Anchore Secure - Vulnerability Management
Vulnerability management is the practice of identifying, categorising and remediating security vulnerabilities in software. Using a Software Bill of Materials (SBOM) as a foundation, Anchore Enterprise provides a mechanism for scanning containerized software for security vulnerabilities. With 100% API coverage and fully-documented APIs, users can automate vulnerability scanning and monitoring - performing scans in CI/CD pipelines, registries and Kubernetes platforms. Furthermore, Anchore Enterpise allows users to identify malware, secrets, and other security risks through catalogers.
Jump into a particular topic using the links below:
Vulnerability Data Sources
Vulnerability matching in Anchore Enterprise and Grype begins with collecting vulnerability data from multiple sources to identify vulnerabilities in the packages cataloged within an SBOM.
Anchore Enterprise and Grype consolidate data from these sources into a format suitable for vulnerability identification in SBOMs. One key source of data is the National Vulnerability Database (NVD). The NVD serves as a widely recognized, vendor-independent resource for vulnerability identification. Additionally, it provides a framework for measuring the severity of vulnerabilities. For instance, the NVD introduced the Common Vulnerability Scoring System (CVSS), which assigns numerical scores ranging from 0 to 10 to indicate the severity of vulnerabilities. These scores help organizations prioritize vulnerabilities based on their potential impact.
However, due to known limitations with NVD data, relying on additional sources becomes essential. Anchore Enterprise and Grype also collect vulnerability data from vendor-specific databases, which play a crucial role in accurate and efficient detection. These sources enable vulnerability matching from the vendor’s perspective. Examples of such vendor-specific databases include GitHub, the Microsoft Security Response Center (MSRC), and the Red Hat Security Response Database, among others.
Data Import & Normalization
Anchore has a tool called vunnel that is responsible for reaching out to various data sources, parsing and normalizing that data, then storing it for future use.
There is not one standard format for publishing vulnerability data, and even when there is a standardized data format, such as OVAL or OSV, those formats often have minor incompatible differences in their implementation. The purpose of vunnel is to understand each data source then output a single consistent format that can be used to construct a vulnerability database.
Providers
The process begins with vunnel reaching out to vulnerability data sources. These sources are known as “providers”. The following are a list of vunnel Providers:
- Alpine: Focuses on lightweight Linux distributions and provides vulnerability data tailored specifically to Alpine packages.
- Amazon: Offers vulnerability data for its cloud services and Linux distributions, such as Amazon Linux.
- Chainguard: Specializes in securing software supply chains and delivers vulnerability insights for containerized environments.
- Debian: Maintains a robust security tracker for vulnerabilities in its packages, concentrating on open-source software used in Debian-based systems.
- GitHub: Provides vulnerability data supported by an extensive advisory database for developers.
- Mariner (CBL-Mariner): Microsoft’s Linux distribution, provides vulnerability data within its ecosystem.
- NVD (National Vulnerability Database): Serves as the official U.S. government repository of vulnerability information.
- Oracle: Tracks vulnerabilities in Oracle Linux and other Oracle products, focusing on enterprise environments.
- RHEL (Red Hat Enterprise Linux): Delivers detailed and timely vulnerability data for Red Hat products.
- SLES (SUSE Linux Enterprise Server): Offers vulnerability data for SUSE Linux products, with a strong focus on enterprise solutions, particularly in cloud and container environments.
- Ubuntu: Maintains a well-documented vulnerability tracker and provides regular security updates for its popular Linux distribution.
- Wolfi: It is a community-driven, secure-by-default Linux-based distribution that emphasizes supply chain security and provides reliable vulnerability tracking.
vunnel reaches out to all of these providers, collates vulnerability data and consolidates it for use. The end product of the operations of vunnel is what we call the Grype database (GrypeDB).
Building GrypeDB
When the data from vunnel is collected into a database, we call that GrypeDB. This is a sqlite database that is used by both Grype and Anchore Enterprise for matching vulnerabilities. The Anchore Enterprise database and the Grype database (consolidated by vunnel) are not the same data. The hosted Anchore Enterprise database contains the consolidated GrypeDB as well as the Exclusion database and Microsoft MSRC vulnerability data.
Non-Anchore (upstream) Data Updates
When there are problems with other data sources, we contact those upstream sources and work with them to correct issues. Anchore has an “upstream first” policy for data corrections. Whenever possible we will work with upstream data sources rather than trying to correct only our data. We believe this creates a better overall vulnerability data ecosystem, and fosters beneficial collaboration channels between Anchore and the upstream projects.
An example of how we submit upstream data updates can be seen in the GitHub Advisory Database HERE
Data Enrichment
Due to the known issues with the NVD, Anchore Enterprise enhances the quality of its data for analysis by enriching the information obtained from the NVD. This process involves human intervention to review and correct the data. Once this manual process is completed, the cleaned and refined data is stored in the Anchore Enrichment Database.
The Anchore Enriched Data can be reviewed in GitHub HERE.
The scripts that drive this enrichment process are also in GitHub HERE
Before implementing this process, correcting NVD data was a challenge. However, with our enrichment process, we now have the flexibility to make changes to affected products and versions. The key advantage is that the data used by Anchore Enterprise is now highly reliable, ensuring that any downloaded data is accurate and free from the common issues associated with NVD data.
An example of enriching NVD data for more accurate detection is CVE-2024-4030, which was initially identified as affecting Debian when it actually only impacts Windows. By applying our enrichment process, we were able to correct this error.
Vulnerability Matching Process
When it’s time to compare the data from an SBOM to the vulnerability data constructed into Anchore Enterprise, we call that matching. Anytime vulnerability data is surfaced in Anchore Enterprise, that data is the result of vulnerability matches.
CPE Matching
CPE which stands for Common Platform Enumeration is a structured naming scheme standardized by the National Institute of Standards and Technology (NIST) to describe software, hardware, and firmware. It uses a standardized format that helps tools and systems compare and identify products efficiently.
CPE matching involves comparing the CPEs found in the SBOM of a software product against a list of known CPE entries to find a match. The diagram below illustrates the steps involved in CPE matching.
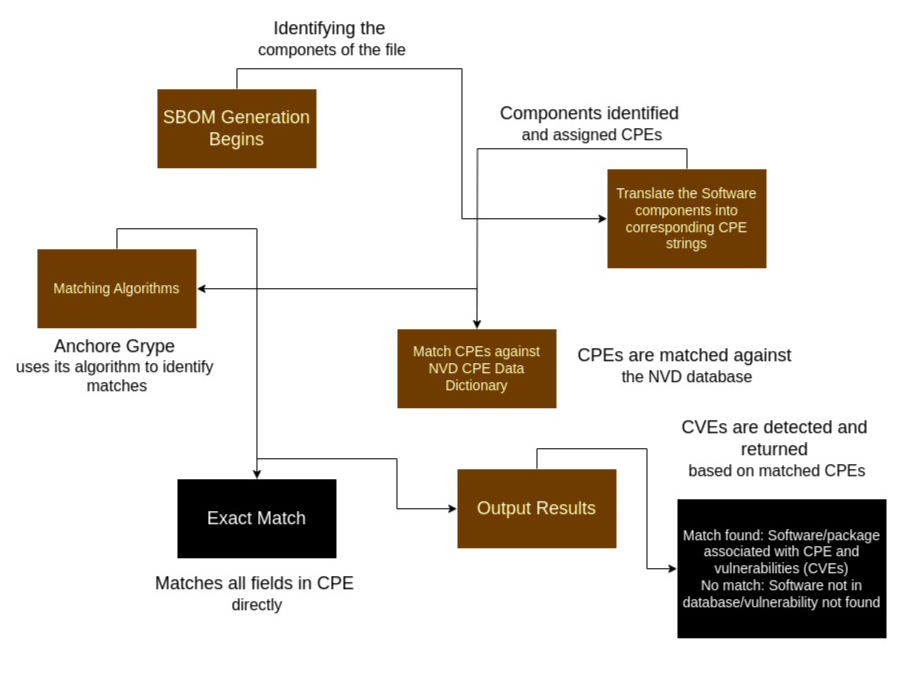
Due to the current state of the NVD data as mentioned above, CPE matching can sometimes lead to false positives. This led to the creation of the exclusions dataset that we manage in Anchore Enterprise. Vulnerability matching can be further tuned through our ability to disable CPE matching for a supported ecosystem.
Vulnerability Match Exclusions
There are times we cannot solve a false positive match using data alone. This is generally due to limitations of how CPE matching works. In those instances, Anchore Enterprise has a concept called Vulnerability Match Exclusions. These exclusions allow us to remove a vulnerability from the findings for a specific set of match criteria.
The data for the vulnerability match exclusions is held in a private repository. The data behind this list is not included in the open source Grype vulnerability data.
For example, if we look at CVE-2012-2055 which is a vulnerability reported against the GitHub product. When trying to match a CPE against this CVE, CPE is unable to capture this level of detail. GitHub libraries for different ecosystems will show up as affected. The Python GitHub library is an example. In order to resolve this, we exclude the language ecosystems using a match exclusion.
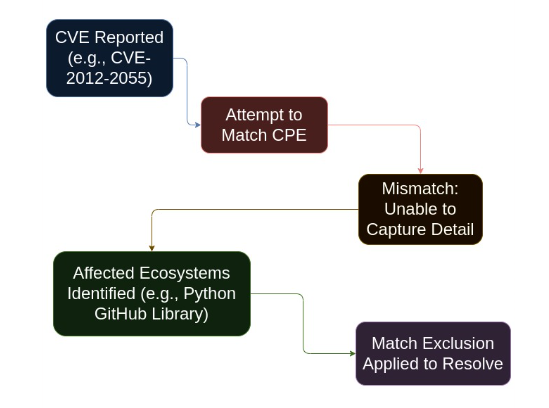
The exclusion data can be seen below:
exclusions:
- constraints:
- namespaces:
- nvd:cpe
packages:
- language: java
- language: python
- language: javascript
- language: ruby
- language: rust
- language: go
- language: php
justification: This vulnerability affects the GitHub product suite, not language-specific clients
id: CVE-2012-2055
Matching
The matching process that happens against an SBOM is the same basic process in both Grype and Anchore Enterprise. The vulnerability data is stored in GrypeDB, details such as vulnerability ID, package and versions affected as well as fix information are part of these records.
For example for vulnerability CVE-2024-9823 we store the package name, Jetty, the fixed version, 9.4.54, and which ecosystems are affected, such as Debian, NVD, and Java. We call these ecosystems a namespace in the context of a match.
The namespace used for the match is determined by the package stored in the SBOM. For a Debian package, the Debian namespace would be used, for Java - GitHub will be used by default in Grype, but NVD will be used by default in Anchore Enterprise. The default matcher for Java can be changed in Anchore Enterprise, we encourage you to do so as it will result in higher quality matches. We will be changing this default in a future release. See disabling CPE matching per supported ecosystem
The details about the versions affected will be used to determine if the version reported by the SBOM falls within the affected range. If it does, the vulnerability matches.
For a successful match, the fixed details field will be used to display which version fixes a particular vulnerability. The fix details are specific to each namespace. The version in Debian that fixes this vulnerability, 9.4.54-1, is not the same as the version that fixes the Java package, 9.4.54.
It should also be noted that if a vulnerability appears on the match exclusion list, it would be removed as a match.
Once a match exists, then additional metadata can be surfaced. We store details such as severity and CVSS in this table. Sometimes a field could be missing, such as severity or CVSS. Missing fields will be filled in with the data from NVD if it is available there.
Vulnerability Matching Configuration
Search by CPE can be globally configured per supported ecosystem via the anchore enterprise policy engine config. The default enables search by cpe for all ecosystems except for javascript (since NPM package vulnerability reports are exhaustively covered by the GitHub Security Advisory Database).
A fully-specified default config is as below:
policy_engine:
vulnerabilities:
matching:
default:
search:
by_cpe:
enabled: true
ecosystem_specific:
dotnet:
search:
by_cpe:
enabled: true
golang:
search:
by_cpe:
enabled: true
java:
search:
by_cpe:
enabled: true
javascript:
search:
by_cpe:
enabled: false
python:
search:
by_cpe:
enabled: true
ruby:
search:
by_cpe:
enabled: true
stock:
search:
by_cpe:
# Disabling search by CPE for the stock matcher will entirely disable binary-only matches
# and is *NOT ADVISED*
enabled: true
A shorter form of the default config is:
policy_engine:
vulnerabilities:
matching:
default:
search:
by_cpe:
enabled: true
ecosystem_specific:
javascript:
search:
by_cpe:
enabled: false
If disabling search by CPE for all GitHub covered ecosystems is desired, the config would look like:
policy_engine:
vulnerabilities:
matching:
default:
search:
by_cpe:
enabled: false
ecosystem_specific:
stock:
search:
by_cpe:
enabled: true
Comprehensive Distributions
