Overview of Anchore Enterprise
What is Anchore Enterprise?
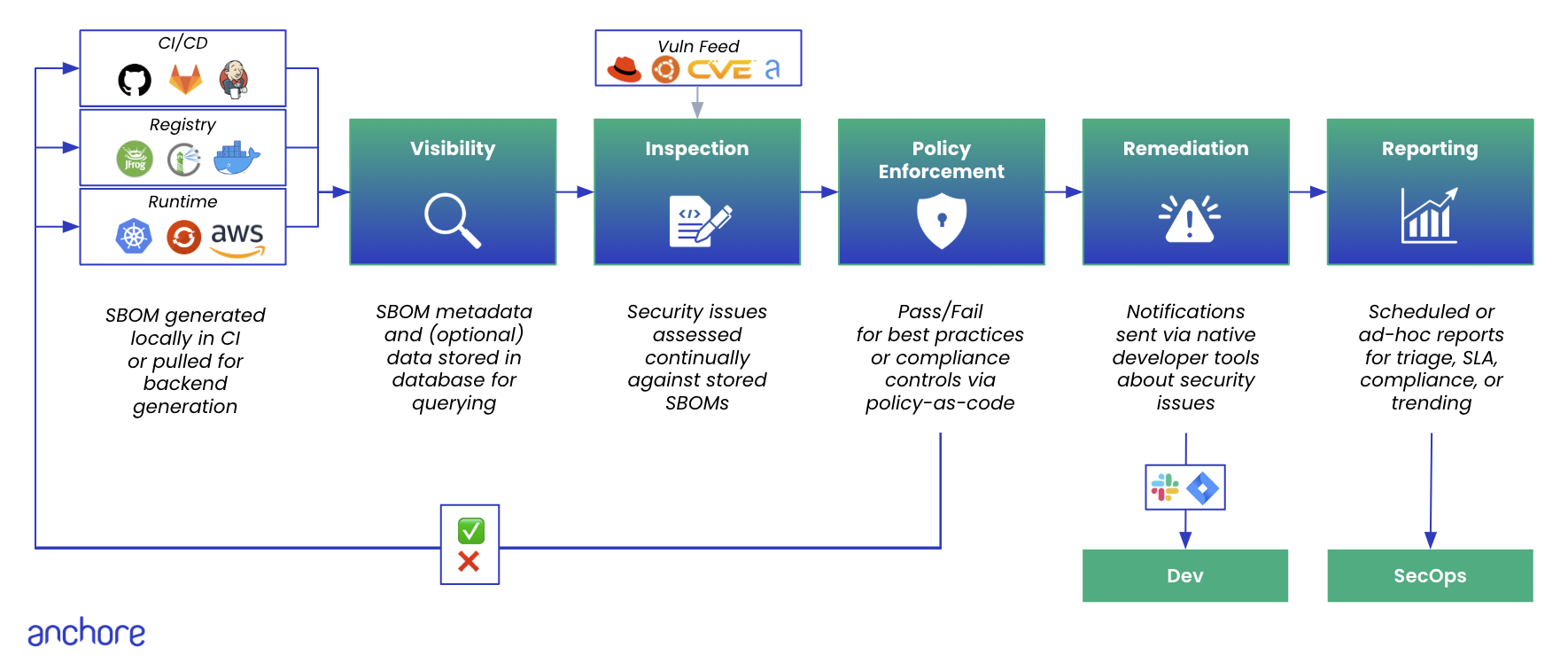
Anchore Enterprise is a software bill of materials (SBOM) - powered software supply chain management solution designed for a cloud-native world. It provides continuous visibility into supply chain security risks. Anchore Enterprise takes a developer-friendly approach that minimizes friction by embedding automation into development toolchains to generate SBOMs and accurately identify vulnerabilities, malware, misconfigurations, and secrets for faster remediation.
Gaining Visibility with SBOMs
Anchore Enterprise generates detailed SBOMs at each step in the development process, providing a complete inventory of the software components including the direct and transitive dependencies you use. Anchore Enterprise stores all SBOMs in a SBOM repository to enable ongoing monitoring of your software for new or zero-day vulnerabilities that can arise even post-deployment.
Anchore Enterprise also detects SBOM drift in the build process, issuing an alert for changes in SBOMs so they can be assessed for risk, malware, compromised software, and malicious activity.
Identifying Vulnerability and Security Issues
Starting with the SBOM, Anchore Enterprise uses multiple vulnerability feeds along with a precision vulnerability matching algorithm to pinpoint relevant vulnerabilities and minimize false positives. Anchore Enterprise also identifies malware, cryptominers, secrets, misconfigurations, and other security issues.
Automating through Policies
Anchore Enterprise includes a powerful policy engine that enables you to define guardrails and automate compliance with industry standards or internal rules. Using Anchore’s customizable policies, you can automatically identify the security issues that you care about and alert developers or create policy gates for critical issues.
1 - Anchore Enterprise Capabilities
SBOM Generation and Management
A software bill of materials (SBOM), is the foundational element that powers Anchore Enterprise’s secure management of the software supply chain. Anchore Enterprise automatically generates and analyzes comprehensive SBOMs at each step of the development lifecycle. SBOMS are stored in a repository to provide visibility into software components and dependencies as well as continuous monitoring for new vulnerabilities and risks throughout the development process and post-deployment.
See SBOM Generation and Management for more information.
About Anchore Enterprise SBOMs
An SBOM is a list of software components and relevant metadata that includes packages, code-snippets, licenses, configurations, and other elements of an application.
Anchore Enterprise generates high-fidelity SBOMs by scanning container images and source code repositories. Anchore’s native SBOM format includes a rich set of metadata that is a superset of data included in SBOM standards such as SPDX and CycloneDX. Using this additional level of metadata, Anchore can identify secrets, file permissions, misconfiguration, malware, insecure practices, and more.
Anchore Enterprise SBOMs identify:
- Open source dependencies including ecosystem type (OS, language, and other metadata)
- Nested dependencies in archive files (WAR files, JAR files and more)
- Package details such as name, version, creator, and license information
- Filesystem metadata such as the file name, size, permissions, creation time, modification time, and hashes
- Malware
- Secrets, keys, and credentials
Anchore Enterprise supported ecosystems
Anchore Enterprise supports the following packaging ecosystems when identifying SBOM content. The Operating System category captures Linux packaging ecosystems. The Binary detector will inspect content to identify binaries that were installed outside of packaging ecosystems.
- Operating System
- RPM
- DEB
- APK
- Linux kernel archives (vmlinz)
- Linux kernel modules (ko)
- Languages
- C (conan)
- C++ (conan)
- Dart (pubs)
- Dotnet (deps.json)
- Objective-C (cocoapods)
- Elixir (mix)
- Erlang (rebar3)
- Go (go.mod, Go binaries)
- Haskell (cabal, stack)
- Java (jar, ear, war, par, sar, nar, native-image)
- JavaScript (npm, yarn)
- Jenkins Plugins (jpi, hpi)
- Nix (outputs in /nix/store)
- PHP (composer)
- Python (wheel, egg, poetry, requirements.txt)
- Ruby (gem)
- Rust (cargo.lock)
- Swift (cocoapods, swift-package-manager)
- Binaries
- Apache httpd
- BusyBox
- Consul
- Golang
- HAProxy
- Helm
- Java
- Memcached
- Nodejs
- PHP
- Perl
- PostgreSQL
- Python
- Redis
- Rust
- Traefik
How Anchore Enterprise Uses SBOMs
Anchore Enterprise generates detailed SBOMs at each stage of the software development lifecycle and stores them in a centralized repository to provide visibility into components and open source dependencies. These SBOMs are analyzed for vulnerabilities, malware, secrets (embedded passwords and credentials), misconfigurations, and other risks. Because SBOMs are stored in a repository, users can then continually monitor SBOMs for new vulnerabilities that arise, even post-deployment.
Detect SBOM Drift
Anchore Enterprise detects SBOM drift in the build process, identifying changes in SBOMs so they can be assessed for new risks or malicious activity. Users can set policy rules that alert them when components are added, changed, or removed so that they can quickly identify new vulnerabilities, developer errors, or malicious efforts to infiltrate builds. See SBOM Drift for more information.
Meet Compliance Requirements
Using the Anchore Enterprise UI or API, users can review SBOMs, generate reports, and export SBOMs as a JSON file. Anchore Enterprise can also export aggregated SBOMs for entire applications that can then be shared externally to meet customer and federal compliance requirements.
Customized Policy Rules
Anchore Enterprise’s high-fidelity SBOMs provide users with a rich set of metadata that can be used in customized policies.
