’re interested in an overview of the various drivers Enterprise Feeds uses, check out our Feeds Overview.
2 - Prometheus
Anchore Enterprise exposes prometheus metrics in the API of each service if the
config.yaml that is used by that service has the metrics.enabled key set to
true.
Each service exports its own metrics and is typically scraped by a Prometheus installation to gather the metrics. Anchore does not aggregate or distribute metrics between services. You should configure your Prometheus deployment or integration to check each Anchore service’s API using the same port it exports for the /metrics route.
Monitoring in Kubernetes and/or Helm Chart
Prometheus is very commonly used for monitoring Kubernetes clusters. Prometheus is supported by core Kubernetes services. There are many guides on using Prometheus to monitor a cluster and services deployed within, and also many other monitoring systems can consume Prometheus metrics.
The Anchore Helm Chart includes a quick way to enable the Prometheus metrics on each service container:
Set:
helm install --name myanchore anchore/anchore-engine --set anchoreGlobal.enableMetrics=trueOr, set it directly in your customized values.yaml
The specific strategy for monitoring services with prometheus is outside the scope of this document. But, because Anchore exposes metrics on the /metrics route of all service ports, it should be compatible with most monitoring approaches (daemon sets, side-cars, etc).
Metrics of Note
Anchore services export a range of metrics. The following list shows some Anchore services that can help you determine the health and load of an Anchore deployment.
- anchore_queue_length, specifically for queuename: “images_to_analyze”
- This is the number of images pending analysis, in the not_analyzed state.
- As this number grows you can expect longer analysis times.
- Adding more analyzers to a system can help drain the queue faster and keep wait times to a minimum.
- Example: anchore_queue_length{instance=“engine-simpleq:8228”,job=“anchore-simplequeue”,queuename=“images_to_analyze”}.
- This metric is exported from all simplequeue service instances, but is based on the database state, so they should all present a consistent view of the length of the queue.
- anchore_monitor_runtime_seconds_count
- These metrics, one for each monitor, record the duration of the async processes as they execute on a duty cycle.
- As the system grows, these will become longer to account for more tags to check for updates, repos to scan for new tags, and user notifications to process.
- anchore_tmpspace_available_bytes
- This metric tracks the available space in the “tmp_dir” location for each container. This is most important for the instances that are analyzers where this can indicate how much disk is being used for analysis and how much overhead there is for analyzing large images.
- This is expected to be consumed in cycles, with usage growing during analysis and then flushing upon completion. A consistent growth pattern here may indicate left over artifacts from analysis failures or a large layer_cache setting that is not yet full. The layer cache (see Layer Caching) is located in this space and thus will affect the metric.
- process_resident_memory_bytes
- This is the memory actually consumed by the instance, where each instance is a service process of Anchore. Anchore is fairly memory intensive for large images and in deployments with lots of analyzed images due to lots of json parsing and marshalling, so monitoring this metric will help inform capacity requirements for different components based on your specific workloads. Lots of variables affect memory usage, so while we give recommendations in the Capacity Planning document, there is no substitute for profiling and monitoring your usage carefully.
3 - Event Log
Introduction
The event log subsystem provides the users with a mechanism to inspect asynchronous events occurring across various Anchore Enterprise services. Anchore events include periodically triggered activities such as vulnerability data feed syncs in the policy-engine service, image analysis failures originating from the analyzer service, and other informational or system fault events. The catalog service may also generate events for any repositories or image tags that are being watched, when the engine encounters connectivity, authentication, authorization or other errors in the process of checking for updates. The event log is aimed at troubleshooting most common failure scenarios (especially those that happen during asynchronous engine operations) and to pinpoint the reasons for failures, that can be used subsequently to help with corrective actions. Events can be cleared from anchore-engine in bulk or individually.
The Anchore events (drawn from the event log) can be accessed through the Anchore Enterprise API and AnchoreCTL, or can be emitted as webhooks if your Anchore Enterprise is configured to send webhook notifications. For API usage refer to the document on using the Anchore Enterprise API.
Accessing Events
The anchorectl command can be used to list events and filter through the results, get the details for a specific event and delete events matching certain criteria.