When matching vulnerabilities against a Linux distribution, such as Alpine, Red Hat, or Ubuntu, there is a concept we call “comprehensive distribution”. A comprehensive distribution reports both fixed and unfixed vulnerabilities in their data feed.
For example, Red Hat reports on all vulnerabilities, including unfixed vulnerabilities. Some distros, like Alpine, do not report unfixed vulnerabilities. When a distribution does not contain comprehensive vulnerability information, we fall back to other data sources as a best effort to determine vulnerabilities that affect Alpine and are not fixed yet.
Redhat Enterprise Linux (RHEL) Extended Update Support (EUS)
Anchore Enterprise supports the use of RHEL EUS data when scanning relevant container images for vulnerabilities.
By default, Anchore Enterprise will use RHEL EUS data for any RHEL-based image that is automatically identified as having EUS support during the image analysis process. Note that this applies only to images analysed using Anchore Enterprise version 5.21.0 or later.
The default behaviour can be overridden at the system level by altering your vulnerability scanning configuration, or at the image level by applying the anchore.user/extended_support annotation to individual images.
To specify that a RHEL-based image should use EUS data for vulnerability scanning regardless of EUS support detection, set the anchore.user/extended_support annotation to true.
anchorectl image add myrepo.example.com:5000/my_app/:latest --annotation "anchore.user/extended_support=true"
To specify that a RHEL-based image should not use EUS data for vulnerability scanning regardless of EUS support detection, set the anchore.user/extended_support annotation to false.
anchorectl image add myrepo.example.com:5000/my_app/:latest --annotation "anchore.user/extended_support=false"
Annotations can also be added via the UI.
For more information on the presentation of Extended Update Support detection and its use in image vulnerability scans, see the API documentation for the /images/{image_digest} and /images/{image_digest}/vuln/{vuln_type} APIs.
Fix Details
There are some additional details for the fixed data from NVD that should be explained. NVD doesn’t contain explicit fix information for a given vulnerability. Other namespaces do, such as GitHub and Debian. There is a concept of “Less Than” and “Less Than or Equal” in the NVD data. When a vulnerability is tagged with “Less Than or Equal”, it could mean there is no fix available, or the fix couldn’t be figured out, or a fix was unavailable at the time NVD looked at it. In those cases we cannot show fix details for a vulnerability match.
If NVD uses “Less Than”, it is assumed that the version noted is the fixed version, unless that version is part of the affected range of a subsequent CPE configuration for the same CVE. We will present that version as containing the fix.
For example if we see data that looks like this:
some_package LessThan 1.2.3
We would assume version 1.2.3 contains the fix, and any version less than that, such as 1.2.2 is vulnerable. Alternatively, if we see:
some_package LessThanOrEqual 1.2.2
We know version 1.2.2 and below are vulnerable. We however do not know which version contains the fix. It could be in version 1.3.0, or 1.2.3, or even 2.0.0. In these cases we do not surface fixed details. If we are able to figure out such details in the future, we will update our CVE data.
Windows Scanning
Anchore can analyze and provide vulnerability matches for Microsoft Windows images. Anchore downloads, unpacks, and analyzes the Microsoft Windows image contents similar to Linux-based images, providing OS information as well as discovered application packages like npms, gems, python, NuGet, and java archives.
Vulnerabilities for Microsoft Windows images are matched against the detected operating system version and KBs installed in the image. These are matched using data from the Microsoft Security Research Center (MSRC) data API.
Supported Windows Base Image Versions
The following are the MSRC Product IDs that Anchore can detect and provide vulnerability information for. These provide the basis for the main variants of the base
Windows containers: Windows, ServerCore, NanoSerer, and IoTCore
| Product ID | Name |
|---|
| 10951 | Windows 10 Version 1703 for 32-bit Systems |
| 10952 | Windows 10 Version 1703 for x64-based Systems |
| 10729 | Windows 10 for 32-bit Systems |
| 10735 | Windows 10 for x64-based Systems |
| 10789 | Windows 10 Version 1511 for 32-bit Systems |
| 10788 | Windows 10 Version 1511 for x64-based Systems |
| 10852 | Windows 10 Version 1607 for 32-bit Systems |
| 10853 | Windows 10 Version 1607 for x64-based Systems |
| 11497 | Windows 10 Version 1803 for 32-bit Systems |
| 11498 | Windows 10 Version 1803 for x64-based Systems |
| 11563 | Windows 10 Version 1803 for ARM64-based Systems |
| 11568 | Windows 10 Version 1809 for 32-bit Systems |
| 11569 | Windows 10 Version 1809 for x64-based Systems |
| 11570 | Windows 10 Version 1809 for ARM64-based Systems |
| 11453 | Windows 10 Version 1709 for 32-bit Systems |
| 11454 | Windows 10 Version 1709 for x64-based Systems |
| 11583 | Windows 10 Version 1709 for ARM64-based Systems |
| 11644 | Windows 10 Version 1903 for 32-bit Systems |
| 11645 | Windows 10 Version 1903 for x64-based Systems |
| 11646 | Windows 10 Version 1903 for ARM64-based Systems |
| 11712 | Windows 10 Version 1909 for 32-bit Systems |
| 11713 | Windows 10 Version 1909 for x64-based Systems |
| 11714 | Windows 10 Version 1909 for ARM64-based Systems |
| 10379 | Windows Server 2012 (Server Core installation) |
| 10543 | Windows Server 2012 R2 (Server Core installation) |
| 10816 | Windows Server 2016 |
| 11571 | Windows Server 2019 |
| 10855 | Windows Server 2016 (Server Core installation) |
| 11572 | Windows Server 2019 (Server Core installation) |
| 11499 | Windows Server, version 1803 (Server Core Installation) |
| 11466 | Windows Server, version 1709 (Server Core Installation) |
| 11647 | Windows Server, version 1903 (Server Core installation) |
| 11715 | Windows Server, version 1909 (Server Core installation) |
Windows Operating System Packages
Just as Linux images are scanned for packages such as RPMs, DPKG, and APK, Windows images are scanned for the installed components and Knowledge Base patches (KBs). When listing operating system content on a Microsoft Windows image, the results returned are KB identifiers that are numeric. Both the name and version will
be identical and are the KB IDs.
1.1 - Analyzing Images via CTL
Introduction
In this section you will learn how to analyze images with Anchore Enterprise using AnchoreCTL in two different ways:
- Distributed Analysis: Content analysis by AnchoreCTL where it is run and importing the analysis to your Anchore deployment
- Centralized Analysis: The Anchore deployment downloads and analyzes the image content directly
Using AnchoreCTL for Centralized Analysis
Overview
This method of image analysis uses the Enterprise deployment itself to download and analyze the image content. You’ll use AnchoreCTL to make API requests to Anchore to tell it which image to analyze but the Enterprise deployment does the work.
You can refer to the Image Analysis Process document in the concepts section to better understand how centralized analysis works in Anchore.
sequenceDiagram
participant A as AnchoreCTL
participant R as Registry
participant E as Anchore Deployment
A->>E: Request Image Analysis
E->>R: Get Image content
R-->>E: Image Content
E->>E: Analyze Image Content (Generate SBOM and secret scans etc) and store results
E->>E: Scan sbom for vulns and evaluate complianceUsage
The anchorectl image add command instructs the Anchore Enterprise deployment to pull (download) and analyze an image from a registry. Anchore Enterprise will attempt to retrieve metadata about the image from the Docker registry and if successful will initiate a pull of the image and queue the image for analysis. The command will output details about the image including the image digest, image ID, and full name of the image.
anchorectl image add docker.io/library/nginx:latest
anchorectl image add docker.io/library/nginx:latest
✔ Added Image
Image:
status: not-analyzed (active)
tag: docker.io/library/nginx:latest
digest: sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc
id: 2b7d6430f78d432f89109b29d88d4c36c868cdbf15dc31d2132ceaa02b993763
For an image that has not yet been analyzed, the status will appear as not_analyzed. Once the image has been downloaded it will be queued for analysis. When the analysis begins the status will be updated to analyzing, after which te status will update to analyzed.
Anchore Enterprise can be configured to have a size limit for images being added for analysis. Attempting to add an image that exceeds the configured size will fail, return a 400 API error, and log an error message in the catalog service detailing the failure. This feature is disabled by default so see documentation for additional details on the functionality of this feature and instructions on how to configure the limit.
Using AnchoreCTL for Distributed Analysis
Overview
This way of adding images uses anchorectl to performs analysis of an image outside the Enterprise deployment, so the Enterprise deployment never
downloads or touches the image content directly. The generation of the SBOM, secret searches, filesystem metadata, and content searches are all
performed by AnchoreCTL on the host where it is run (CI, laptop, runtime node, etc) and the results are imported to the Enterprise deployment where it can be scanned for vulnerabilities and evaluated against policy.
sequenceDiagram
participant A as AnchoreCTL
participant R as Registry/Docker Daemon
participant E as Anchore Deployment
A->>R: Get Image content
R-->>A: Image Content
A->>A: Analyze Image Content (Generate SBOM and secret scans etc)
A->>E: Import SBOM, secret search, fs metadata
E->>E: Scan sbom for vulns and evaluate complianceConfiguration
Enabling the full set of analyzers, “catalogers” in AnchoreCTL terms, requires updates to the config file used by AnchoreCTL. See Configuring AnchoreCTL for more information on the format and options.
Usage
Note
To locally analyze an image that has been pushed to a registry, it is strongly recommended to use the ‘–from registry’ rather than ‘–from docker’.
This removes the need to have docker installed and also results in a consistent image digest for later use. The registry option gives anchorectl access
to data that the docker source does not due to limitations with the Docker Daemon itself and how it handles manifests and image digests.
The anchorectl image add --from [registry|docker] command will run a local SBOM-generation and analysis (secret scans, filesystem metadata, and content searches) and upload the result to Anchore Enterprise without ever having that image touched or loaded by your Enterprise deployment.
anchorectl image add docker.io/library/nginx:latest --from registry
anchorectl image add docker.io/library/nginx:latest --from registry -n
✔ Added Image
Image:
status: not-analyzed (active)
tag: docker.io/library/nginx:latest
digest: sha256:89020cd33be2767f3f894484b8dd77bc2e5a1ccc864350b92c53262213257dfc
id: 2b7d6430f78d432f89109b29d88d4c36c868cdbf15dc31d2132ceaa02b993763
For an image that has not yet been analyzed, the status will appear as not_analyzed. Once the image has been downloaded it will be queued for analysis. When the analysis begins the status will be updated to analyzing, after which te status will update to analyzed.
The ‘–platform’ option in distributed analysis specifies a different platform than the local hosts’ to use when retrieving the image from the registry for analysis by AnchoreCTL.
anchorectl image add alpine:latest --from registry --platform linux/arm64
Adding images that you own
For images that you are building yourself, the Dockerfile used to build the image should always be passed to Anchore Enterprise at the time of image addition. This is achieved by adding the image as above, but with the additional option to pass the Dockerfile contents to be stored with the system alongside the image analysis data.
This can be achieved in both analysis modes.
For centralized analysis:
anchorectl image add myrepo.example.com:5000/app/webapp:latest --dockerfile /path/to/Dockerfile
For distributed analysis:
anchorectl image add myrepo.example.com:5000/app/webapp:latest --from registry --dockerfile /path/to/Dockerfile
To update an image’s Dockerfile, simply run the same command again with the path to the updated Dockerfile along with ‘–force’ to re-analyze the image with the updated Dockerfile. Note that running add without --force (see below) will not re-add an image if it already exists.
Providing Dockerfile content is supported in both push and pull modes for adding images.
Additional Options
When adding an image, there are some additional (optional) parameters that can be used. We show some examples below and all apply to both distributed and centralize analysis workflows.
anchorectl image add docker.io/library/alpine:latest --force
✔ Added Image docker.io/library/alpine:latest
Image:
status: not-analyzed (active)
tags: docker.io/alpine:3
docker.io/alpine:latest
docker.io/dnurmi/testrepo:test0
docker.io/library/alpine:latest
digest: sha256:1304f174557314a7ed9eddb4eab12fed12cb0cd9809e4c28f29af86979a3c870
id: 9c6f0724472873bb50a2ae67a9e7adcb57673a183cea8b06eb778dca859181b5
distro: [email protected] (amd64)
layers: 1
the --force option can be used to reset the image analysis status of any image to not_analyzed, which is the base analysis state for an image. This option shouldn’t be necessary to use in normal circumstances, but can be useful if image re-analysis is needed for any reason desired.
anchorectl image add myrepo.example.com:5000/app/webapp:latest --dockerfile /path/to/dockerfile --annotation owner=someperson --annotation [email protected]
the --annotation parameter can be used to specify ‘key=value’ pairs to associate with the image at the time of image addition. These annotations will then be carried along with the tag, and will appear in image records when fetched, and in webhook notification payloads that contain image information when they are sent from the system. To change an annotation, simply run the add command again with the updated annotation and the old annotation will be overriden.
anchorectl image add alpine:latest --no-auto-subscribe
the ‘–no-auto-subscribe’ flag can be used if you do not wish for the system to automatically subscribe the input tag to the ’tag_update’ subscription, which controls whether or not the system will automatically watch the added tag for image content updates and pull in the latest content for centralized analysis. See Subscriptions for more information about using subscriptions and notifications in Anchore.
These options are supported in both distributed and centralized analysis.
In this example, we’re adding docker.io/mysql:latest, if we attempt to add a tag that mapped to the same image, for example docker.io/mysql:8 Anchore Enterprise will detect the duplicate image identifiers and return a detail of all tags matching that image.
Image:
status: analyzed (active)
tags: docker.io/mysql:8
docker.io/mysql:latest
digest: sha256:8191525e9110aa32b436a1ec772b76b9934c1618330cdb566ca9c4b2f01b8e18
id: 4390e645317399cc7bcb50a5deca932a77a509d1854ac194d80ed5182a6b5096
distro: [email protected] (amd64)
layers: 11
Deleting An Image
The following command instructs Anchore Enterprise to delete the image analysis from the working set using a tag. The --force option must be used if there is only one digest associated with the provided tag, or any active subscriptions are enabled against the referenced tag.
anchorectl image delete mysql:latest --force
┌─────────────────────────────────────────────────────────────────────────┬──────────┐
│ DIGEST │ STATUS │
├─────────────────────────────────────────────────────────────────────────┼──────────┤
│ sha256:8191525e9110aa32b436a1ec772b76b9934c1618330cdb566ca9c4b2f01b8e18 │ deleting │
└─────────────────────────────────────────────────────────────────────────┴──────────┘
To delete a specific image record, the digest can be supplied instead to ensure it is the exact image record you want:
anchorectl image delete sha256:899a03e9816e5283edba63d71ea528cd83576b28a7586cf617ce78af5526f209
┌─────────────────────────────────────────────────────────────────────────┬──────────┐
│ DIGEST │ STATUS │
├─────────────────────────────────────────────────────────────────────────┼──────────┤
│ sha256:899a03e9816e5283edba63d71ea528cd83576b28a7586cf617ce78af5526f209 │ deleting │
└─────────────────────────────────────────────────────────────────────────┴──────────┘
Deactivate Tag Subscriptions
Check if the tag has any active subscriptions.
anchorectl subscription list
anchorectl subscription list
✔ Fetched subscriptions
┌──────────────────────────────────────────────────────────────────────┬─────────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────────────────────────────────────────────────────────┼─────────────────┼────────┤
│ docker.io/alpine:latest │ policy_eval │ false │
│ docker.io/alpine:3.12.4 │ policy_eval │ false │
│ docker.io/alpine:latest │ vuln_update │ false │
│ docker.io/redis:latest │ policy_eval │ false │
│ docker.io/centos:8 │ policy_eval │ false │
...
...
If the tag has an active subscription(s), then can disabled (deactivated) in order to permit deletion:
anchorectl subscription deactivate docker.io/alpine:3.12.6 tag_update
✔ Deactivate subscription
Key: docker.io/alpine:3.12.6
Type: tag_update
Id: a6c7559deb7d5e20621d4a36010c11b0
Active: false
Advanced
Anchore Enterprise also allows adding images directly by digest / tag / timestamp tuple, which can be useful to add images that are still available in a registry but not associated with a current tag any longer.
To add a specific image by digest with the tag it should be associated with:
anchorectl image add docker.io/nginx:stable@sha256:f586d972a825ad6777a26af5dd7fc4f753c9c9f4962599e6c65c1230a09513a8
Note: this will submit the specific image by digest with the associated tag, but Anchore will treat that digest as the most recent digest for the tag, so if the image registry actually has a different history (e.g. a newer image has been pushed to that tag), then the tag history in Anchore may not accurately reflect the history in the registry.
Next Steps
Next, let’s find out how to Inspect Image Content
1.1.1 - Inspecting Image Content
Introduction
During the analysis of container images, Anchore Enterprise performs deep inspection, collecting data on all artifacts in the image including files, operating system packages and software artifacts such as Ruby GEMs and Node.JS NPM modules.
Inspecting images
The image content command can be used to return detailed information about the content of the container image.
anchorectl image content INPUT_IMAGE -t CONTENT_TYPE
The INPUT_IMAGE can be specified in one of the following formats:
- Image Digest
- Image ID
- registry/repo:tag
the CONTENT_TYPE can be one of the following types:
- os: Operating System Packages
- files: All files in the image
- go: GoLang modules
- npm: Node.JS NPM Modules
- gem: Ruby GEMs
- java: Java Archives
- python: Python Artifacts
- nuget: .NET NuGet Packages
- binary: Language runtime locations and version (e.g. openjdk, python, node)
- malware: ClamAV mailware scan results, if enabled
You can always get the latest available content types using the ‘-a’ flag:
anchorectl image content library/nginx:latest -a
✔ Fetched content [fetching available types] library/nginx:latest
binary
files
gem
go
java
malware
npm
nuget
os
python
For example:
anchorectl image content library/nginx:latest -t files
✔ Fetched content [0 packages] [6099 files] library/nginx:latest
Files:
┌────────────────────────────────────────────────────────────────────────────────────────────────────┬────────────────────────────────────────────────────────────────────────────────────────────────────┬───────┬─────┬─────┬───────┬───────────────┬──────────────────────────────────────────────────────────────────┐
│ FILE │ LINK │ MODE │ UID │ GID │ TYPE │ SIZE │ SHA256 DIGEST │
├────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────────────────────────────────────────────────────────────────────────────────────────┼───────┼─────┼─────┼───────┼───────────────┼──────────────────────────────────────────────────────────────────┤
│ /bin │ │ 00755 │ 0 │ 0 │ dir │ 0 │ │
│ /bin/bash │ │ 00755 │ 0 │ 0 │ file │ 1.234376e+06 │ d86b21405852d8642ca41afae9dcf0f532e2d67973b0648b0af7c26933f1becb │
│ /bin/cat │ │ 00755 │ 0 │ 0 │ file │ 43936 │ e9165e34728e37ee65bf80a2f64cd922adeba2c9f5bef88132e1fc3fd891712b │
│ /bin/chgrp │ │ 00755 │ 0 │ 0 │ file │ 72672 │ f47bc94792c95ce7a4d95dcb8d8111d74ad3c6fc95417fae605552e8cf38772c │
│ /bin/chmod │ │ 00755 │ 0 │ 0 │ file │ 64448 │ b6365e442b815fc60e2bc63681121c45341a7ca0f540840193ddabaefef290df │
│ /bin/chown │ │ 00755 │ 0 │ 0 │ file │ 72672 │ 4c1443e2a61a953804a462801021e8b8c6314138371963e2959209dda486c46e │
...
AnchoreCTL will output a subset of fields from the content view, for example for files on the file name and size are displayed. To retrieve the full output the --json parameter should be passed.
For example:
anchorectl -o json image content library/nginx:latest -t files
✔ Fetched content [0 packages] [6099 files] library/nginx:latest
{
"files": [
{
"filename": "/bin",
"gid": 0,
"linkdest": null,
"mode": "00755",
"sha256": null,
"size": 0,
"type": "dir",
"uid": 0
},
...
Next Steps
1.1.2 - Viewing Security Vulnerabilities
Introduction
The image vulnerabilities command can be used to return a list of vulnerabilities found in the container image.
anchorectl image vulnerabilities INPUT_IMAGE -t VULN_TYPE
The INPUT_IMAGE can be specified in one of the following formats:
- Image Digest
- Image ID
- registry/repo:tag
The VULN_TYPE currently supports:
- os: Vulnerabilities against operating system packages (RPM, DPKG, APK, etc.)
- non-os: Vulnerabilities against language packages (NPM, GEM, Java Archive (jar, war, ear), Python PIP, .NET NuGet, etc.)
- all: Combination report containing both ‘os’ and ’non-os’ vulnerability records.
The system has been designed to incorporate 3rd party feeds for other vulnerabilites.
Examples
To generate a report of OS package (RPM/DEB/APK) vulnerabilities found in the image including CVE identifier, Vulnerable Package, Severity Level, Vulnerability details and version of fixed package (if available).
anchorectl image vulnerabilities debian:latest -t os
Currently the following the system draws vulnerability data specifically matched to the following OS distros:
- Alpine
- CentOS
- Debian
- Oracle Linux
- Red Hat Enterprise Linux
- Red Hat Universal Base Image (UBI)
- Ubuntu
- Suse Linux
- Amazon Linux 2
- Google Distroless
To generate a report of language package (NPM/GEM/Java/Python) vulnerabilities, the system draws vulnerability data from the NVD data feed, and vulnerability reports can be viewed using the ’non-os’ vulnerability type:
anchorectl image vulnerabilities node:latest -t non-os
To generate a list of all vulnerabilities that can be found, regardless of whether they are against an OS or non-OS package type, the ‘all’ vulnerability type can be used:
anchorectl image vulnerabilities node:latest -t all
Finally, for any of the above queries, these commands (and other anchorectl commands) can be passed the -o json flag to output the data in JSON format:
anchorectl -o json image vulnerabilities node:latest -t all
Other options can be reviewed by issuing anchorectl image vulnerabilities --help at any time.
Next Steps
- Subscribe to receive notifications when the image is updated, when the policy status changes or when new vulnerabilities are detected.
1.2 - Image Analysis via UI
Overview
In this section you will learn how to submit images for analysis using the user
interface, and how to execute a bulk removal of pending items or
previously-analyzed items from within a repository group.
Note: Only administrators and standard users with the requisite role-based access control permissions are allowed to submit items for analysis, or remove previously analyzed assets.
Getting Started
From within an authenticated session, click the Images menu item found in the left menu:
You will be presented with the Image Analysis view. On the right-hand side
of this view you will see the Analyze Repository and Analyze Tag buttons:

These controls allow you to add entire repositories or individual items to
the Anchore analysis queue, and to also provide details about how you would like
the analysis of these submissions to be handled on an ongoing basis. Both
options are described below in the following sections.
Analyze a Repository
After clicking the Analyze Repository button, you are presented with the
following dialog:

The following fields are required:
- Registry—for example:
docker.io - Repository—for example:
library/centos
Provided below these fields is the Watch Tags in Repository configuration
toggle. By default, when One-Time Tag Analysis is selected all tags
currently present in the repository will be analyzed; once initial analysis is
complete the repository will not be watched for future additions.
Setting the toggle to Automatically Check for Updates to Tags specifies that
the repository will be monitored for any new tag additions that take place
after the initial analysis is complete. Note that you are also able to set
this option for any submitted repository from within the Image Analysis
view.
Once you have populated the required fields and click OK, you will be
notified of the overhead of submitting this repository by way of a count that
shows the maximum number of tags detected within that repository that will be
analyzed:

You can either click Cancel to abandon the repository analysis request at
this point, or click OK to proceed, whereupon the specified repository will
be flagged for analysis.
Max image size configuration applies to repositories added via UI. See max image size
Analyze a Tag
After clicking the Analyze Tag button, you are presented with the
following dialog:

The following fields are required:
- Registry—for example,
docker.io - Repository—for example,
library/centos - Tag—for example,
latest
Note: Depending upon where the dialog was invoked, the above fields may be pre-populated. For example, if you clicked the Analyze Tag button while looking at a view under Image Analysis that describes a previously-analyzed repository, the name of that repository and its associated registry will be displayed in those fields.
Some additional options are provided on the right-hand side of the dialog:
Watch Tag—enabling this toggle specifies that the tag should be
monitored for image updates on an ongoing basis after the initial analysis
Force Reanalysis—if the specified tag has already been analyzed, you can
force re-analysis by enabling this option. You may want to force re-analysis if
you decide to add annotations (see below) after the initial analysis. This
option is ignored if the tag has not yet been analyzed.
Add Annotation—annotations are optional key-pair values that can be
added to the image metadata. They are visible within the Overview tab of
the Image Analysis view once the image has been analyzed, as well as from
within the payload of any webhook notification from Anchore that contains image
information.
Also note that there is a section here for you to upload Dockerfiles. When you provide the Dockerfile for an image here, if the image has already been analyzed before - you will need to make sure the ‘Force Reanalysis’ box is ticked. Once the Dockerfile is added, you can find and view it in the Build Summary of the image.
Once you have populated the required fields and click OK, the specified tag
will be scheduled for analysis.
Max image size configuration applies to images added via UI. See max image size
Note: Anchore will attempt to download images from any registry without requiring further configuration. However, if your registry needs authentication then the corresponding credentials will need to be defined. See Configuring Registries for more information.
View and download Vulnerability
To view the vulnerability details, follow these steps:
- Click on the image icon.
- Under the Repository column, click the hyperlink of the repository where the desired image is located.

- You will then see all the images in the selected repository. Under the Most Recently Analyzed Image Digest column, click on the image digest for which you want to view or download the vulnerabilities.

This takes you to the Policy compliance page.
- On this page click on Vulnerabilities

- After clicking the vulnerabilities icon, you will see a list of vulnerabilities for that image. To download the vulnerabilities, click on the Vulnerability Report icon and choose either the JSON or CSV format.
Repository Deletion
Shown below is an example of a repository view under Image Analysis:

From a repository view you can carry out actions relating to the bulk removal of
items in that repository. The Analysis Cancellation / Repository Removal
control is provided in this view, adjacent to the analysis controls:

After clicking this button you are presented with the following options:
Cancel Images Currently Pending Analysis—this option is only enabled if
you have one or more tags in the repository view that are currently scheduled
for analysis. When invoked, all pending items will be removed from the queue.
This option is particularly useful if you have selected a repository for
analysis that contains many tags, and the overall analysis operation is
taking longer than initially expected.
Note: If there is at least one item present in the repository that is
not pending analysis, you will be offered the opportunity to decide if you
want the repository to be watched after this operation is complete.
Remove Repository and Analyzed Items—In order to remove a repository from
the repository view in its entirety, all items currently present within the
repository must first be removed from Anchore. When invoked, all items (in any
state of analysis) will be removed. If the repository is being watched, this
subscription is also removed.
2 - Vulnerability Annotations and VEX
Vulnerability Annotations & VEX
Anchore Enterprise lets you annotate vulnerabilities reported for container images to provide details regarding the
true-positive or false-positive state of the vulnerability for the customer’s product.
Roles and Permissions
The ability to manage vulnerability annotation data is reserved for certain users, typically on
the application security team. This capability is protected via a new RBAC role vuln-annotator-editor, which includes
the permissions to create, edit, and delete vulnerability annotation data.
Users which have been conveyed an RBAC role that contains the ability to listImages (i.e. read-only), are also able
to view the vulnerability annotation data and generate VDR (Vulnerability Disclosure Report) and VEX (Vulnerability
Exploitability eXchange) data exports.
Applying Annotations
Vulnerability annotations can be applied by any user with the vuln-annotator-editor role via the UI or API. Vulnerability annotations consist of the Annotation Status value and, optionally, the rest of the fields that make up a complete Vulnerability Exploit Statement.
- Status
Not affected: No remediation or mitigation is required. The vulnerability does not affect the listed products.Affected: Actions are recommended by the author to remediate, mitigate, or otherwise address the vulnerability. The vulnerability affects the listed products.Fixed: The listed products contain fixes for the vulnerability.Under Investigation: The author of the VEX statement or other relevant parties are investigating and have not yet declared a final status. Expectation is that this will eventually be updated to one of the above status values.
- Status Notes: explain the status value with additional details.
- Justification
Component is Not Present: The vulnerable component is not included in the product.Vulnerable Code is Not Present: The vulnerable component is included in the product, but the vulnerable code is not present. Typically, this case occurs when source code is configured or built in a way that excludes the vulnerable code.Vulnerable Code Not in Execute Path: The vulnerable code (likely in the component) cannot be executed due to the way it is used by the product. Typically, this case occurs when the product includes the vulnerable code but does not call or otherwise use it.Vulnerable Code Cannot be Controlled by Adversary: The vulnerable code is present and used by the product, but cannot be controlled by an attacker to exploit the vulnerability.Inline Mitigation Already Exists: The product includes built-in protections or features that prevent exploitation of the vulnerability. These built-in protections cannot be subverted by the attacker and cannot be configured or disabled by the user. These mitigations completely prevent exploitation based on known attack vectors.Fix Not Planned: The vulnerability impacts the component, but there are no plans to fix it. Refer to the impact and/or action statement for more details.
- Impact Statement: Explain the status value if the justification is not provided.
- Action Statement: Explain what steps will be taken to remediate this true-positive vulnerability.
- Analysis First Issued: When the exploitability statement was initially issued.
- Analysis Last Updated: When the exploitability statement was last updated.
- Additional Details: Any additional information regarding the exploitability statement.
Impact on Vulnerability Filters and Display
Once a vulnerability is annotated with a status of Not Affected or Fixed, it will be removed from both the Total
Vulnerabilities count and the data grid. The filters can always be adjusted to display all vulnerabilities, regardless
of their annotation status.
Policy Gate
There are two parameters available for the vulnerabilities gate and package trigger for Container Image Rule Sets:
missing annotation: If set to True, only show vulnerabilities that are not annotated.annotation status: Comma-separated list of annotation statuses to filter vulnerabilities.
Reports
There are two filter parameters available for reports that include vulnerability contents:
Missing Annotation: If set to True, only include vulnerabilities that are not annotated.Annotation Status: List of vulnerability annotation statuses to filter by.
Generating a VEX Document for a Container Image
The vulnerability annotations can be used to generate a VEX (Vulnerability Exploitability eXchange) document to share
the security analysis state with various stakeholders.
This VEX document can be downloaded via the UI or API in multiple formats, including OpenVEX and CycloneDX.
- VEX document in the OpenVEX format can be generated for a container image using the API endpoint
GET /v2/images/{image_digest}/vex/openvex
- VEX document in the CycloneDX XML and JSON formats can be generated for a container image using the API endpoints
GET /v2/images/{image_digest}/vex/cyclonedx-xmlGET /v2/images/{image_digest}/vex/cyclonedx-json
3 - Scanning Repositories
Introduction
Individual images can be added to Anchore Enterprise using the image add command. This may be performed by a CI/CD plugin such as Jenkins or manually by a user with the UI, AnchoreCTL or API.
Anchore Enterprise can also be configured to scan repositories and automatically add any tags found in the repository.
This is referred to as a Repository Subscription. Once added, Anchore Enterprise will periodically check the
repository for new tags and add them to Anchore Enterprise. For more details on the Repository Subscription, please see
Subscriptions
Note When you add a registry to Anchore, no images are pulled automatically. This is to prevent your Anchore deployment from being overwhelmed by a very large number of images.
Therefore, you should think of adding a registry as a preparatory step that allows you to then add specific repositories or tags without having to provide the access credentials for each.
Because a repository typically includes a manageable number of images, when you add a repository to Anchore images, all tags in that repository are automatically pulled and analyzed by Anchore.
For more information about managing registries, see Managing Registries.
Adding Repositories
The repo add command instructs Anchore Enterprise to add the specified repository watch list.
anchorectl repo add docker.io/alpine
✔ Added repo
┌──────────────────┬─────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────┼─────────────┼────────┤
│ docker.io/alpine │ repo_update │ true │
└──────────────────┴─────────────┴────────┘
Once added, Anchore Enterprise will identify the list of tags within the repository and add them to the catalog to be analyzed.
There is an option to exclude existing tags from being added to the system. This is useful when you want to watch for
and add only new tags to the system without adding tags that are already present. To do this, use the --exclude-existing-tags option.
Also by default Anchore Enterprise will automatically add the discovered tags to the list of subscribed tags
( see Working with Subscriptions ). However, this
behavior can be overridden by passing the --auto-subscribe=<true|false> option.
Listing Repositories
The repo list command will show the repositories monitored by Anchore Enterprise.
anchorectl repo list
✔ Fetched repos
┌─────────────────────────┬─────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├─────────────────────────┼─────────────┼────────┤
│ docker.io/alpine │ repo_update │ true │
│ docker.io/elasticsearch │ repo_update │ true │
└─────────────────────────┴─────────────┴────────┘
Deleting Repositories
The del option can be used to instruct Anchore Enterprise to remove the repository from the watch list. Once the repository record has been deleted no further changes to the repository will be detected by Anchore Enterprise.
Note: No existing image data will be removed from Anchore Enterprise.
anchorectl repo del docker.io/alpine
✔ Deleted repo
No results
Unwatching Repositories
When a repository is added, Anchore Enterprise will monitor the repository for new and updated tags. This behavior can be disabled preventing Anchore Enterprise from monitoring the repository for changes.
In this case the repo list command will show false in the Watched column for this registry.
anchorectl repo unwatch docker.io/alpine
✔ Unwatch repo
┌──────────────────┬─────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────┼─────────────┼────────┤
│ docker.io/alpine │ repo_update │ false │
└──────────────────┴─────────────┴────────┘
Watching Repositories
The repo watch command instructs Anchore Enterprise to monitor a repository for new and updated tags. By default repositories added to Anchore Enterprise are automatically watched. This option is only required if a repository has been manually unwatched.
anchorectl repo watch docker.io/alpine
✔ Watch repo
┌──────────────────┬─────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────┼─────────────┼────────┤
│ docker.io/alpine │ repo_update │ true │
└──────────────────┴─────────────┴────────┘
As of v3.0, Anchore Enterprise can be configured to have a size limit for images being added for analysis. This feature applies to the repo watcher. Images that exceed the max configured size in the repo being watched will not be added and a message will be logged in the catalog service. This feature is disabled by default so see scanning configuration for additional details on the functionality of this feature and instructions on how to configure the limit
Removing a Repository and All Images
There may be a time when you wish to stop a repository analysis when the analysis is running (e.g., accidentally watching an image with a large number of tags). There are several steps in the process which are outlined below. We will use docker.io/library/alpine as an example.
Note: Be careful when deleting images. In this flow, Anchore deletes the image, not just the repository/tag combo. Because of this, deletes may impact more than the expected repository since an image may have tags in multiple repositories or even registries.
Check the State
Take a look at the repository list.
anchorectl repo list
✔ Fetched repos
┌──────────────────┬─────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────┼─────────────┼────────┤
│ docker.io/alpine │ repo_update │ true │
└──────────────────┴─────────────┴────────┘
Also look at the image list.
anchorectl image list | grep docker.io/alpine
✔ Fetched images
│ docker.io/alpine:20220328 │ sha256:c11c38f8002da63722adb5111241f5e3c2bfe4e54c0e8f0fb7b5be15c2ddca5f │ not_analyzed │ active │
│ docker.io/alpine:3.16.0 │ sha256:4ff3ca91275773af45cb4b0834e12b7eb47d1c18f770a0b151381cd227f4c253 │ not_analyzed │ active │
│ docker.io/alpine:20220316 │ sha256:57031e1a3b381fba5a09d5c338f7dbeeed2260ad5100c66b2192ab521ae27fc1 │ not_analyzed │ active │
│ docker.io/alpine:3.14.5 │ sha256:aee6c86e12b609732a30526ddfa8194e4a54dc5514c463e4c2e41f5a89a0b67a │ not_analyzed │ active │
│ docker.io/alpine:3.15.5 │ sha256:26284c09912acfc5497b462c5da8a2cd14e01b4f3ffa876596f5289dd8eab7f2 │ not_analyzed │ active │
...
...
Removing the Repository from the Watched List
Unwatch docker.io/library/alpine to prevent future automatic updates.
anchorectl repo unwatch docker.io/alpine
✔ Unwatch repo
┌──────────────────┬─────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────┼─────────────┼────────┤
│ docker.io/alpine │ repo_update │ false │
└──────────────────┴─────────────┴────────┘
Delete the Repository
Delete the repository. This may need to be done a couple times if the repository still shows in the repository list.
anchorectl repo delete docker.io/alpine
✔ Deleted repo
No results
Forcefully Delete the Images
Delete the analysis/images. This may need to be done several times to remove all images depending on how many there are.
# for i in `anchorectl -q image list | grep docker.io/alpine | awk '{print $2}'`
> do
> anchorectl image delete ${i} --force
> done
┌─────────────────────────────────────────────────────────────────────────┬──────────┐
│ DIGEST │ STATUS │
├─────────────────────────────────────────────────────────────────────────┼──────────┤
│ sha256:c11c38f8002da63722adb5111241f5e3c2bfe4e54c0e8f0fb7b5be15c2ddca5f │ deleting │
└─────────────────────────────────────────────────────────────────────────┴──────────┘
┌─────────────────────────────────────────────────────────────────────────┬──────────┐
│ DIGEST │ STATUS │
├─────────────────────────────────────────────────────────────────────────┼──────────┤
│ sha256:4ff3ca91275773af45cb4b0834e12b7eb47d1c18f770a0b151381cd227f4c253 │ deleting │
└─────────────────────────────────────────────────────────────────────────┴──────────┘
...
...
...
Verify the Repository and All Images are Deleted
Check the repository list.
anchorectl repo list
✔ Fetched repos
┌─────┬──────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├─────┼──────┼────────┤
└─────┴──────┴────────┘
Check the image list.
anchorectl image list | grep docker.io/alpine
✔ Fetched images
<no output>
Next Steps
4 - Runtime Inventory
Anchore Enterprise allows you to navigate through your Kubernetes clusters to quickly and easy asses your vulnerabilities, apply policies, and take action on them. You’ll need to configure your clusters for collection before being able to take advantage of these features. See our installation instructions to get setup.
Watching Clusters and Namespaces
Users can opt to automatically scan all the images that are deployed to a specific cluster or namespace. This is helpful to monitor
your overall security posture in your runtime and enforce policies. Before opting to subscribe to a new cluster, it’s important to ensure you have proper credentials saved in Anchore to pull the images from the registry. Also watching a new cluster can create a considerable queue of images to work through and impact other users of your Anchore Enterprise deployment.
Using Charts Filters
The charts at the top of the UI provide key contextual information about your runtime. Upon landing on the page you’ll see a summary of your policy evaluations and vulnerabilities for all your clusters. Drilling down into a cluster or namespace will update these charts to represent the data for the selected cluster and/or namespace. Additionally, users can select to only view clusters or namespaces with the selected filters. For example selecting only high and critical vulnerabilities will only show the clusters and/or namespaces that have those vulnerabilities.
Using Views
In addition to navigating your runtime inventory by clusters and namespaces, users can opt to view the images or vulnerabilities across. This is a great way to identify vulnerabilities across your runtime and asses their impact.
Assessing impact
Another important aspect of the Kubernetes Inventory UI is the ability to assess how a vulnerability in a container images impacts your environment. For every container when you see a note about it usage being seen in particular cluster and X more… you will be able to mouse over the link for a detailed list of where else that container image is being used. This is fast way to determine the “blast-radius” of a vulnerability.
Data Delays
Due to the processing required to generate the data used by the Kubernetes Inventory UI, the results displayed may not be fully up to date. The overall delay depends on the configuration of how often inventory data is collected, and how frequently your reporting data is refreshed. This is similar to delays present on the dashboard.
Policy and Account Considerations
The Kubernetes Inventory is only available for an account’s default policy. You may want to consider setting up an account specifically for tracking your Kubernetes Inventory and enforcing a policy.
5 - Working with Subscriptions
Introduction
Anchore Enterprise supports 7 types of subscriptions.
- Tag Update
- Policy Update
- Vulnerability Update
- Analysis Update
- Alerts
- Repository Update
- Runtime Inventory
For detail information about Subscriptions please see Subscriptions
Managing Subscriptions
Subscriptions can be managed using AnchoreCTL.
Listing Subscriptions
Running the subscription list command will output a table showing the type and status of each subscription.
anchorectl subscription list | more
✔ Fetched subscriptions
┌──────────────────────────────────────────────────────────────────────┬─────────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────────────────────────────────────────────────────────┼─────────────────┼────────┤
│ docker.io/alpine:latest │ policy_eval │ false │
│ docker.io/alpine:3.12.4 │ policy_eval │ false │
│ docker.io/alpine:latest │ vuln_update │ false │
│ docker.io/redis:latest │ policy_eval │ false │
│ docker.io/centos:8 │ policy_eval │ false │
│ docker.io/alpine:3.8.4 │ policy_eval │ false │
│ docker.io/centos:8 │ vuln_update │ false │
...
└──────────────────────────────────────────────────────────────────────┴─────────────────┴────────┘
Note: Tag Subscriptions are tied to registry/repo:tag and not to image IDs.
Activating Subscriptions
The subscription activate command is used to enable a subscription type for a given image. The command takes the following form:
anchorectl subscription activate SUBSCRIPTION_KEY SUBSCRIPTION_TYPE
SUBSCRIPTION_TYPE should be either:
- tag_update
- vuln_update
- policy_eval
- analysis_update
SUBSCRIPTION_KEY should be the name of the subscribed tag. eg. docker.io/ubuntu:latest
For example:
anchorectl subscription activate docker.io/ubuntu:latest tag_update
✔ Activate subscription
Key: docker.io/ubuntu:latest
Type: tag_update
Id: 04f0e6d230d3e297acdc91ed9944278d
Active: true
and to de-activate:
anchorectl subscription deactivate docker.io/ubuntu:latest tag_update
✔ Deactivate subscription
Key: docker.io/ubuntu:latest
Type: tag_update
Id: 04f0e6d230d3e297acdc91ed9944278d
Active: false
Tag Update Subscription
Any new tag added to Anchore Enterprise by AnchoreCTL will, by default, enable the Tag Update Subscription.
If you do to need this functionality, you can use the flag --no-auto-subscribe or set the environment variable ANCHORECTL_IMAGE_NO_AUTO_SUBSCRIBE when adding new tags.
./anchorectl image add docker.io/ubuntu:latest --no-auto-subscribe
Runtime Inventory Subscription
AnchoreCTL provides commands to help navigate the runtime_inventory Subscription. The subscription will monitor a specify runtime inventory context and add its images to the system for analysis.
Listing Inventory Watchers
# ./anchorectl inventory watch list
✔ Fetched watches
┌──────────────────────────┬───────────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────────────┼───────────────────┼────────┤
│ cluster-one/my-namespace │ runtime_inventory │ false │
└──────────────────────────┴───────────────────┴────────┘
Activating an Inventory Watcher
Note: This command will create the subscription is one does not already exist.
# ./anchorectl inventory watch activate cluster-one/my-namespace
✔ Activate watch
┌──────────────────────────┬───────────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────────────┼───────────────────┼────────┤
│ cluster-one/my-namespace │ runtime_inventory │ true │
└──────────────────────────┴───────────────────┴────────┘
Deactivating an Inventory Watcher
# ./anchorectl inventory watch deactivate cluster-one/my-namespace
✔ Deactivate watch
┌──────────────────────────┬───────────────────┬────────┐
│ KEY │ TYPE │ ACTIVE │
├──────────────────────────┼───────────────────┼────────┤
│ cluster-one/my-namespace │ runtime_inventory │ false │
└──────────────────────────┴───────────────────┴────────┘
6 - Reporting & Remediation
Once you have identified vulnerabilities against software in a container image, the next step is to remediation. This section covers typical usage patterns for reporting on vulnerabilities and running possible workflows for remediation.
Matching
On occasion, you may see a vulnerability identified by GHSA (GitHub Security Advisory) instead of CVE (Common Vulnerability Enumeration). The reason for this is that Anchore uses an order of precedence to match vulnerabilities from feeds. Anchore gives precedence to OS and third-party package feeds which often contain more up-to-date information and provide more accurate matches with image content. However, these feeds may provide GHSA vulnerability IDs instead of CVEs as provided by NVD (National Vulnerability Database) feeds.
The vulnerability ID Anchore reports depends on how the vulnerability is matched. The order of precedence is packages installed by OS package managers, then third-party packages (java, python, node), and then NVD. The GHSA feeds tend to be ahead of the NVD feeds, so there may be some vulnerabilities that match a GHSA before they match a CVE from NVD.
We are working to unify the presentation of vulnerability IDs to keep things more consistent. Currently our default is to report the CVE unless the GHSA provides a more accurate match.
Reporting
The Reports tab is your gateway to producing insights into the collective status of your container image environment based on the back-end Enterprise Reporting Service.
Note: Because the reporting data cycle is configurable, the results shown in this view may not precisely reflect actual analysis output at any given time.
For more information on how to modify this cycle or the Reporting Service in general, please refer to the Reporting Service documentation.
Custom Reports
The Report feature provides the tools to create custom reports, set a report to run on a schedule (or store the report for future use), and get notified when they’re executed in order to receive the insights you’re interested in for account-wide artifacts.
In addition, you can create user templates (also known as custom templates) that use any of the preconfigured system templates offered with the application as their basis, or create your own templates from scratch. Templates provide the structure and filter definitions the application uses in order to generate reports.
To jump to a particular guide, select from the following below:
6.1 - New Reports
Overview
The New Reports tab in the Reports view is where you can create a new report, either on
an ad-hoc basis for immediate download, or for it to be saved for future use. Saved
reports can be executed immediately, scheduled, or both.
Note: The New Reports tab will be the default tab selected in the Reports view when you don’t yet have any saved reports.
Reports created in this view are based on templates. Templates provide the output structure and filter definitions the user can configure in order for the application to generate the shape of the report. Anchore Enterprise client provides immediate access to a number of preconfigured system templates that can be used as the basis for user templates. For more information on how to create and manage templates, please refer to the Templates documentation.
Creating a Report
The initial view of the New Reports tab is shown below:

In the above view you can see that the application is inviting you to select a template
from the dropdown menu. You can either select an item from this dropdown or click in the field itself and enter text in order to filter the list.
Once a template is selected, the view will change to show the available filters for the selected template. The following screenshot shows the view after selecting the Artifacts by Vulnerability template:

At this point you can click Preview Report to see the summary output and download the information, or you can refine the report by adding filters from the associated dropdown. As with the template selection, you can either select an item from the dropdown or click in the field itself and enter text in order to filter the list.

After you click the Preview Report button, you are presented with the summary output and the ability to download the report in a variety of formats:

At this point you can click any of the filters you applied in order to adjust them (or remove them entirely). The results will update automatically. If you want to add more filters you can click the [ Edit ] button and select more items from the available options and then click Preview Report again to see the updated results.
You can now optionally configure the output information by clicking the [ Configure Columns ] button. The resulting popup allows you to reorder and rename the columns, as well as remove columns you don’t want to see in the output or add columns that are not present by default:

Once you’re satisfied with the output, click Download Full Report to download the report in the selected format. The formats provided are:
- CSV - comma-separated values, with all nested objects flattened into a linear list of items
- Flat JSON - JavaScript object notation, with all nested objects flattened into a linear list of items
- Raw JSON - JavaScript object notation, with all nested objects preserved
Saving a Report
The above describes the generation of an ad-hoc report for download, which may
be all you need. However, you can also save the report for future use. To do so, click the Save Report button. The following popup will appear:

Provide a name and optional description for the report, and then select
whether you want to save the report and store results immediately, set it to run on a schedule, or both. If you select the Generate Report option, you can then select the frequency of the report generation. Once you’re satisfied with the configuration, click Save.
The saved report will be stored under Saved Reports and you will immediately be transitioned to this view on success. The features within this
view are described in the Saved Reports section.
6.2 - Quick Report
Overview
Generate a report utilizing the back-end Enterprise Reporting Service through a variety of formats - table, JSON, and CSV. If you’re interested in refining your results, we recommend using the plethora of optional filters provided.
Note: Because the reporting data cycle is configurable, the results shown in this view may not precisely reflect actual analysis output at any given time.
For more information on how to modify this cycle or the Reporting Service in general, please refer to the Reporting Service documentation.
The following sections in this document describe how to select a query, add optional filters, and generate a report.
Reports

Selecting a Query
To select a query, click the available dropdown present in the view and select the type of report you’re interested in generating.

Images Affected by Vulnerability
View a list of images and their various artifacts that are affected by a vulnerability. By default, a couple optional filters are provided:
| Filter | Description |
|---|
| Vulnerability Id | Vulnerability ID |
| Tag Current Only | If set to true, current tag mappings are evaluated. Otherwise, all historic tag mappings are evaluated |
Policy Compliance History by Tag
Query your policy evaluation data using this report type. By default, this report was crafted with compliance history in mind. Quite a few optional filters are provided to include historic tag mappings and historic policy evaluations from any policy that is or was set to active. More info below:
| Filter | Description |
|---|
| Registry Name | Name of the registry |
| Repository Name | Name of the repository |
| Tag Name | Name of the tag |
| Tag Current Only | If set to true, current tag mappings are evaluated. Otherwise, all historic tag mappings are evaluated |
| Policy Evaluation Latest Only | If set to true, only the most recent policy evaluation is processed. Otherwise, all historic policy evaluations are evaluated |
| Policy Active | If set to true, only the active policy at the time of this query is used. Otherwise, all historically active policies are also included. This attribute is ignored if a policy ID or digest is specified in the filter |
Note that the default filters provided are optional.
Adding Optional Filters
Once a report type has been selected, an Optional Filters dropdown becomes available with items specific to that Query. Such as those listed above, any filters considered default to that report type are also shown.