Reduce False Positives
The extensive information provided in SBOMs generated by Anchore Enterprise allows for more accurate vulnerability matching for higher accuracy and reduced false positives.
Vulnerability and Security Scanning
Vulnerability and security scanning is an essential part of any vulnerability management strategy. Anchore Enterprise enables you to scan for vulnerabilities and security risks at any stage of your software development process, including source code repositories, CI/CD pipelines, container registries, and container runtime environments. By scanning at each stage in the process, you will find vulnerabilities and other security risks earlier and avoid delaying software delivery.
Continuous Scanning and Analysis
Anchore Enterprise provides continuous and automated scanning of an application’s code base, including related artifacts such as containers and code repositories. Anchore Enterprise starts the scanning process by generating and storing a high-fidelity SBOM that identifies all of the open source and proprietary components and their direct and transitive dependencies. Anchore uses this detailed SBOM to accurately identify vulnerabilities and security risks.
Identifying Zero-Day Vulnerabilities
When a zero-day vulnerability arises, Anchore Enterprise can instantly identify which components and applications are impacted by simply re-analyzing your stored SBOMs. You don’t need to re-scan applications or components.
Multiple Vulnerability Feeds
Anchore Enterprise uses a broad set of vulnerability data sources, including the National Vulnerability Database, GitHub Security Advisories, feeds for popular Linux distros and packages, and an Anchore-curated dataset for suppression of known false-positive vulnerability matches. See Data Feeds Overview for more information.
Precision Vulnerability Matching
Anchore Enterprise applies a best-in-class precision matching algorithm to select vulnerability data from the most accurate feed source. For example, when Anchore’s detailed SBOM data identifies that there is a specific Linux distro, such as RHEL, Anchore Enterprise will automatically use that vendor’s feed source instead of reporting every Linux vulnerability. Anchore’s precision vulnerability matching algorithm reduces false positives and false negatives, saving developer time. See the Managing False Positives section within this topic for additional ways that Anchore Enterprise reduces false positives.
Focusing solely on identifying vulnerability and security issues without remediation is not good enough for today’s modern DevSecOps teams. Anchore Enterprise combines the power of a rich set of SBOM metadata, reporting, and policy management capabilities to enable customers to remediate issues with the flexibility and granularity needed to mitigate disruption or slow down software production.
Managing False Positives
Anchore Enterprise provides a number of innovative capabilities to help reduce the number of false positives and optimize the signal-to-noise ratio. It starts with accurate component identification through Anchore’s high-fidelity SBOMs and a precision vulnerability matching algorithm for fewer false positives. In addition, allowlists and temporary allowlists provide for exceptions, reducing ongoing alerts. Lastly, Anchore Enterprise enables users to correct the false positives to avoid being raised in subsequent scans. “Corrections” help increase results in accuracy over time and lower signal-to-noise ratio.
Flexible Policy Enforcement
Anchore Enterprise enables users to define automated rules that indicate which vulnerabilities violate their organizations’ policies. For example, an organization may raise policy violations for vulnerabilities scored as Critical or High that have a fix available. These policy violations can generate alerts and notifications or be used to stop builds in the CI/CD pipeline or prevent code from moving to production. Policy enforcement can be applied at any stage in the development process, from the selection and usage of open source components through the build, staging, and deployment process. See Policy for more information.
Anchore Enterprise provides capabilities to automatically alert developers of issues through their existing tools, such as Jira or Slack. It also lets users define actionable remediation workflows with automated remediation recommendations.
Open Source Security, Dependencies, and Licenses
Anchore Enterprise gives users the ability to identify and track open source dependencies that are incorporated at any stage in the software lifecycle. Anchore Enterprise scans source code repositories, CI/CD pipelines, and container registries to generate SBOMs that include both direct and transitive dependencies and to identify exactly where those dependencies are found.
Anchore Enterprise also identifies the relevant open source licenses and enables users to ensure that the open source components used along with their dependencies are compliant with all license requirements. License policies are customizable and can be tailored to fit each organization’s open source requirements.
Compliance with Standards
Anchore Enterprise provides a flexible policy engine that enables you to identify and alert on the most important vulnerabilities and security issues, and to meet internal or external compliance requirements. You can leverage out-of-the-box policy packs for common compliance standards, or create custom policies for your organization’s needs. You can define rules against the most complete set of metadata and apply policies at the most granular level with different rules for different applications, teams, and pipelines.
Anchore offers out-of-the-box policy packs to help you comply with NIST and CIS standards that are foundational for such industry-specific standards as HIPAA and PCI DSS.
Flexible Policy Enforcement
Policies are flexible and provide both notifications and gates to prevent code from moving along the development pipeline or into production based on your criteria. You can define policy rules for image and file metadata, file contents, licenses, and vulnerability scoring. And you can define unique rules for each team, for each application, and for each pipeline.
Automated Rules
Anchore Enterprise enables users to define automated rules that indicate which vulnerabilities
violate their organization’s policies. For example, an organization may raise policy violations for vulnerabilities scored as Critical or High that have a fix available. These policy violations can generate alerts and notifications or be used to stop builds in the CI/CD pipeline or prevent code from moving to production. You can apply policy enforcement at any stage in the development process from the selection and usage of open source components through the build, staging, and deployment process.
Anchore Enterprise Policy Packs
Anchore Enterprise provides the following out-of-the-box policy bundles that automate checks for common compliance programs, standards, and laws including CIS, NIST, FedRAMP, CISA vulnerabilities, , and more. Policy Packs comprise bundled policies and are flexible so that you can modify them to meet your organization’s requirements.
FedRAMP
The FedRAMP Policy validates whether container images scanned by Anchore Enterprise are compliant with the FedRAMP Vulnerability Scanning Requirements and also validates them against FedRAMP controls specified in NIST 800-53 Rev 5 and NIST 800-190.
DISA Image Creation and Deployment Guide
The DISA Image Creation and Deployment Guide Policy provides security and compliance checks that align with specific NIST 800-53 and NIST 800-190 security controls and requirements as described in the Department of Defense (DoD) Container Image Creation and Deployment Guide.
DoD Iron Bank
The DoD Iron Bank Policy validates images against DoD security and compliance requirements in alignment with U.S. Air Force security standards at Platform One and Iron Bank.
CIS
The CIS Policy validates a subset of security and compliance checks against container image best practices and NIST 800-53 and NIST 800-190 security controls and requirements. To expand CIS security controls, you can customize the policies in accordance with CIS Benchmarks.
NIST
The NIST policy validates content against NIST 800-53 and NIST 800-190.
2 - Anchore Enterprise Architecture
Anchore Enterprise is a distributed application that runs on supported container runtime platforms. The product is deployed as a series of containers that provide services whose functions are made available through APIs. These APIs can be consumed directly via included clients such as the AnchoreCTL and GUI or via out-of-the-box integrations for use with container registries, Kubernetes, and CI/CD tooling. Alternatively, users can interact directly with the APIs for custom integrations.
Services
The following sections describe the services within Anchore Enterprise.

APIs
Enterprise Public API
The Enterprise API is the primary RESTful API for Anchore Enterprise and is the one used by AnchoreCTL, the GUI and integrations. This API is used to upload data such as a software bill of materials (SBOM) and container images, execute functions and retrieve information (SBOM data, vulnerabilities and the results of policy evaluations). The API also exposes the user and account management functions. See Using the Anchore API for more information.
Stateful Services
Data Syncer
The Anchore Enterprise Data Syncer downloads and normalizes data from external sources and makes it available to the Anchore Enterprise. It communicates with the hosted Anchore Data Service to fetch the following datasets:
- vulnerability_db: Contains vulnerability data from the NVD, Red Hat, and other sources.
- vulnerability_annotations: Contains vulnerability annotations from CISA KEV (Known Exploited Vulnerabilities) that are used to provide additional context to vulnerabilities.
- malware_signatures: Contains malware signatures from ClamAV that are used to detect malware in images.
- epss_db: Contains exploit prediction scores and percentiles for vulnerabilities.
Policy Engine
The policy engine is responsible for loading an SBOM and associated content and then evaluating it against a set of policy rules. This resulting policy evaluation is then passed to the Catalog service. The policies are stored as a series of JSON documents that can be uploaded and downloaded via the Enterprise API or edited via the GUI.
Catalog
The catalog is the primary state manager of the system and provides data access to system services from the backend database service (PostgreSQL).
SimpleQueue
The SimpleQueue is another PostgreSQL-backed queue service that the other components use for task execution, notifications, and other asynchronous operations.