# anchorectl event --help
Event related operations
Usage:
event [command]
Available Commands:
delete Delete an event by its ID or set of filters
get Lookup an event by its event ID
list Returns a paginated list of events in the descending order of their occurrence
Flags:
-h, --help help for event
Use " event [command] --help" for more information about a command.
For help regarding global flags, run --help on the root command
For a list of the most recent events:
anchorectl event list
✔ List events
┌──────────────────────────────────┬──────────────────────────────────────────────┬───────┬─────────────────────────────────────────────────────────────────────────┬─────────────────┬────────────────┬────────────────────┬─────────────────────────────┐
│ UUID │ EVENT TYPE │ LEVEL │ RESOURCE ID │ RESOURCE TYPE │ SOURCE SERVICE │ SOURCE HOST │ TIMESTAMP │
├──────────────────────────────────┼──────────────────────────────────────────────┼───────┼─────────────────────────────────────────────────────────────────────────┼─────────────────┼────────────────┼────────────────────┼─────────────────────────────┤
│ 8c179a3b27a543fe9285cf4feb65561d │ system.image_analysis.registry_lookup_failed │ error │ docker.io/alpine:3.4 │ image_reference │ catalog │ anchore-quickstart │ 2022-08-24T23:08:30.54001Z │
│ 48c18a84575d45efbf5b41e0f3a87177 │ system.image_analysis.registry_lookup_failed │ error │ docker.io/alpine:latest │ image_reference │ catalog │ anchore-quickstart │ 2022-08-24T23:08:30.510193Z │
│ f6084efd159c43a1a0518b6df5e58505 │ system.image_analysis.registry_lookup_failed │ error │ docker.io/alpine:3.12 │ image_reference │ catalog │ anchore-quickstart │ 2022-08-24T23:08:30.480625Z │
│ 4464b8f83df046388152067122c03610 │ system.image_analysis.registry_lookup_failed │ error │ docker.io/alpine:3.8 │ image_reference │ catalog │ anchore-quickstart │ 2022-08-24T23:08:30.450983Z │
...
│ 60f14821ff1d407199bc0bde62f537df │ system.image_analysis.restored_from_archive │ info │ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ image_digest │ catalog │ anchore-quickstart │ 2022-08-24T22:53:12.662535Z │
│ cd749a99dca8493889391ae549d1bbc7 │ system.analysis_archive.image_archived │ info │ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ image_digest │ catalog │ anchore-quickstart │ 2022-08-24T22:48:45.719941Z │
...
└──────────────────────────────────┴──────────────────────────────────────────────┴───────┴─────────────────────────────────────────────────────────────────────────┴─────────────────┴────────────────┴────────────────────┴─────────────────────────────┘
Note: Events are ordered by the timestamp of their occurrence, the most recent events are at the top of the list and the least recent events at the bottom.
There are a number of ways to filter the event list output (see anchorectl event list --help for filter options):
For troubleshooting events related to a specific event type:
# anchorectl event list --event-type system.analysis_archive.image_archive_failed
✔ List events
┌──────────────────────────────────┬──────────────────────────────────────────────┬───────┬──────────────┬───────────────┬────────────────┬────────────────────┬────────────────────────────┐
│ UUID │ EVENT TYPE │ LEVEL │ RESOURCE ID │ RESOURCE TYPE │ SOURCE SERVICE │ SOURCE HOST │ TIMESTAMP │
├──────────────────────────────────┼──────────────────────────────────────────────┼───────┼──────────────┼───────────────┼────────────────┼────────────────────┼────────────────────────────┤
│ 35114639be6c43a6b79d1e0fef71338a │ system.analysis_archive.image_archive_failed │ error │ nginx:latest │ image_digest │ catalog │ anchore-quickstart │ 2022-08-24T22:48:23.18113Z │
└──────────────────────────────────┴──────────────────────────────────────────────┴───────┴──────────────┴───────────────┴────────────────┴────────────────────┴────────────────────────────┘
To filter events by level such as ERROR or INFO:
anchorectl event list --level info
✔ List events
┌──────────────────────────────────┬─────────────────────────────────────────────┬───────┬─────────────────────────────────────────────────────────────────────────┬───────────────┬────────────────┬────────────────────┬─────────────────────────────┐
│ UUID │ EVENT TYPE │ LEVEL │ RESOURCE ID │ RESOURCE TYPE │ SOURCE SERVICE │ SOURCE HOST │ TIMESTAMP │
├──────────────────────────────────┼─────────────────────────────────────────────┼───────┼─────────────────────────────────────────────────────────────────────────┼───────────────┼────────────────┼────────────────────┼─────────────────────────────┤
│ 60f14821ff1d407199bc0bde62f537df │ system.image_analysis.restored_from_archive │ info │ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ image_digest │ catalog │ anchore-quickstart │ 2022-08-24T22:53:12.662535Z │
│ cd749a99dca8493889391ae549d1bbc7 │ system.analysis_archive.image_archived │ info │ sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc │ image_digest │ catalog │ anchore-quickstart │ 2022-08-24T22:48:45.719941Z │
...