You can remove any filters you don’t need by pressing the in their top right corner but as long as they’re empty/unset, they will be ignored at the time of report generation.
Generating a Report
After a report type has been selected, you immediately can Generate Report by clicking the button shown in the bottom left of the view.

By default, the Table format is selected but you can click the dropdown and modify the format for your report by selecting either JSON or CSV.
Table
A fast and easy way to browse your data, the table report retrieves paginated results and provides optional sorting by clicking on any column header. Each column is also resizable for your convenience. You can choose to fetch more or fetch all items although please note that depending on the size of your data, fetching all items may take a while.
Download Options
Download your report in JSON or CSV format. Various metadata such as the report type, any filters used when querying, and the timestamp of the report are included with your results. Please note that depending on the size of your data, the download may take a while.
6.3 - Report Manager
Overview
Use the Report Manager view to create custom queries, set a report to run on a schedule (or store the configuration for future use), and get notified when they’re executed in order to receive the insights you’re interested in for account-wide artifacts. The results are provided through a variety of formats - tabular, JSON, or CSV - and rely on data retrieved from the back-end Enterprise Reporting Service.
Note: Because the reporting data cycle is configurable, the results shown in this view may not precisely reflect actual analysis output at any given time.
For more information on how to modify this cycle or the Reporting Service in general, please refer to the Reporting Service documentation.
The following sections in this document describe templates, queries, scheduling reports, and viewing your results.
Report Manager

Templates
Templates define the filters and table field columns used by queries to generate report output. The templates provided by the sytem or stored by other users in your account can be used directly to create a new query or as the basis for crafting new templates.
System Templates
By default, the UI provides a set of system templates:
- Images Failing Policy Evaluation
- This template contains a customized set of filters and fields, and is based on “Policy Compliance History by Tag”.
- Images With Critical Vulnerabilities
- This template contains a customized set of filters and fields, and is based on “Images Affected by Vulnerability”.
- Artifacts by Vulnerability
- This templates contains all filters and fields by default.
- Tags by Vulnerability
- This templates contains all filters and fields by default.
- Images Affected by Vulnerability
- This templates contains all filters and fields by default.
- Policy Compliance History by Tag
- This templates contains all filters and fields by default.
- Vulnerabilities by Kubernetes Namespace
- This templates contains all filters and fields by default.
- Vulnerabilities by Kubernetes Container
- This templates contains all filters and fields by default.
- Vulnerabilities by ECS Container
- This templates contains all filters and fields by default.
Creating a Template
In order to define a template’s list of fields and filters, navigate to the Create a New Template section of the page, select a base configuration provided by the various System Templates listed above, and click Next to open a modal.

Provide a name for your new template, add an optional description, and modify any fields or filters to your liking.
The fields you choose control what data is shown in your results and are displayed from left to right within a report table. To optionally refine the result set returned, you can add or remove filter options, set a default value for each entry and specify if the filter is optional or required.
Note that templates must contain at least one field and one filter.
Once the template is configured to your satisfaction, click OK to save it as a Stored Template. Your new template is now available to hydrate a query or as a basis for future templates.
Editing a Template
To view or edit a template that has been stored previously, click its name under Stored Report Items on the right of the page. As with the creation of a template, the list of fields and filters can be customized to your preference.
When you’re done, click OK to save any new changes or Cancel to discard them.
Deleting a Template
To delete a template that you have configured previously, click the red “x” to the left of its name under Stored Report Items and click Yes to remove it. Note that once the template has been removed, you won’t be able to recover it.
Queries
Queries are based on a template’s configuration and can then be submitted to the back-end Enterprise Reporting Service on a reoccurring schedule to generate reports. These results can then be previewed in tabular form and downloaded in JSON or CSV format.
Creating a Query
To create a query, navigate to the Create a New Query section of the page, select a template configuration, and click Next to open a modal.

After you provide a unique name for the query and an optional description, click OK to save your new query. You will be automatically navigated to view it.
Editing a Query
To view or edit a query, click its name under Stored Report Items on the right of the page to be navigated to the Query View.

Within this view, you can edit its name and description, set a schedule to act as the base configuration for Scheduled Items, and view the various filters set by the template this query was based on.
To save any changes to the query, click Save Query or Save Query and Schedule Report.
Setting a Schedule
In order to set or modify a query’s schedule, click Add/Change Schedule to open a modal.

Reports can be generated daily, weekly, or monthly at a time of your choosing. This can be set according to your timezone or UTC. By default, the schedule is set for weekly on Mondays at 12PM your time.
When scheduling reports to be generated monthly, note that multiple days of the month can be selected and that certain days (the 31st, for example) may not trigger every month.
In the top-right corner of the modal, you can toggle the enabled state of the schedule which determines whether reports will be executed continuously on the timed interval you saved. Note that pressing OK modifies the schedule but does not save it to the query. Please click the Save Query or Save Query and Schedule Report to do so.
Deleting a Query
To delete a query, click the red “x” to the left of its name under Stored Report Items and click Yes to remove it. Note that every scheduled report associated with that query will also be removed and not be recoverable.
Scheduled Reports
Adding a Scheduled Item
Once you’ve crafted a query based on a system or custom template, supplied any filters to refine the results, and previewed the report generated to ensure it is to your satisfaction, you can add it to be scheduled by clicking Save Query and Schedule Report.
Any schedules created from this view will be listed at the bottom.
Editing a Scheduled Item
To edit a scheduled item, click on Tools within that entry’s Actions column and select Edit Scheduled Item to open a modal.
Here, you can modify the name, description, and schedule for that item. Click Yes to save any new changes or Cancel to discard them.
Deleting a Scheduled Item
To delete a scheduled item, click on Tools within that entry’s Actions column and select Delete Scheduled Item. Note that every report generated from that schedule will also be removed upon clicking Yes and will not be recoverable.
Viewing Results
Click View under a scheduled item’s Actions column to expand the row and view its list of associated reports sorted by most recent. Click View or Tools > View Results to navigate to that report’s results.

If you configured notifications to be sent when a report has been executed, you can navigate to the report’s results by clicking the link provided in its notification.
Downloading results
A preview of up to 1000 result items are shown in tabular form which provides optional sorting by clicking on any column header. If a report contains more than 1000 results, please download the data to view the full report. To do so, click Download to JSON or Download to CSV based on your preferred format.
Various metadata such as the report type, any filters used when querying, and the timestamp of the report are included with your results. Please note that depending on the size of your data, the download may take a while.
To be notified whenever a report has been generated, navigate to Events & Notifications > Manage Notifications. Once any previous notification configurations have loaded, add a new one from your preferred endpoint (Email, Slack, etc), and select the predefined event selector option for Scheduled Reports.

This includes the availability of a new result or any report execution failures.
Once you receive a notification, click on the link provided to automatically navigate to the UI to view the results for that report.
6.4 - Saved Reports
Overview
The Saved Reports tab in the Reports view is where you can view,
configure, download, or delete reports that have been saved for future use. Each report
entry may contain zero or more results, depending on whether the report has
been run or not.
Note: The Saved Reports tab will be the default tab selected in the
Reports view when you have one or more saved reports.
Viewing a Report
An example of the Saved Reports tab is shown below:
Clicking anywhere within the row other than on an active report title or on the
Actions button will expand it, displaying the executions for that report if
any are available. Clicking an active report title will take you to a view
displaying the latest execution for that report. An inactive report title
indicates that no results are yet available.
If a report has been scheduled but has no executions, the expanded row will look
like the following example:

Reports with one or more executions will look like the following example:

In the above example you can see a list of previously executed reports. Their
completion status is indicated by the green check mark. Reports that are still
in progress are indicated by a spinning icon. Reports that are queued for
execution are indicated by an hourglass icon. The reports shown here are all
complete, so they can be downloaded by clicking the Download Full Report button.
Incomplete, queued, or failed reports cannot be downloaded.
The initial view shows up to four reports, with any older items being viewable
by clicking the View More button. The View More button will disappear
when there are no more reports to show. In addition:
Clicking the Refresh List button will refresh the list of reports, including any executions that may have completed since the last time the list was refreshed. Clicking the Generate Now button will generate a new execution of the report.
Individual report items can be deleted by clicking the Delete button. If the
topmost report item is deleted, the link in the table row will correspond to the
next report item in the list (if any are available).
Note: Deleting all the execution entries for a report will not delete the
report itself. The report will still be available for future executions.
Each report row has a Tools control that allows you to perform the following
actions:
- Configure: Opens the report configuration popup, allowing you to change
the report name, description, and schedule
- Generate Now: Generates a new execution of the report
- Save as Template: Saves the report as a user template, allowing you to use
it as the basis for future reports
- Delete: Removes the report and any associated executions. If all reports
are deleted, the page will transition to the New Reports tab and the Saved
Reports tab will be disabled.
6.5 - Templates
Overview
The Templates tab in the Reports view is where you can view and manage
report templates. Templates provide the basis for creating the reports executed
by the system and specify which filters are applied to the retrieved dataset and
how the returned data is shaped.
A number of system templates are provided with the application and all of these
and can be used as-is, or as a starting point for creating your own user templates.
Viewing Templates
An example of the System Templates view in the Templates tab is shown
below:

In this view you can see all the system templates provided by default, and their
associated descriptions. System templates cannot be deleted, but can be copied
and modified to create your own user templates.
An alternate way of creating a new user template is by clicking the Create New
Template button. You will be presented with a dialog that allows you to
select an existing system template as your starting point, or base your
composition on any of the custom templates created by you or other users:

Selecting a template from the provided dropdown will open the Create a New
Template dialog:

Within this dialog you can provide a unique name and optional description for
the new template. In addition, you can modify the filters available when composing
reports based on this template, and the columns that will be displayed in the
resulting report:
Filters: You can add or remove filters, set
default values, and specify if the filter is optional or required. Filters are
displayed from left to right when composing a report—you can change the display
order by clicking on a row hotspot and dragging the row item up or down
the list.
Columns: You can add or remove columns, change their display
order, or provide custom column names to be used when the data is presented in
the tabular form offered by comma-separated variable (CSV) file downloads.
Columns are displayed from left to right within a report table—you can change
the display order by clicking on a row hotspot and dragging the row item up or
down the list. Note that templates must contain at least one column.
Once you have configured the filters and columns, you can specify if the report
will be scoped to return results against the analysis data in either the current selected
account or from all accounts, and click OK. The new template will be added
to the list of available user templates.
Custom Templates
The custom templates view shows all user-defined templates present in
the current selected account. An example of the Custom Templates view is shown below:
Unlike system templates, custom templates can be edited or deleted in addition
to being copied. Clicking the Tools button for a custom template will
display the following options:

Note that any changes you make to templates in this view, or any new entries you
create, will be available to all users in the current selected account.
7.1 - Hints
Anchore Enterprise includes the ability to read a user-supplied ‘hints’ file to allow users to add software artifacts to Anchore’s
analysis report. The hints file, if present, contains records that describe a software package’s characteristics explicitly,
and are then added to the software bill of materials (SBOM). For example, if the owner of a CI/CD container build process
knows that there are some
software packages installed explicitly in a container image, but Anchore’s regular analyzers fail to identify them, this mechanism
can be used to include that information in the image’s SBOM, exactly as if the packages were discovered normally.
Hints cannot be used to modify the findings of Anchore’s analyzer beyond adding new packages to the report. If a user specifies
a package in the hints file that is found by Anchore’s image analyzers, the hint is ignored and a warning message is logged
to notify the user of the conflict.
Configuration
See Configuring Content Hints
Once enabled, the analyzer services will look for a file with a specific name, location and format located within the container image - /anchore_hints.json.
The format of the file is illustrated using some examples, below.
OS Package Records
OS Packages are those that will represent packages installed using OS / Distro style package managers. Currently supported package types are rpm, dpkg, apkg
for RedHat, Debian, and Alpine flavored package managers respectively. Note that, for OS Packages, the name of the package is unique per SBOM, meaning
that only one package named ‘somepackage’ can exist in an image’s SBOM, and specifying a name in the hints file that conflicts with one with the same
name discovered by the Anchore analyzers will result in the record from the hints file taking precedence (override).
- Minimum required values for a package record in anchore_hints.json
{
"name": "musl",
"version": "1.1.20-r8",
"type": "apkg"
}
- Complete record demonstrating all of the available characteristics of a software package that can be specified
{
"name": "musl",
"version": "1.1.20",
"release": "r8",
"origin": "Timo Ter\u00e4s <[email protected]>",
"license": "MIT",
"size": "61440",
"source": "musl",
"files": ["/lib/ld-musl-x86_64.so.1", "/lib/libc.musl-x86_64.so.1", "/lib"],
"type": "apkg"
}
Non-OS/Language Package Records
Non-OS / language package records are similar in form to the OS package records, but with some extra/different characteristics being supplied, namely
the location field. Since multiple non-os packages can be installed that have the same name, the location field is particularly important as it
is used to distinguish between package records that might otherwise be identical. Valid types for non-os packages are currently java, python, gem, npm, nuget, go, binary.
For the latest types that are available, see the anchorectl image content <someimage> output, which lists available types for any given deployment of Anchore Enterprise.
- Minimum required values for a package record in anchore_hints.json
{
"name": "wicked",
"version": "0.6.1",
"type": "gem"
}
- Complete record demonstrating all of the available characteristics of a software package that can be specified
{
"name": "wicked",
"version": "0.6.1",
"location": "/app/gems/specifications/wicked-0.9.0.gemspec",
"origin": "schneems",
"license": "MIT",
"source": "http://github.com/schneems/wicked",
"files": ["README.md"],
"type": "gem"
}
Putting it all together
Using the above examples, a complete anchore_hints.json file, when discovered by Anchore Enterprise located in /anchore_hints.json inside any container image, is provided here:
{
"packages": [
{
"name": "musl",
"version": "1.1.20-r8",
"type": "apkg"
},
{
"name": "wicked",
"version": "0.6.1",
"type": "gem"
}
]
}
With such a hints file in an image based for example on alpine:latest, the resulting image content would report these two package/version records
as part of the SBOM for the analyzed image, when viewed using anchorectl image content <image> -t os and anchorectl image content <image> -t gem
to view the musl and wicked package records, respectively.
Note about using the hints file feature
The hints file feature is disabled by default, and is meant to be used in very specific circumstances where a trusted entity is entrusted with creating
and installing, or removing an anchore_hints.json file from all containers being built. It is not meant to be enabled when the container image builds
are not explicitly controlled, as the entity that is building container images could override any SBOM entry that Anchore would normally discover, which
affects the vulnerability/policy status of an image. For this reason, the feature is disabled by default and must be explicitly enabled in configuration
only if appropriate for your use case.
7.2 - Corrections
When Anchore analyzes an image, it persists a Software Bill of Materials (SBOM) which will be submitted for periodic scanning for known vulnerabilities. During the scan, various attributes will be used from the SBOM package artifacts to match to the relevant vulnerability data. Depending on the ecosystem, the most important of these package attributes tend to be Package URL (purl) and/or Common Platform Enumeration (CPE). The Anchore analyzer attempts to generate a best effort guess of the CPE candidates for a given package as well as the purl based on the metadata that is available at the time of analysis (ex. for Java packages, the manifest, which contains multiple different version specifications among other metadata), but sometimes gets this wrong.
To facilitate the necessary corrections in these instances, Anchore provides the Corrections feature. Now, a user can provide a correction that will update a given package’s metadata so that attributes (including CPEs and Package URLs) can be corrected at the time that Anchore performs a vulnerability scan.
An example follows for a very common scenario in the java maven ecosystem where the official maven groupid and artifactid are not available in the metadata and the best guess that the Anchore analyzer surfaces for package url and CPEs is not in line with the vulnerability data, so a correction can be issued to align them.
Imagine an Anchore analysis results in the following package content:
{
"cpes": [
"cpe:2.3:a:apache:catalina:9.0.88:*:*:*:*:*:*:*"
],
"implementationVersion": "9.0.88",
"licenses": [
"https://www.apache.org/licenses/LICENSE-2.0.txt"
],
"location": "/usr/local/tomcat/lib/catalina.jar",
"mavenVersion": "N/A",
"origin": "Apache Software Foundation",
"package": "catalina",
"purl": "pkg:maven/org.apache.tomcat-catalina/[email protected]",
"specificationVersion": "9.0",
"type": "JAVA-JAR",
"version": "9.0.88"
}
There are several issues with this entry. The maven groupid and artifactid within the purl, the package name, and the CPE are all not in line with what is expected for proper vulnerability matching.
Using the above example, a user can add a correction as using anchorectl or via HTTP POST to the /corrections endpoint:
{
"description": "Correct Tomcat Catalina package metadata",
"match": {
"type": "java",
"field_matches": [
{
"field_name": "package",
"field_value": "catalina"
}
]
},
"replace": [
{
"field_name": "cpes",
"field_value": "cpe:2.3:a:apache:tomcat_catalina:{version}:*:*:*:*:*:*:*"
},
{
"field_name": "purl",
"field_value": "pkg:maven/org.apache.tomcat/tomcat-catalina@{version}"
},
{
"field_name": "package",
"field_value": "tomcat-catalina"
}
],
"type": "package"
}
JSON Reference:
- description: A description of the correction being added (for note taking purposes)
- replace: a list of field name/value pairs to replace. For the “cpes” and “purl” field only, Anchore Enterprise can recognize a templated field via curly braces “{}”. Package JSON keys contained here will be replaced with their corresponding value from the package. For “cpe” if the templated field does not exist in the package, the corresponding cpe component will be replaced with
*. For “purl” if the templated field doesn’t exist the purl replacement will be aborted and the purl will remain unchanged from the original value. - type: The type of correction being added. Currently only “package” is supported
- match:
- type: The type of package to match upon. Supported values are based on the type of content available to images being analyzed (ex. java, gem, python, npm, os, go, nuget)
- field_matches: A list of name/value pairs based on which package metadata fields to match this correction upon
- The schema of the fields to match can be found by outputting the direct JSON content for the given content type:
- Ex. Java Package Metadata JSON:
{
"cpes": [
"cpe:2.3:a:*:spring-core:5.1.4.RELEASE:*:*:*:*:*:*:*",
"cpe:2.3:a:*:spring-core:5.1.4.RELEASE:*:*:*:*:java:*:*",
"cpe:2.3:a:*:spring-core:5.1.4.RELEASE:*:*:*:*:maven:*:*",
"cpe:2.3:a:spring-core:spring-core:5.1.4.RELEASE:*:*:*:*:*:*:*",
"cpe:2.3:a:spring-core:spring-core:5.1.4.RELEASE:*:*:*:*:java:*:*",
"cpe:2.3:a:spring-core:spring-core:5.1.4.RELEASE:*:*:*:*:maven:*:*"
],
"implementation-version": "5.1.4.RELEASE",
"location": "/app.jar:BOOT-INF/lib/spring-core-5.1.4.RELEASE.jar",
"maven-version": "N/A",
"origin": "N/A",
"package": "spring-core",
"purl": "pkg:maven/org.springframework/[email protected]",
"specification-version": "N/A",
"type": "JAVA-JAR"
}
Note: if a new field is specified here, it will be added to the content output when the correction is matched. See below for additional functionality around CPEs and Package URL
To add the above JSON using anchorectl the following command can be used
anchorectl correction add -i path-to-file.json
You could also achieve something similar using
anchorectl correction add \
--match package=catalina \
--type java \
--replace cpes="cpe:2.3:a:apache:tomcat_catalina:{version}:*:*:*:*:*:*:*" \
--replace purl="pkg:maven/org.apache.tomcat/tomcat-catalina@{version}" \
--replace package="tomcat-catalina" \
--description="Correct Tomcat Catalina package metadata"
Don’t forget you can list, delete and get a correction with the anchorectl
The command to retrieve a list of existing corrections is:
anchorectl correction list
The command to delete a corrections is:
anchorectl correction delete {correction_id}
# {correction_id} is the UUID of the correction you wish to delete
The command to get a correction is:
anchorectl correction get {correction_id}
# {correction_id} is the UUID of the correction you wish to get
The result of the correction can be checked using the image content command of anchorectl. For example to see our above java correction we would run
anchorectl image content -t java Image_sha256_ID -o json
We would now see the tomcat-catalina package content returned with the expected values:
{
"cpes": [
"cpe:2.3:a:apache:tomcat_catalina:9.0.88:*:*:*:*:*:*:*"
],
"implementationVersion": "9.0.88",
"licenses": [
"https://www.apache.org/licenses/LICENSE-2.0.txt"
],
"location": "/usr/local/tomcat/lib/catalina.jar",
"mavenVersion": "N/A",
"origin": "Apache Software Foundation",
"package": "tomcat-catalina",
"purl": "pkg:maven/org.apache.tomcat/[email protected]",
"specificationVersion": "9.0",
"type": "JAVA-JAR",
"version": "9.0.88"
}
Note: Don’t forget to replace the Image_sha256_ID with the image ID you’re trying to test.
Corrections may be updated and deleted via the API as well. Creation of a Correction generates a UUID that may be used to reference that Correction later.
Refer to the Enterprise Swagger spec for more details.