Workers
Analyzers
An Analyzer is the component that generates an SBOM from an artifact or source repo (which may be passed through the API or pulled from a registry), performs the vulnerability and policy analysis, and stores the SBOM and the results of the analysis in the organization’s Anchore Enterprise repository. Alternatively the AnchoreCTL client can be used to locally scan and generate the SBOM and then pass the SBOM to the analyzers via the API. Each Analyzer can process one container image or source repo at a time. You can increase the number of Analyzers (within the limits of your contract) to increase the throughput for the system in order to process multiple artifacts concurrently.
Clients
AnchoreCTL
AnchoreCTL is a Go-based command line client for Anchore Enterprise. It can be used to send commands to the backend API as part of manual or automated operations. It can also be used to generate SBOM content that is local to the machine it is run on.
AnchoreCTL is the recommended client for developing custom integrations with CI/CD systems or other situations where local processing of content needs to be performed before being passed to the Enterprise API.
Anchore Enterprise GUI
The Anchore Enterprise GUI is a front end to the API services and simplifies many of the processes associated with creating policies, viewing SBOMs, creating and running reports, and configuring the overall system (notifications, users, registry credentials, and more).
Integrations
External systems can integrate with Anchore Enterprise using software entities that exercise select parts of the Anchore Enterprise API.
Such software entities can be executable agents or plugins. We use the generic term integration instance to refer to such a deployed software entity.
Enterprise can receive health reports from integration instances to track and monitor their status (assuming the integration instance implements that).
Kubernetes Admission Controller
The Kubernetes Admission Controller is a plugin that can be used to intercept a container image as it is about to be deployed to Kubernetes. The image is passed to Anchore Enterprise which analyzes it to determine if it meets the organization’s policy rules. The policy evaluation result can then allow, warn, or block the deployment.
Kubernetes and ECS Runtime Inventory
anchore-k8s-invetory and anchore-ecs-inventory are agents that creates an ongoing inventory of the images that are running in a Kubernetes or ECS cluster. The agentes run inside the runtime environment (under a service account) and connects to the local runtime API. The agents poll the API on an interval to retrieve a list of container images that are currently in use.
Multi-Tenancy
Accounts
Accounts in Anchore Enterprise are a boundary that separates data, policies, notifications, and users into a distinct domain. An account can be mapped to a team, project, or application that needs its own set of policies applied to a specific set of content. Users may be granted access to multiple accounts.
Users
Users are local to an account and can have roles as defined by RBAC. Usernames must be unique across the entire deployment to enable API-based authentication requests. Certain users can be configured such that they have the ability to switch context between accounts, akin to a super user account.
3 - Concepts
How does Anchore Enterprise work?
Anchore takes a data-driven approach to analysis and policy enforcement. The system has the following discrete phases for each image analyzed:
- Fetch the image content and extract it, but never execute it.
- Analyze the image by running a set of Anchore analyzers over the image content to extract and classify as much metadata as possible.
- Save the resulting analysis in the database for future use and audit.
- Evaluate policies against the analysis result, including vulnerability matches on the artifacts discovered in the image.
- Update to the latest external data used for policy evaluation and vulnerability matches (feed sync), and automatically update image analysis results against any new data found upstream.
- Notify users of changes to policy evaluations and vulnerability matches.
Repeat step 5 and 6 on intervals to ensure you have the latest external data and updated image evaluations.

The primary interface is a RESTful API that provides mechanisms to request analysis, policy evaluation, and monitoring of images in registries as well as query for image contents and analysis results. Anchore Enterprise also provides a command-line interface (CLI), and its own container.
The following modes provide different ways to use Anchore within the API:
- Interactive Mode - Use the APIs to explicitly request an image analysis, or get a policy evaluation and content reports. The system only performs operations when specifically requested by a user.
- Watch Mode - Use the APIs to configure Anchore Enterprise to poll specific registries and repositories/tags to watch for new images, and then automatically pull and evaluate them. The API sends notifications when a state changes for a tag’s vulnerability or policy evaluation.
Anchore can be easily integrated into most environments and processes using these two modes of operation.
Next Steps
Now let’s get familiar with Images in Anchore.
3.1 - Analyzing Images
Once an image is submitted to Anchore Enterprise for analysis, Anchore Enterprise will attempt to retrieve metadata about the image from the Docker registry and, if successful, will download the image and queue the image for analysis.
Anchore Enterprise can run one or more analyzer services to scale out processing of images. The next available analyzer worker will process the image.

During analysis, every package, software library, and file are inspected, and this data is stored in the Anchore database.
Anchore Enterprise includes a number of analyzer modules that extract data from the image including:
- Image metadata
- Image layers
- Operating System Package Data (RPM, DEB, APKG)
- File Data
- Ruby Gems
- Node.JS NPMs
- Java Archives
- Python Packages
- .NET NuGet Packages
- File content
Once a tag has been added to Anchore Enterprise, the repository will be monitored for updates to that tag. See Image and Tag Watchers for more information about images and tags.
Any updated images will be downloaded and analyzed.
Next Steps
Now let’s get familiar with the Image Analysis Process.
3.1.1 - Base and Parent Images
A Docker or OCI image is composed of layers. Some of the layers are created during a build process such as following instructions in a Dockerfile. But many of the layers will come from previously built images. These images likely come from a container team at your organization, or maybe build directly on images from a Linux distribution vendor. In some cases this chain could be many images deep as various teams add standard software or configuration.
Docker uses the FROM clause to denote an image to use as a basis for building a new image. The image provided in this clause is known by Docker as the Parent Image, but is commonly referred to as the Base Image. This chain of images built from other images using the FROM clause is known as an Image’s ancestry.
Note Docker defines Base Image as an image with a FROM SCRATCH clause. Anchore does NOT follow this definition, instead following the more common usage where Base Image refers to the image that a given image was built from.
Example Ancestry
The following is an example of an image with multiple ancestors
A base distro image, for example debian:10
FROM scratch
...
A framework container image from that debian image, for example a node.js image let’s call mynode:latest
FROM debian:10
# Install nodejs
The application image itself built from the framework container, let’s call it myapp:v1
FROM mynode:latest
COPY ./app /
...
These dockerfiles generate the following ancestry graph:
graph
debian:10-->|parent of|mynode:latest
mynode:latest-->|parent of|myapp:v1
Where debian:10 is the parent of mynode:latest which is the parent of myapp:v1
Anchore compares the layer digests of images that it knows about to determine an images ancestry. This ensures that the exact image used to build a new image is identified.
Given our above example, we may see the following layers for each image. Note that each subsequent image is a superset of the previous images layers
block-beta
columns 5
block:debian_block
columns 1
debian["debian:10"]
style debian stroke-width:0px
debian_layer1["sha256:abc"]
debian_layer2["sha256:def"]
space
space
end
space
block:mynode_block
columns 1
mynode_name["mynode:latest"]
style mynode_name stroke-width:0px
mynode_layer1["sha256:abc"]
mynode_layer2["sha256:def"]
mynode_layer3["sha256:123"]
space
end
space
block:myapp_block
columns 1
myapp_name["myapp:v1"]
style myapp_name stroke-width:0px
myapp_layer1["sha256:abc"]
myapp_layer2["sha256:def"]
myapp_layer3["sha256:123"]
myapp_layer4["sha256:456"]
end
mynode_name -- "FROM" --> debian
debian_layer1 --> mynode_layer1
mynode_layer1 --> debian_layer1
debian_layer2 --> mynode_layer2
mynode_layer2 --> debian_layer2
myapp_name -- "FROM" --> mynode_name
mynode_layer1 --> myapp_layer1
myapp_layer1 --> mynode_layer1
mynode_layer2 --> myapp_layer2
myapp_layer2 --> mynode_layer2
mynode_layer3 --> myapp_layer3
myapp_layer3 --> mynode_layer3Ancestry within Anchore
Anchore automatically calculates an image’s ancestry as images are scanned. This works by comparing the layer digests of each image to calculate the entire chain of images that produced a given image. The entire ancestry can be retrieved for an image through the GET /v2/images/{image_digest}/ancestors API. See the API docs for more information on the specifics.
Base Image
It is often useful to compare an image with another image in its ancestry. For example to filter out vulnerabilities that are present in a “golden image” from a platform team and only showing vulnerabilities introduced by the application being built on the “golden image”.
Controlling the Base Image
Users can control which ancestor is chosen as the base image by marking the desired image(s) with a special annotation anchore.user/marked_base_image. The annotation should be set to a value of true, otherwise it will be ignored. This annotation is currently restricted to users in the “admin” account.
If an image with this annotation should no longer be considered a Base Image then you must update the annotation to false, as it is not currently possible to remove annotations.