Note: Event listing response is paginated, anchorectl displays the first 100 events matching the filters. For all the results use the –all flag.
All available options for listing events:
# anchorectl event list --help
Returns a paginated list of events in the descending order of their occurrence. Optional query parameters may be used for filtering results
Usage:
event list [flags]
Flags:
--all return all events (env: ANCHORECTL_EVENT_ALL)
--before string return events that occurred before the ISO8601 formatted UTC timestamp
(env: ANCHORECTL_EVENT_BEFORE)
--event-type string filter events by a prefix match on the event type (e.g. "user.image.")
(env: ANCHORECTL_EVENT_TYPE)
-h, --help help for list
--host string filter events by the originating host ID (env: ANCHORECTL_EVENT_SOURCE_HOST_ID)
--level string filter events by the level - INFO or ERROR (env: ANCHORECTL_EVENT_LEVEL)
-o, --output string the format to show the results (allowable: [text json json-raw id]; env: ANCHORECTL_FORMAT) (default "text")
--page int32 return the nth page of results starting from 1. Defaults to first page if left empty
(env: ANCHORECTL_PAGE)
--resource-type string filter events by the type of resource - tag, imageDigest, repository etc
(env: ANCHORECTL_EVENT_RESOURCE_TYPE)
--service string filter events by the originating service (env: ANCHORECTL_EVENT_SOURCE_SERVICE_NAME)
--since string return events that occurred after the ISO8601 formatted UTC timestamp
(env: ANCHORECTL_EVENT_SINCE)
For help regarding global flags, run --help on the root command
Event listing displays a brief summary of the event, to get more detailed information about the event such as the host where the event has occurred or the underlying the error:
# anchorectl event get c31eb023c67a4c9e95278473a026970c
✔ Fetched event
UUID: c31eb023c67a4c9e95278473a026970c
Event:
Event Type: system.image_analysis.registry_lookup_failed
Level: error
Message: Referenced image not found in registry
Resource:
Resource ID: docker.io/aerospike:latest
Resource Type: image_reference
User Id: admin
Source:
Source Service: catalog
Base Url: http://catalog:8228
Source Host: anchore-quickstart
Request Id:
Timestamp: 2022-08-24T22:08:28.811441Z
Category:
Details: cannot fetch image digest/manifest from registry
Created At: 2022-08-24T22:08:28.812749Z
Clearing Events
Events can be cleared/deleted from the system in bulk or individually. Bulk deletion allows for specifying filters to clear the events within a certain time window. To delete all events from the system:
# anchorectl event delete --all
Use the arrow keys to navigate: ↓ ↑ → ←
? Are you sure you want to delete all events:
▸ Yes
No
⠙ Deleting event
c31eb023c67a4c9e95278473a026970c
329ff24aa77549458e2656f1a6f4c98f
649ba60033284b87b6e3e7ab8de51e48
4010f105cf264be6839c7e8ca1a0c46e
...
Delete events before a specified timestamp (can also use --since instead of --before to delete events that were generated after a specified timestamp):
# anchorectl event delete --before 2022-08-24T22:08:28.629543Z
✔ Deleted event
ce26f1fa1baf4adf803d35c86d7040b7
081394b6e62f4708a10e521a960c54d7
d21b587dea5844cc9c330ba2b3d02d2e
7784457e6bf84427a175658f134f3d6a
...
Delete a specific event:
# anchorectl event delete fa110d517d2e43faa8d8e2dfbb0596af
✔ Deleted event
fa110d517d2e43faa8d8e2dfbb0596af
Sending Events as Webhook Notifications
In addition to access via API and AnchoreCTL, the Anchore Enterprise may be configured to send notifications for events as they are generated in the system via its webhook subsystem. Webhook notifications for event log records is turned off by default. To turn enable the ’event_update’ webhook, uncomment the ’event_log’ section under ‘services->catalog’ in config.yaml, as in the following example:
services:
...
catalog:
...
event_log:
notification:
enabled: True
# (optional) notify events that match these levels. If this section is commented, notifications for all events are sent
level:
- error
Note: In order for events to be sent via webhook notifications, you’ll need to ensure that the webhook subsystem is configured in config.yaml (if it isn’t already) - refer to the document on subscriptions and notifications for information on how to enable webhooks in Anchore Enterprise. Event notifications will be sent to ’event_update’ webhook endpoint if it is defined, and the ‘general’ webhook endpoint otherwise.
Events via the UI
The Events tab is your gateway to current and historical activity happening in your system. View various events such as policy evaluation and vulnerability updates, system errors, feed syncs, and more.
The following sections in this document describe how to view event details, how to filter for specific events you’re interested in, and how to manage events with bulk deletion.
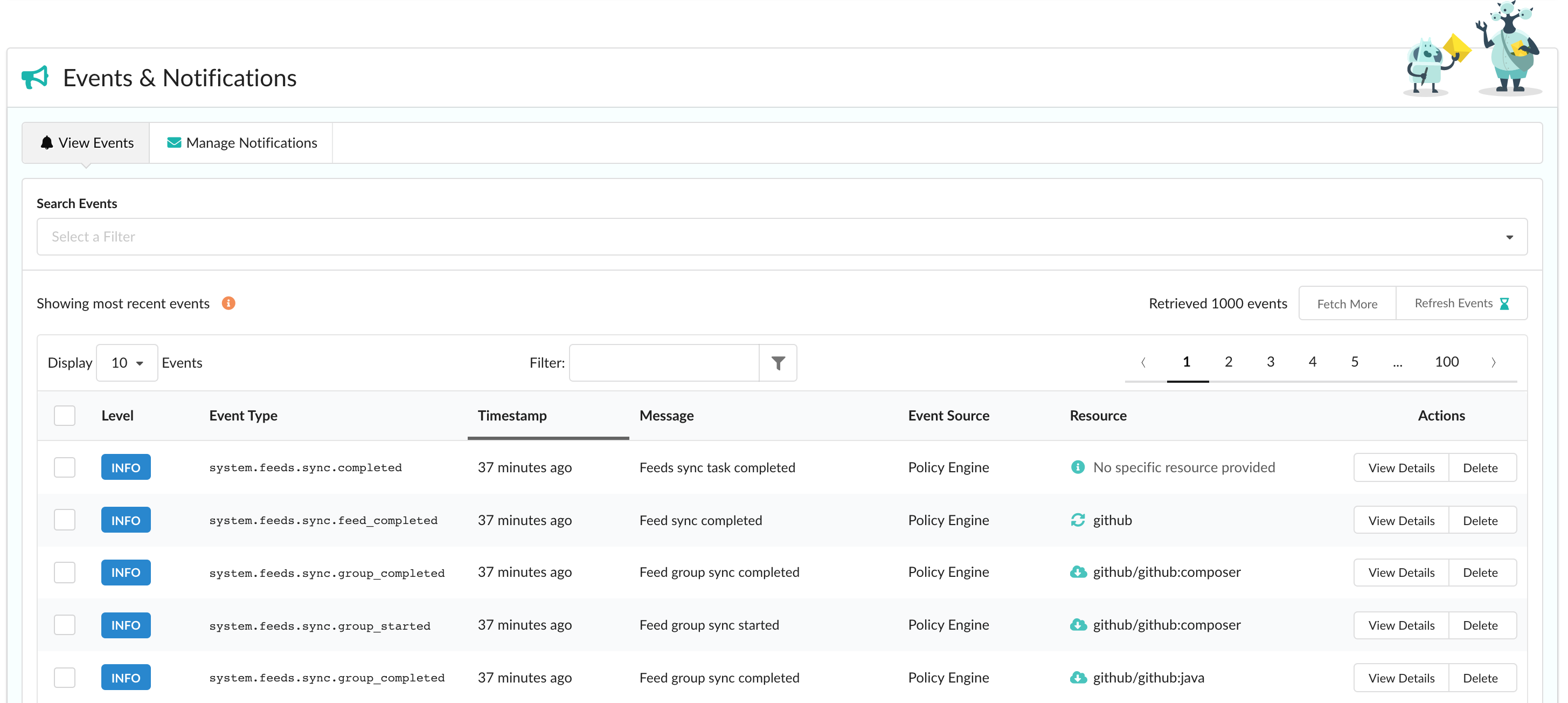
Viewing Events
In order to view events, navigate to the Events & Notifications > View Events tab. By default, the most recent activity (up to 1000 events) is shown and is automatically updated for you every 5 minutes. Note that if you have applied any filters through the search bar, your results will need to be refreshed manually.