Usage of this annotation when calculating the Base Image can be disabled by setting services.policy_engine.enable_user_base_image to false in the configuration file (see deployment specific docs for configuring this setting).
Anchorectl Example
You can add an image with this annotation using AnchoreCTL with the following:
anchorectl image add anchore/test_images:ancestor-base -w --annotation "anchore.user/marked_base_image=true"
If an image should no longer be considered a Base Image you can update the annotation with:
anchorectl image add anchore/test_images:ancestor-base --annotation "anchore.user/marked_base_image=false"
Calculating the Base Image
Anchore will automatically calculate the Base Image from an image’s ancestry using the closest ancestor. From our example above, the Base Image for myapp:v1 is mynode:latest.
The first ancestor with this annotation will be used as the Base Image, if no ancestors have this annotation than it will fall back to using the closest ancestor (the Parent Image).
The rules for determining the Base Image are encoded in this diagram
graph
start([start])-->image
image[image]
image-->first_parent_exists
first_parent_exists{Does this image have a parent?}
first_parent_exists-->|No|no_base_image
first_parent_exists-->|yes|first_parent_image
first_parent_image[Parent Image]
first_parent_image-->config
config{User Base Annotations Enabled in configuration?}
config-->|No|base_image
config-->|yes|check_parent
check_parent{Parent has anchore.user/marked_base_image: true annotation}
check_parent-->|No|parent_exists
parent_exists{Does the parent image have a parent?}
parent_exists-->|Yes|parent_image
parent_image[/Move to next Parent Image/]
parent_image-->check_parent
parent_exists-->|No|no_base_image
check_parent-->|Yes|base_image
base_image([Found Base Image])
no_base_image([No Base Image Exists])Using the Base Image
The Policy evaluation and Vuln Scan APIs have an optional base_digest parameter that is used to provide comparison data between two images. These APIs can be used in conjunction with the ancestry API to perform comparisons to the Base Image so that application developers can focus on results in their direct control. As of Enterprise v5.7.0, a special value auto can also be specified for this parameter to have the system automatically determine which image to use in the comparison based on the above rules.
To read more about the base comparison features, jump to
In addition to these user facing APIs, a few parts of the system utilize the Ancestry information.
- The Ancestry Policy Gate uses the Base Image rules to determine which image to evaluate against
- Reporting uses the Base Image to calculate the “Inherited From Base” column for vulnerabilities
- The UI displays the Base Image and uses it for Policy Evaluations and Vulnerability Scans
Additional notes about ancestor calculations
An image B is only a child of Image A if All of the layers of Image A are present in Image B.
For example, mypython and mynode represent two different language runtime images built from a debian base. These two images are not ancestors of each other because the layers in mypython:latest are not a superset of the layers in mynode:latest, nor the other way around.
block-beta
columns 3
block:mypython_block
columns 1
mypython_name["mypython:latest"]
style mypython_name stroke-width:0px
mypython_layer1["sha256:abc"]
mypython_layer2["sha256:def"]
mypython_layer3["sha256:456"]
end
space
block:mynode_block
columns 1
mynode_name["mynode:latest"]
style mynode_name stroke-width:0px
mynode_layer1["sha256:abc"]
mynode_layer2["sha256:def"]
mynode_layer3["sha256:123"]
end
mypython_layer1 --> mynode_layer1
mynode_layer1 --> mypython_layer1
mypython_layer2 --> mynode_layer2
mynode_layer2 --> mypython_layer2
mypython_layer3 -- "X" --> mynode_layer3But these images could be based on a 3rd image which is made up of the 2 layers that they share. If Anchore knows about this 3rd image it would show up as an ancestor for both mypython and mynode.
The Anchore UI would identify the debian:10 image as an ancestor of the mypython:latest and the mynode:latest images. But we do not currently expose child ancestors, so we would not show the children of the debian:10 image.
block-beta
columns 5
block:mypython_block
columns 1
mypython_name["mypython:latest"]
style mypython_name stroke-width:0px
mypython_layer1["sha256:abc"]
mypython_layer2["sha256:def"]
mypython_layer4["sha256:456"]
end
space
block:debian_block
columns 1
debian["debian:10"]
style debian stroke-width:0px
debian_layer1["sha256:abc"]
debian_layer2["sha256:def"]
space
end
space
block:mynode_block
columns 1
mynode_name["mynode:latest"]
style mynode_name stroke-width:0px
mynode_layer1["sha256:abc"]
mynode_layer2["sha256:def"]
mynode_layer3["sha256:123"]
end
mynode_name -- "FROM" --> debian
debian_layer1 --> mynode_layer1
mynode_layer1 --> debian_layer1
debian_layer2 --> mynode_layer2
mynode_layer2 --> debian_layer2
mypython_name -- "FROM" --> debian
debian_layer1 --> mypython_layer1
mypython_layer1 --> debian_layer1
debian_layer2 --> mypython_layer2
mypython_layer2 --> debian_layer23.1.1.1 - Compare Base Image Policy Checks
This feature provides a mechanism to compare the policy checks for an image with those of a Base Image. You can read more about Base Image and how to
find them here. Base comparison uses the same policy and tag to evaluate both images to
ensure a fair comparison. The API yields a response similar to the policy checks API with an additional element within each triggered gate check to
indicate whether the result is inherited from the Base Image.
Usage
This functionality is currently available via the Enterprise UI and API.
API
Refer to API Access section for the API specification. The policy check API (GET /v2/images/{imageDigest}/check) has
an optional base_digest query parameter that can be used to specify an image to compare policy findings to. When this query parameter is provided
each of the finding’s inherited_from_base field will be filled in with true or false to denote if the finding is present in the provided image.
If no image is provided than the inherited_from_base field will be null to indicate no comparison was performed.
Example request using curl to retrieve policy check for an image digest sha256:xyz and tag p/q:r and compare the results to a Base Image digest sha256:abc
curl -X GET -u {username:password} "http://{servername:port}/v2/images/sha256:xyz/check?tag=p/q:r&base_digest=sha256:abc"
Example output:
{
"image_digest": "sha256:xyz",
"evaluated_tag": "p/q:r",
"evaluations": [
{
"comparison_image_digest": "sha256:abc",
"details": {
"findings": [
{
"trigger_id": "41cb7cdf04850e33a11f80c42bf660b3",
"gate": "dockerfile",
"trigger": "instruction",
"message": "Dockerfile directive 'HEALTHCHECK' not found, matching condition 'not_exists' check",
"action": "warn",
"policy_id": "48e6f7d6-1765-11e8-b5f9-8b6f228548b6",
"recommendation": "",
"rule_id": "312d9e41-1c05-4e2f-ad89-b7d34b0855bb",
"allowlisted": false,
"allowlist_match": null,
"inherited_from_base": true
},
{
"trigger_id": "CVE-2019-5435+curl",
"gate": "vulnerabilities",
"trigger": "package",
"message": "MEDIUM Vulnerability found in os package type (APKG) - curl (CVE-2019-5435 - http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-5435)",
"action": "warn",
"policy_id": "48e6f7d6-1765-11e8-b5f9-8b6f228548b6",
"recommendation": "",
"rule_id": "6b5c14e7-a6f7-48cc-99d2-959273a2c6fa",
"allowlisted": false,
"allowlist_match": null,
"inherited_from_base": false
}
]
...
}
...
}
...
]
}
Dockerfile directive 'HEALTHCHECK' not found, matching condition 'not_exists' check is triggered by both images and hence inherited_from_base
is marked trueMEDIUM Vulnerability found in os package type (APKG) - curl (CVE-2019-5435 - http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-5435) is not
triggered by the Base Image and therefore the value of inherited_from_base is false
3.1.1.2 - Compare Base Image Security Vulnerabilities
This feature provides a mechanism to compare the security vulnerabilities detected in an image with those of a Base Image. You can read more about base
images and how to find them here. The API yields a response similar to vulnerabilities API with an
additional element within each result to indicate whether the result is inherited from the Base Image.
Usage
This functionality is currently available via the Enterprise UI and API. Watch this space as we add base comparison support in other tools.
API
Refer to API Access section for the API specification. The vulnerabilities API GET /v2/images/{image_digest}/vuln/{vtype}
has a base_digest query parameter that can be used to specify an image to compare vulnerability findings to. When this query parameter is provided
an additional inherited_from_base field is provided for each vulnerability.