Top-level details such as the event’s level (whether it’s an INFO or ERROR event), type, message, and affected resource is shown. Dig in to a specific event by clicking View Details under its Actions column to expand the row.

Additional information such as the origininating service and host ID are available in the expanded row. Any details given by the service are also provided in JSON format to view or copy to clipboard.
Filtering Events
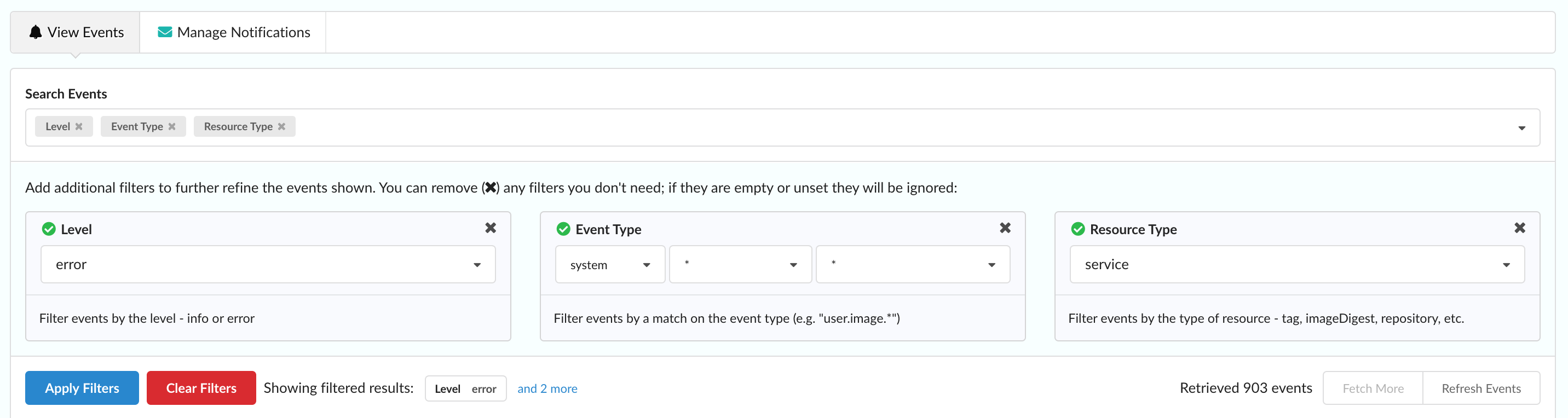
Often, you might want to search for a specific event type or events that happened after a certain time. In this case, use the Search Events bar near the top of the page to select a filter to search on. These include:
- Level
- Filter events by level - INFO or ERROR
- Event Type
- Filter events by a match on the event type (e.g. “user.image.*”)
- Since
- Return events that occurred after the timestamp
- Before
- Return events that occurred before the timestamp
- Source Servicename
- Filter events by the originating service
- Source Host ID
- Filter events by the originating host ID
- Resource Type
- Filter events by the type of resource - tag, imageDigest, repository, etc.