Example request using curl to retrieve security vulnerabilities for an image digest sha:xyz and compare the results to a Base Image digest sha256:abc
curl -X GET -u {username:password} "http://{servername:port}/v2/images/sha256:xyz/vuln/all?base_digest=sha256:abc"
Example output:
{
"base_digest": "sha256:abc",
"image_digest": "sha256:xyz",
"vulnerability_type": "all",
"vulnerabilities": [
{
"feed": "vulnerabilities",
"feed_group": "alpine:3.12",
"fix": "7.62.0-r0",
"inherited_from_base": true,
"nvd_data": [
{
"cvss_v2": {
"base_score": 6.4,
"exploitability_score": 10.0,
"impact_score": 4.9
},
"cvss_v3": {
"base_score": 9.1,
"exploitability_score": 3.9,
"impact_score": 5.2
},
"id": "CVE-2018-16842"
}
],
"package": "libcurl-7.61.1-r3",
"package_cpe": "None",
"package_cpe23": "None",
"package_name": "libcurl",
"package_path": "pkgdb",
"package_type": "APKG",
"package_version": "7.61.1-r3",
"severity": "Medium",
"url": "http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-16842",
"vendor_data": [],
"vuln": "CVE-2018-16842"
},
{
"feed": "vulnerabilities",
"feed_group": "alpine:3.12",
"fix": "2.4.46-r0",
"inherited_from_base": false,
"nvd_data": [
{
"cvss_v2": {
"base_score": 5.0,
"exploitability_score": 10.0,
"impact_score": 2.9
},
"cvss_v3": {
"base_score": 7.5,
"exploitability_score": 3.9,
"impact_score": 3.6
},
"id": "CVE-2020-9490"
}
],
"package": "apache2-2.4.43-r0",
"package_cpe": "None",
"package_cpe23": "None",
"package_name": "apache2",
"package_path": "pkgdb",
"package_type": "APKG",
"package_version": "2.4.43-r0",
"severity": "Medium",
"url": "http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-9490",
"vendor_data": [],
"vuln": "CVE-2020-9490"
}
]
}
Note that inherited_from_base is a new element in the API response added to support base comparison. The assigned boolean value indicates whether the
exact vulnerability is present in the Base Image. In the above example
- CVE-2018-16842 affects libcurl-7.61.1-r3 package in both images, hence
inherited_from_base is marked true - CVE-2019-5482 affects apache2-2.4.43-r0 package does not affect the Base Image and therefore
inherited_from_base is set to false
3.1.2 - Image Analysis Process
There are two types of image analysis:
- Centralized Analysis
- Distributed Analysis
Image analysis is performed as a distinct, asynchronous, and scheduled task driven by queues that analyzer workers periodically poll.
Image analysis_status states:
stateDiagram
[*] --> not_analyzed: analysis queued
not_analyzed --> analyzing: analyzer starts processing
analyzing --> analyzed: analysis completed successfully
analyzing --> analysis_failed: analysis fails
analyzing --> not_analyzed: re-queue by timeout or analyzer shutdown
analysis_failed --> not_analyzed: re-queued by user request
analyzed --> not_analyzed: re-queued for re-processing by user requestCentralized Analysis
The analysis process is composed of several steps and utilizes several
system components. The basic flow of that task as shown in the following example:
Centralized analysis high level summary:
sequenceDiagram
participant A as AnchoreCTL
participant R as Registry
participant E as Anchore Deployment
A->>E: Request Image Analysis
E->>R: Get Image content
R-->>E: Image Content
E->>E: Analyze Image Content (Generate SBOM and secret scans etc) and store results
E->>E: Scan sbom for vulns and evaluate complianceHere is an example of initiating this process using anchorectl
anchorectl image add docker.io/library/nginx:latest
This command tells the Anchore deployment to pull the image from Docker Hub, unpack it, generate an SBOM and then conduct a and vulnerability scan and policy evaluation.
The analyzers operate in a task loop for analysis tasks as shown below:

Adding more detail, the API call trace between services looks similar to the following example flow:

Distributed Analysis
In distributed analysis, the analysis of image content takes place outside the Anchore deployment and the result is imported into the deployment. The image has the same state machine transitions, but the ‘analyzing’ processing of an imported analysis is the processing of the import data (vuln scanning, policy checks, etc) to prepare the data for internal use, but does not download or touch any image content.
High level example with anchorectl:
sequenceDiagram
participant A as AnchoreCTL
participant R as Registry/Docker Daemon
participant E as Anchore Deployment
A->>R: Get Image content
R-->>A: Image Content
A->>A: Analyze Image Content (Generate SBOM and secret scans etc)
A->>E: Import SBOM, secret search, fs metadata
E->>E: Scan sbom for vulns and evaluate complianceHere is an example anchorectl command initiating distributed analysis:
anchorectl image add docker.io/library/nginx:latest --from registry
This command uses anchorectl to generate an SBOM locally and then uploads it to the Anchore deployment for vulnerability scanning and compliance evaluation.
Next Steps
Now let’s get familiar with Watching Images and Tags with Anchore.
3.1.2.1 - Malware Scanning
Overview
Anchore Enterprise provides malware scanning with the use ClamAV. ClamAV is an open-source
antivirus solution designed to detect malicious code embedded in container images.
When ClamAV Malware Scanner is enabled, malware scanning occurs during Centralized Analysis, when the image content itself is available.
Any findings are available via:
- API
/images/{image_digest}/content/malware) - AnchoreCTL
anchorectl image content <image_digest> -t malware - UI Image SBOM Tab
The Malware Policy Gate also provides compliance rules around any findings.
Anchore Enterprise 5.13 and above supports scanning of images greater than 2GB in size through splitting images for analysis.
Signature DB Updates
Each analyzer service will run a malware signature update before analyzing each image. This does add some latency to the overall analysis time but ensures the signatures
are as up-to-date as possible for each image analyzed. The update behavior can be disabled if you prefer to manage the freshness of the db via another route, such as a shared filesystem
mounted to all analyzer nodes that is updated on a schedule. See the configuration section for details on disabling the db update.
The status of the db update is present in each scan output for each image.
Scan Results
The malware content type is a list of scan results. Each result is the run of a malware scanner, by default clamav.
The list of files found to contain malware signature matches is in the findings property of each scan result. An empty array value indicates no matches found.
The metadata property provides generic metadata specific to the scanner. For the ClamAV implementation, this includes the version data about the signature db used and
if the db update was enabled during the scan. If the db update is disabled, then the db_version property of the metadata will not have values since the only way to get
the version metadata is during a db update.
{
"content": [
{
"findings": [
{
"path": "/somebadfile",
"signature": "Unix.Trojan.MSShellcode-40"
},
{
"path": "/somedir/somepath/otherbadfile",
"signature": "Unix.Trojan.MSShellcode-40"
}
],
"metadata": {
"db_update_enabled": true,
"db_version": {
"bytecode": "331",
"daily": "25890",
"main": "59"
}
},
"scanner": "clamav"
}
],
"content_type": "malware",
"imageDigest": "sha256:0eb874fcad5414762a2ca5b2496db5291aad7d3b737700d05e45af43bad3ce4d"
}
3.1.3 - Image and Tag Watchers
Overview
Anchore has the capability to monitor external Docker Registries for updates to tags as well as new tags. It also watches for updates to vulnerability databases and package metadata (the “Feeds”).
The process for monitoring updates to repositories, the addition of new tag names, is done on a duty cycle and performed by the Catalog component(s). The scheduling and tasks are driven by queues provided by the SimpleQueue service.
- Periodically, controlled by the cycle_timers configuration in the config.yaml of the catalog, a process is triggered to list all the Repository Subscription records in the system and for each record, add a task to a specific queue.
- Periodically, also controlled by the cycle_timers config, a process is triggered to pick up tasks off that queue and process repository scan tasks. Each task looks approximately like the following:

The output of this process is new tag_update subscription records, which are subsequently processed by the Tag Update handlers as described below. You can view the tag_update subscriptions using AnchoreCTL:
anchorectl subscription list -t tag_update
Tag Updates: New Images
To detect updates to tags, mapping of a new image digest to a tag name, Anchore periodically checks the registry and downloads the tag’s image manifest to compare the computed digests. This is done on a duty cycle for every tag_update subscription record. Therefore, the more subscribed tags exist in the system, the higher the load on the system to check for updates and detect changes. This processing, like repository update monitoring, is performed by the Catalog component(s).
The process, the duty-cycle of which is configured in the cycle_timers section of the catalog config.yaml is described below:

As new updates are discovered, they are automatically submitted to the analyzers, via the image analysis internal queue, for processing.
The overall process and interaction of these duty cycles works like:

Next Steps
Now let’s get familiar with Policy in Anchore.