- Resource ID
- Filter events by the id of the resource
Once you have selected and populated the filter fields you’re interested in, click Apply Filters to search and show those filtered results.
An alternative way to filter your results is through the in-table filter input. Note that this only applies against any data already fetched. To increase what you’re filtering on, click Fetch More near the top-right of the table for up to an additional 1000 items.
To remove any filters and reset to the default view, click Clear Filters.
Deleting Events
To assist with event management, event deletion has been added in the Enterprise 2.3 release.
Deleting individual events can be done simply through clicking Delete under the Actions column and selecting Yes to confirm. Note that after deletion, events are not recoverable.
Multi-select is available for deleting multiple events at a time. Upon selecting an event using the checkbox in the far-left column, a toolbar-like component will slide in at the bottom of the table. The number of events selected is shown along with the selection type, Clear Selection, and Delete Events options.
Checking the box in the header will select all events within that page.
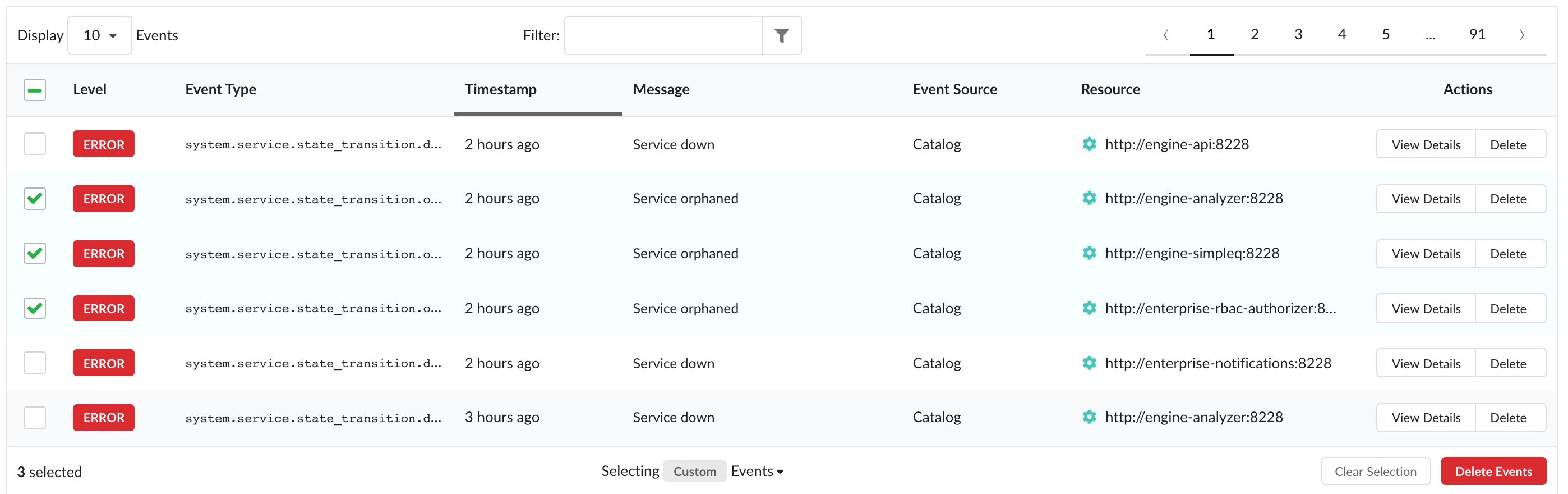
By default, it is viewed as a Custom selection. Choosing to select All Retrieved events auto-selects everything already fetched and present in the table (i.e. if a filter is applied, events not matching the filter are not selected but will be upon removal of the filter). In this state, deselecting an item will trigger a custom selection again.
Selecting All events will again auto-select all events already fetched and present in the table but while applying a filter may modify what’s viewable, this option is solely for clearing the entire backlog of events - including those not shown. In this state, deselecting an item will also trigger a custom selection.
Once you have selected the events you wish to remove, click Delete Events to open a modal and review up to 50 items. Any events you don’t wish to delete anymore can be deselected as well. To continue with removal, click Yes to confirm and start the process.
Note that events are account-wide and that any events removed will be mirrored across all users in the account.