3.1.4 - Analysis Archive
Anchore Enterprise is a data intensive system. Storage consumption grows with the number of images analyzed, which leaves the
following options for storage management:
- Over-provisioning storage significantly
- Increasing capacity over time, resulting in downtime (e.g. stop system, grow the db volume, restart)
- Manually deleting image analysis to free space as needed
In most cases, option 1 only works for a while, which then requires using 2 or 3. Managing storage provisioned for a
postgres DB is somewhat complex and may require significant data copies to new volumes to grow capacity over time.
To help mitigate the storage growth of the db itself, Anchore Enterprise already provides an object storage subsystem that
enables using external object stores like S3 to offload the unstructured data storage needs to systems that are
more growth tolerant and flexible. This lowers the db overhead but does not fundamentally address the issue of unbounded
growth in a busy system.
The Analysis Archive extends the object store even further by providing a system-managed way to move an image analysis
and all of its related data (policy evaluations, tags, annotations, etc) and moving it to a location outside of the main
set of images such that it consumes much less storage in the database when using an object store, perserves the last
state of the image, and supports moving it back into the main image set if it is needed in the future without requiring
that the image itself be reanalzyed–restoring from the archive does not require the actual docker image to exist at all.
To facilitate this, the system can be thought of as two sets of analysis with different capabilities and properties:

Working Set Images
The working set is the set of images in the ‘analyzed’ state in the system. These images are stored in the database,
optionally with some data in an external object store. Specifically:
- State = ‘analyzed’
- The set of images available from the /images api routes
- Available for policy evaluation, content queries, and vulnerability updates
Archive Set Images
The archive set of images are image analyses that reside almost entirely in the object store, which can be configured to
be a different location than the object store used for the working set, with minimal metadata in the anchore DB necessary
to track and restore the analysis back into the working set in the future. An archived image analysis preserves all the
annotations, tags, and metadata of the original analysis as well as all existing policy evaluation histories, but
are not updated with new vulnerabilities during feed syncs and are not available for new policy evaluations or content
queries without first being restored into the working set.
- Not listed in /images API routes
- Cannot have policy evaluations executed
- No vulnerability updates automatically (must be restored to working set first)
- Available from the /archives/images API routes
- Point-in-time snapshot of the analysis, policy evaluation, and vulnerability state of an image
- Independently configurable storage location (analysis_archive property in the services.catalog property of config.yaml)
- Small db storage consumption (if using external object store, only a few small records, bytes)
- Able to use different type of storage for cost effectiveness
- Can be restored to the working set at any time to restore full query and policy capabilities
- The archive object store is not used for any API operations other than the restore process
An image analysis, identified by the digest of the image, may exist in both sets at the same time, they are not mutually
exclusive, however the archive is not automatically updated and must be deleted an re-archived to capture updated state
from the working set image if desired.
Benefits of the Archive
Because archived image analyses are stored in a distinct object store and tracked with their own metadata in the db, the
images in that set will not impact the performance of working set image operations such as API operations, feed syncs, or
notification handling. This helps keep the system responsive and performant in cases where the set of images that you’re
interested in is much smaller than the set of images in the system, but you don’t want to delete the analysis because it
has value for audit or historical reasons.
- Leverage cheaper and more scalable cloud-based storage solutions (e.g. S3 IA class)
- Keep the working set small to manage capacity and api performance
- Ensure the working set is images you actively need to monitor without losing old data by sending it to the archive
Automatic Archiving
To help facilitate data management automatically, Anchore supports rules to define which data to archive and when
based on a few qualities of the image analysis itself. These rules are evaluated periodically by the system.
Anchore supports both account-scoped rules, editable by users in the account, and global system rules, editable only by
the system admin account users. All users can view system global rules such that they can understand what will affect
their images but they cannot update or delete the rules.
The process of automatic rule evaluation:
The catalog component periodically (daily by default, but configurable) will run through each rule in the system and
identify image digests should be archived according to either account-local rules or system global rules.
Each matching image analysis is added to the archive.
Each successfully added analysis is deleted from the working set.
For each digest migrated, a system event log entry is created, indicating that the image digest was moved to the
archive.
Archive Rules
The rules that match images are provide 3 selectors:
- Analysis timestamp - the age of the analysis itself, as expressed in days
- Source metadata (registry, repo, tag) - the values of the registry, repo, and tag values
- Tag history depth – the number of images mapped to a tag ordered by detected_at timestamp (the time at which the
system observed the mapping of a tag to a specific image manifest digest)
Rule scope:
- global - these rules will be evaluated against all images and all tags in the system, regardless of the owning account.
(system_global = true)
- account - these rules are only evaluated against the images and tags of the account which owns the rule. (system_global = false)
Example Rule:
{
"analysis_age_days": 10,
"created_at": "2019-03-30T22:23:50Z",
"last_updated": "2019-03-30T22:23:50Z",
"rule_id": "67b5f8bfde31497a9a67424cf80edf24",
"selector": {
"registry": "*",
"repository": "*",
"tag": "*"
},
"system_global": true,
"tag_versions_newer": 10,
"transition": "archive",
"exclude": {
"expiration_days": -1,
"selector": {
"registry": "docker.io",
"repository": "alpine",
"tag": "latest"
}
},
"max_images_per_account": 1000
}
- selector: a json object defining a set of filters on registry, repository, and tag that this rule will apply to.
- Each entry supports wildcards. e.g.
{"registry": "*", "repository": "library/*", "tag": "latest"}
- tag_versions_newer: the minimum number of tag->digest mappings with newer timestamps that must be preset for this rule to
match an image tag.
- analysis_age_days: the minimum age of the analysis to match, as indicated by the ‘analyzed_at’ timestamp on the image record.
- transition: the operation to perform, one of the following
- archive: works on the working set and transitions to archive, while deleting the source analysis upon successful
archive creation. Specifically: the analysis will “move” to the archive and no longer be in the working set.
- delete: works on the archive set and deletes the archived record on a match
- exclude: a json object defining a set of filters on registry, repository, and tag, that will exclude a subset of image(s)
from the selector defined above.
- expiration_days: This allows the exclusion filter to expire. When set to -1, the exclusion filter does not expire
- max_images_per_account: This setting may only be applied on a single “system_global” rule, and controls the maximum number of images
allows in the anchore deployment (that are not archived). If this number is exceeded, anchore will transition (according to the transition field value)
the oldest images exceeding this maximum count.
- last_seen_in_days: This allows images to be excluded from the archive, if there is a corresponding runtime inventory image, where last_seen_in_days is within the specified number of days.
- This field will exclude any images last seen in X number of days regardless of whether it’s in the exclude selector.
Rule conflicts and application:
For an image to be transitioned by a rule it must:
- Match at least 1 rule for each of its tag entries (either in working set if transition is archive or those in the
archive set, if a delete transition)
- All rule matches must be of the same scope, global and account rules cannot interact
Put another way, if any tag record for an image analysis is not defined to be transitioned, then the analysis record is
not transitioned.
Usage
Image analysis can be archived explicitly via the API (and CLI) as well as restored. Alternatively, the API and CLI can
manage the rules that control automatic transitions. For more information see the following:
Archiving an Image Analysis
See: Archiving an Image
Restoring an Image Analysis
See: Restoring an Image
Managing Archive Rules
See: Working with Archive Rules
3.2 - Policy
Once an image has been analyzed and its content has been discovered, categorized, and processed, the results can be evaluated against a user-defined set of checks to give a final pass/fail recommendation for an image. Anchore Enterprise policies are how users describe which checks to perform on what images and how the results should be interpreted.
A policy is made up from a set of rules that are used to perform an evaluation a container image. The rules can define checks against an image for things such as:
- security vulnerabilities
- package allowlists and denylists
- configuration file contents
- presence of credentials in image
- image manifest changes
- exposed ports
These checks are defined as Gates that contain Triggers that perform specific checks and emit match results and these define the things that the system can automatically evaluate and return a decision about.
For a full listing of gate, triggers, and their parameters see: Anchore Policy Checks
These policies can be applied globally or customized for specific images or categories of applications.
A policy evaluation can return one of two results:
PASSED indicating that image complies with your policy

FAILED indicating that the image is out of compliance with your policy.

Next Steps
Read more on Policies and Evaluation
3.2.1 - Policies and Evaluation
Introduction
Policies are the unit of policy definition and evaluation in Anchore Enterprise. A user may have multiple policies, but for a policy evaluation, the user must specify a policy to be evaluated or default to the policy currently marked ‘active’. See Policies Overview for more detail on manipulating and configuring policies.
Components of a Policy
A policy is a single JSON document, composed of several parts:
- Policy Gates - The named sets of rules and actions.
- Allowlists - Named sets of rule exclusions to override a match in a policy rule.
- Mappings - Ordered rules that determine which policies and allowlists should be applied to a specific image at evaluation time.
- Allowlisted Images - Overrides for specific images to statically set the final result to a pass regardless of the policy evaluation result.
- Blocklisted Images - Overrides for specific images to statically set the final result to a fail regardless of the policy evaluation result.
Example JSON for an empty policy, showing the sections and top-level elements:
{
"id": "default0",
"version": "2",
"name": "My Default policy",
"comment": "My system's default policy",
"allowlisted_images": [],
"denylisted_images": [],
"mappings": [],
"allowlists": [],
"rule_sets": []
}
Policies
A policy contains zero or more rule sets. The rule sets in a policy define the checks to make against an image and the actions to recommend if the checks find a match.
Example of a single rule set JSON object, one entry in the rule_set array of the larger policy document:
{
"name": "DefaultPolicy",
"version": "2",
"comment": "Policy for basic checks",
"id": "ba6daa06-da3b-46d3-9e22-f01f07b0489a",
"rules": [
{
"action": "STOP",
"gate": "vulnerabilities",
"id": "80569900-d6b3-4391-b2a0-bf34cf6d813d",
"params": [
{ "name": "package_type", "value": "all" },
{ "name": "severity_comparison", "value": ">=" },
{ "name": "severity", "value": "medium" }
],
"trigger": "package"
}
]
}
The above example defines a stop action to be produced for all package vulnerabilities found in an image that are severity medium or higher.
For information on how Rule Sets work and are evaluated, see: Rule Sets
Allowlists
An allowlist is a set of exclusion rules for trigger matches found during policy evaluation. An allowlist defines a specific gate and trigger_id (part of the output of a policy rule evaluation) that should have it’s action recommendation statically set to go. When a policy rule result is allowlisted, it is still present in the output of the policy evaluation, but it’s action is set to go and it is indicated that there was an allowlist match.
Allowlists are useful for things like:
- Ignoring CVE matches that are known to be false-positives
- Ignoring CVE matches on specific packages (perhaps if they are known to be custom patched)
Example of a simple allowlist as a JSON object from a policy:
{
"id": "allowlist1",
"name": "Simple Allowlist",
"version": "2",
"items": [
{ "id": "item1", "gate": "vulnerabilities", "trigger": "package", "trigger_id": "CVE-10000+libssl" },
{ "id": "item2", "gate": "vulnerabilities", "trigger": "package", "trigger_id": "CVE-10001+*" }
]
}
For more information, see Allowlists
Mappings
Mappings are named rules that define which rule sets and allowlists to evaluate for a given image. The list of mappings is evaluated in order, so the ordering of the list matters because the first rule that matches an input image will be used and all others ignored.
Example of a simple mapping rule set:
[
{
"name": "DockerHub",
"registry": "docker.io",
"repository": "library/postgres",
"image": { "type": "tag", "value": "latest" },
"rule_set_ids": [ "policy1", "policy2" ],
"allowlist_ids": [ "allowlist1", "allowlist2" ]
},
{
"name": "default",
"registry": "*",
"repository": "*",
"image": { "type": "tag", "value": "*" },
"rule_set_ids": [ "policy1" ],
"allowlist_ids": [ "allowlist1" ]
}
]
For more information about mappings see Mappings
Allowlisted Images
Allowlisted images are images, defined by registry, repository, and tag/digest/imageId, that will always result in a pass status for policy evaluation unless the image is also matched in the denylisted images section.
Example image allowlist section:
{
"name": "AllowlistDebianStable",
"registry": "docker.io",
"repository": "library/debian",
"image": { "type": "tag", "value": "stable" }
}
Denylisted Images
Denylisted images are images, defined by registry, repository, and tag/digest/imageId, that will always result in a policy policy evaluation status of fail. It is important to note that denylisting an image does not short-circuit the mapping evaluation or policy evaluations, so the full set of trigger matches will still be visible in the policy evaluation result.
Denylisted image matches override any allowlisted image matches (e.g. a tag matches a rule in both lists will always be blocklisted/fail).
Example image denylist section:
{
"name": "BlAocklistDebianUnstable",
"registry": "docker.io",
"repository": "library/debian",
"image": { "type": "tag", "value": "unstable" }
}
A complete policy example with all sections containing data:
{
"id": "default0",
"version": "2",
"name": "My Default policy",
"comment": "My system's default policy",
"allowlisted_images": [
{
"name": "AllowlistDebianStable",
"registry": "docker.io",
"repository": "library/debian",
"image": { "type": "tag", "value": "stable" }
}
],
"denylisted_images": [
{
"name": "DenylistDebianUnstable",
"registry": "docker.io",
"repository": "library/debian",
"image": { "type": "tag", "value": "unstable" }
}
],
"mappings": [
{
"name": "DockerHub",
"registry": "docker.io",
"repository": "library/postgres",
"image": { "type": "tag", "value": "latest" },
"rule_set_ids": [ "policy1", "policy2" ],
"allowlist_ids": [ "allowlist1", "allowlist2" ]
},
{
"name": "default",
"registry": "*",
"repository": "*",
"image": { "type": "tag", "value": "*" },
"rule_set_ids": [ "policy1" ],
"allowlist_ids": [ "allowlist1" ]
}
],
"allowlists": [
{
"id": "allowlist1",
"name": "Simple Allowlist",
"version": "2",
"items": [
{ "id": "item1", "gate": "vulnerabilities", "trigger": "package", "trigger_id": "CVE-10000+libssl" },
{ "id": "item2", "gate": "vulnerabilities", "trigger": "package", "trigger_id": "CVE-10001+*" }
]
},
{
"id": "allowlist2",
"name": "Simple Allowlist",
"version": "2",
"items": [
{ "id": "item1", "gate": "vulnerabilities", "trigger": "package", "trigger_id": "CVE-1111+*" }
]
}
],
"rule_sets": [
{
"name": "DefaultPolicy",
"version": "2",
"comment": "Policy for basic checks",
"id": "policy1",
"rules": [
{
"action": "STOP",
"gate": "vulnerabilities",
"trigger": "package",
"id": "rule1",
"params": [
{ "name": "package_type", "value": "all" },
{ "name": "severity_comparison", "value": ">=" },
{ "name": "severity", "value": "medium" }
]
}
]
},
{
"name": "DBPolicy",
"version": "1_0",
"comment": "Policy for basic checks on a db",
"id": "policy2",
"rules": [
{
"action": "STOP",
"gate": "vulnerabilities",
"trigger": "package",
"id": "rule1",
"params": [
{ "name": "package_type", "value": "all" },
{ "name": "severity_comparison", "value": ">=" },
{ "name": "severity", "value": "low" }
]
}
]
}
]
}
Policy Evaluation
A policy evaluation results in a status of pass or fail and that result based on the evaluation:
- The mapping section to determine which policies and allowlists to select for evaluation against the given image and tag
- The output of the policies’ triggers and applied allowlists.
- Denylisted images section
- Allowlisted images section
A pass status means the image evaluated against the policy and only go or warn actions resulted from the policy evaluation and allowlisted evaluations, or the image was allowlisted. A fail status means the image evaluated against the policy and at least one stop action resulted from the policy evaluation and allowlist evaluation, or the image was denylisted.
The flow chart for policy evaluation:

Next Steps
Read more about the Rule Sets component of a policy.
3.2.2 - Rule Sets
Overview
A rule set is a named set of rules, represented as a JSON object within a Policy. A rule set is made up of rules that define a specific check to perform and a resulting action.
A Rule Set is made up of:
- ID: a unique id for the rule set within the policy
- Name: a human readable name to give the policy (may contain spaces etc)
- A list of rules to define what to evaluate and the action to recommend on any matches for the rule
A simple example of a rule_set JSON object (found within a larger policy object):
{
"name": "DefaultPolicy",
"version": "2",
"comment": "Policy for basic checks",
"id": "policy1",
"rules": [
{
"action": "STOP",
"gate": "vulnerabilities",
"id": "rule1",
"params": [
{ "name": "package_type", "value": "all" },
{ "name": "severity_comparison", "value": ">=" },
{ "name": "severity", "value": "medium" }
],
"trigger": "package",
"recommendation": "Upgrade the package",
}
]
}
The above example defines a stop action to be produced for all package vulnerabilities found in an image that are severity medium or higher.
Policy evaluation is the execution of all defined triggers in the rule set against the image analysis result and feed data and results in a set of output trigger matches, each of which contains the defined action from the rule definition. The final recommendation value for the policy evaluation is called the final action, and is computed from the set of output matches: stop, go, or warn.

Policy Rules
Rules define the behavior of the policy at evaluation time. Each rule defines:
- Gate - example: dockerfile
- Trigger - example: exposed_ports
- Parameters - parameters specific to the gate/trigger to customize its match behavior
- Action - the action to emit if a trigger evaluation finds a match. One of stop, go, warn. The only semantics of these values are in the aggregation behavior for the policy result.
Gates
A Gate is a logical grouping of trigger definitions and provides a broader context for the execution of triggers against image analysis data. You can think of gates as the “things to be checked”, while the triggers provide the “which check to run” context. Gates do not have parameters themselves, but namespace the set of triggers to ensure there are no name conflicts.
Examples of gates:
- vulnerabilities
- packages
- npms
- files
- …
For a complete listing see: Anchore Policy Checks
Triggers
Triggers define a specific condition to check within the context of a gate, optionally with one or more input parameters. A trigger is logically a piece of code that executes with the image analysis content and feed data as inputs and performs a specific check. A trigger emits matches for each instance of the condition for which it checks in the image. Thus, a single gate/trigger policy rule may result in many matches in final policy result, often with different match specifics (e.g. package names, cves, or filenames…).
Trigger parameters are passed as name, value pairs in the rule JSON:
{
"action": "WARN",
"parameters": [
{ "name": "param1", "value": "value1" },
{ "name": "param2", "value": "value2" },
{ "name": "paramN", "value": "valueN" }
],
"gate": "vulnerabilities",
"trigger": "packages",
}
For a complete listing of gates, triggers, and the parameters, see: Anchore Policy Gates
Policy Evaluation
- All rules in a selected rule_set are evaluated, no short-circuits
- Rules who’s triggers and parameters find a match in the image analysis data, will “fire” resulting in a record of the match and parameters. A trigger may fire many times during an evaluation (e.g. many cves found).
- Each firing of a trigger generates a trigger_id for that match
- Rules may be executed in any order, and are executed in isolation (e.g. conflicting rules are allowed, it’s up to the user to ensure that policies make sense)
A policy evaluation will always contain information about the policy and image that was evaluated as well as the Final Action. The evaluation can optionally include additional detail about the specific findings from each rule in the evaluated rule_set as well as suggested remediation steps.
Policy Evaluation Findings
When extra detail is requested as part of the policy evaluation, the following data is provided for each finding produced by the rules in the evaluated rule_set.
- trigger_id - An ID for the specific rule match that can be used to allowlist a finding
- gate - The name of the gate that generated this finding
- trigger - The name of the trigger within the Gate that generated this finding
- message - A human readable description of the finding
- action - One of go, warn, stop based on the action defined in the rule that generated this finding
- policy_id - The ID for the rule_set that this rule is a part of
- recommendation - An optional recommendation provided as part of the rule that generated this finding
- rule_id - The ID of the rule that generated this finding
- allowlisted - Indicates if this match was present in the applied allowlist
- allowlist_match - Only provided if allowlisted is true, contains a JSON object with details about a allowlist match (allowlist id, name and allowlist rule id)
- inherited_from_base - An optional field that indicates if this policy finding was present in a provided comparison image
Excerpt from a policy evaluation, showing just the policy evaluation output:
...json
"findings": [
{
"trigger_id": "CVE-2008-3134+imagemagick-6.q16",
"gate": "package",
"trigger": "vulnerabilities",
"message": "MEDIUM Vulnerability found in os package type (dpkg) - imagemagick-6.q16 (CVE-2008-3134 - https://security-tracker.debian.org/tracker/CVE-2008-3134)",
"action": "go",
"policy_id": "48e6f7d6-1765-11e8-b5f9-8b6f228548b6",
"recommendation": "Upgrade the package",
"rule_id": "rule1",
"allowlisted": false,
"allowlist_match": null,
"inherited_from_base": false
},
{
"trigger_id": "CVE-2008-3134+libmagickwand-6.q16-2",
"gate": "package",
"trigger": "vulnerabilities",
"message": "MEDIUM Vulnerability found in os package type (dpkg) - libmagickwand-6.q16-2 (CVE-2008-3134 - https://security-tracker.debian.org/tracker/CVE-2008-3134)",
"action": "go",
"policy_id": "48e6f7d6-1765-11e8-b5f9-8b6f228548b6",
"recommendation": "Upgrade the package",
"rule_id": "rule1",
"allowlisted": false,
"allowlist_match": null,
"inherited_from_base": false
}
]
Final Action
The final action of a policy evaluation is the policy’s recommendation based on the aggregation of all trigger evaluations defined in the policy and the resulting matches emitted.
The final action of a policy evaluation will be:
- stop - if there are any triggers that match with this action, the policy evaluation will result in an overall stop.
- warn - if there are any triggers that match with this action, and no triggers that match with stop, then the policy evaluation will result in warn.
- go - if there are no triggers that match with either stop or warn, then the policy evaluation is result is a go. go actions have no impact on the evaluation result, but are useful for recording the results of specific checks on an image in the audit trail of policy evaluations over time
The policy findings are one part of the broader policy evaluation which includes things like image allowlists and denylists and makes a final policy evaluation status determination based on the combination of several component executions. See policies for more information on that process.
Next Steps
Read more about the Mappings component of a policy.
3.3 - Remediation
After Anchore analyzes images, discovers their contents and matches vulnerabilities, it can suggest possible actions that can be taken.
These actions range from adding a Healthcheck to your Dockerfile to upgrading a package version.
Since the solutions for resolving vulnerabilities can vary and may require several different forms of remediation and intervention, Anchore provides the capability to plan out your course of action.
Action Plans
Action plans group up the resolutions that may be taken to address the vulnerabilities or issues found in a particular image and provide a way for you to take action.
Currently, we support one type of Action Plan, which can be used to notify an existing endpoint configuration of those resolutions. This is a great way to facilitate communication across teams when vulnerabilities need to be addressed.
Here’s an example JSON that describes an Action Plan for notifications:
{
"type": "notification",
"image_tag": "docker.io/alpine:latest",
"image_digest": "sha256:c0e9560cda118f9ec63ddefb4a173a2b2a0347082d7dff7dc14272e7841a5b5a",
"bundle_id": "anchore_default_bundle",
"resolutions": [
{
"trigger_ids": ["CVE-2020-11-09-fake"],
"content": "This is a Resolution for the CVE",
}
],
"subject": "Actions required for image: alpine:latest",
"message": "These are some issues Anchore found in alpine:latest, and how to resolve them",
"endpoint": "smtp",
"configuration_id": "cda118f9ec63ddefb4a173a2b2a03"
}
Parts:
- type: The type of action plan being submitted (currently, only notification supported)
- image_tag: The full image tag of the image requiring action
- image_tag: The image digest of the image requiring action
- bundle_id: the id of the policy bundle that discovered the vulnerabilities
- resolutions: A list composed of the remediations and corresponding trigger IDs
- subject: The subject line for the action plan notification
- message: The body of the message for the action plan notification
- endpoint: The type of notification endpoint the action plan will be sent to
- configuration_id: The uuid of the notification configuration for the above endpoint
4 - Anchore Enterprise Data Service
Overview
Anchore operates a hosted service called the Anchore Data Service that serves pre-built datasets to customer Enterprise deployments.
Please review the Anchore Data Service status page for
information on how to check the status of the datasets.
Anchore Data Service currently manages five datasets:
- Vulnerability Database (vulnerability_db) - This dataset contains vulnerability data from the following sources:
- Alpine
- Amazon Linux
- Chain Guard
- CISA KEV (Known Exploited Vulnerabilities)
- Debian
- EPSS (Exploit Prediction Scoring System)
- Github
- Mariner
- MSRC
- NVD (Including the Anchore Enhancements)
- Oracle
- RHEL
- SLES
- Ubuntu
- Wolfi
- Vulnerability Match Exclusions (vulnerability_match_exclusions_db) - CVEs that Anchore has excluded from the feed.
- ClamAV Malware Database (clamav_db) - This dataset contains malware signatures that are used to detect malware in images.
These datasets are refreshed by pipelines that run every 6 hours.
Data Syncer Service Design
Anchore Enterprise includes a service, called the Data Syncer Service, that is responsible for syncing the datasets from the Anchore Data Service and making them available for use by the rest of Anchore Enterprise.

The following FQDN needs to be allowlisted in your network to allow the Data Syncer Service to communicate with the Anchore Data Service:
https://data.anchore-enterprise.com
Authentication for this service is provided by your Anchore Enterprise license. No additional credentials are required.
To learn more, please review the Data Syncer Service Configuration doc.